
Elasticsearch聚合查询
ES在对海量数据进行聚合分析的时候会损失搜索的精准度来满足实时性的需求。
Elasticsearch聚合查询总结
1. 求和、最大值、最小值、平均值
- 求和 - sum
- 最大值 - max
- 最小值 - min
- 平均值 - avg
DSL查询语句
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"indexTime": {
"from": "2021-07-09 00:00:00",
"to": "2021-07-10 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
]
}
},
"aggs": {//聚合字段
"sum_user": {//自定义字段
"sum": {//指定字段求和
"field": "userTotal"
}
},
"max_user": {
"max": {//指定字段取最大值
"field": "userTotal"
}
},
"min_user": {
"min": {//指定字段取最小值
"field": "userTotal"
}
},
"avg_user": {
"avg": {//指定字段取平均值
"field": "userTotal"
}
}
}
}查询语句返回结果。
{
"took": 31,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 290834,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"max_user": {
"value": 8.0
},
"min_user": {
"value": 8.0
},
"sum_user": {
"value": 69128.0
},
"avg_user": {
"value": 8.0
}
}
}Java API
//求和、最大值、最小值、平均值
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("sum_user").field("userTotal");
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("max_user").field("userTotal");
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("min_user").field("userTotal");
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("avg_user").field("userTotal");
//按顺序
sumAggregationBuilder.subAggregation(maxAggregationBuilder).subAggregation(minAggregationBuilder).subAggregation(avgAggregationBuilder);
//执行查询
SearchRequestBuilder searchRequestBuilder = esSearch.getSearchRequestBuilder();
searchRequestBuilder.addAggregation(sumAggregationBuilder);2. 统计函数/计数函数
stats 函数
可以获取 count、min、max、avg、sum 多个函数结果。
value_count - 计数
cardinality - 去重计数
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"terms": {
"labels.content_key": [
"/metrics",
"/api/v1/query"
]
}
}
]
}
},
"aggregations": {
"url_count": {
"terms": {
"field": "labels.content_key"
},
"aggs": {
"stats_value": {
"stats": {
"field": "values.request_io_bytes_total"
}
},
"count_value": {
"value_count": {
"field": "values.request_io_bytes_total"
}
},
"cardinality_value": {
"cardinality": {
"field": "values.request_io_bytes_total"
}
}
}
}
}
}查询语句返回结果。
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 788,
"max_score": 0,
"hits": [
]
},
"aggregations": {
"url_count": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "/metrics",
"doc_count": 702,
"cardinality_value": {
"value": 39
},
"count_value": {
"value": 702
},
"stats_value": {
"count": 702,
"min": 246,
"max": 4432,
"avg": 1123.2193732193732,
"sum": 788500
}
},
{
"key": "/api/v1/query",
"doc_count": 86,
"cardinality_value": {
"value": 41
},
"count_value": {
"value": 86
},
"stats_value": {
"count": 86,
"min": 195,
"max": 47025,
"avg": 12891.116279069767,
"sum": 1108636
}
}
]
}
}
}2. 当天每隔2小时的数据总量
比如查询昨天每两小时的数据总量。
DSL查询语句
{
"size": "0",
"query": {
"bool": {
"filter": [
{
"range": {
"indexTime": {
"from": "2021-07-09 00:00:00",
"to": "2021-07-10 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
]
}
},
"aggs": {
"countData": {//自定义字段
"date_histogram": {
"field": "indexTime",
"interval": "120m" //时间间隔,每120分钟一条数据
}
}
}
}查询语句返回结果,可以看到 doc_count 即为数据总量。
{
"took": 21,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 290834,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"groupBy": {
"buckets": [
{
"key_as_string": "2021-07-09T00:00:00.000Z",
"key": 1625788800000,
"doc_count": 23977
},
{
"key_as_string": "2021-07-09T02:00:00.000Z",
"key": 1625796000000,
"doc_count": 23948
},
{
"key_as_string": "2021-07-09T04:00:00.000Z",
"key": 1625803200000,
"doc_count": 23895
},
{
"key_as_string": "2021-07-09T06:00:00.000Z",
"key": 1625810400000,
"doc_count": 23900
}
]
}
}
}Java API
- dateHistogram - 指定聚合字段别名;
- dateHistogramInterval - 指定时间间隔;
- 两小时 -
DateHistogramInterval.hours(2) - 一天 -
DateHistogramInterval.days(1)
- 两小时 -
AggregationBuilders.dateHistogram("countData").field("indexTime")
.dateHistogramInterval(DateHistogramInterval.minutes(120));
SearchRequestBuilder searchRequestBuilder = esSearch.getSearchRequestBuilder();
searchRequestBuilder.addAggregation(dateHistogramAggregationBuilder);3. 指定间隔时间的操作
比如查询昨天每两小时的用户总量求和结果。
DSL查询语句
{
"size": "0",
"query": {
"bool": {
"filter": [
{
"range": {
"indexTime": {
"from": "2021-07-09 00:00:00",
"to": "2021-07-10 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
]
}
},
"aggs": {
"countUserTotal": {//自定义字段
"date_histogram": {
"field": "indexTime",//指定日期字段
"interval": "120m" //指定时间间隔2小时
},
"aggs": {
"max_user": {//自定义字段
"sum": {//求和
"field": "userTotal" //用户总量字段
}
}
}
}
}
}查询语句的查询结果。
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 290834,
"max_score": 0.0,
"hits": []
},
"aggregations": {
"countUserTotal": {
"buckets": [
{
"key_as_string": "2021-07-09T00:00:00.000Z",
"key": 1625788800000,
"doc_count": 23977,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T02:00:00.000Z",
"key": 1625796000000,
"doc_count": 23948,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T04:00:00.000Z",
"key": 1625803200000,
"doc_count": 23895,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T06:00:00.000Z",
"key": 1625810400000,
"doc_count": 23900,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T08:00:00.000Z",
"key": 1625817600000,
"doc_count": 24238,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T10:00:00.000Z",
"key": 1625824800000,
"doc_count": 24701,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T12:00:00.000Z",
"key": 1625832000000,
"doc_count": 24207,
"max_user": {
"value": 5760.0
}
},
{
"key_as_string": "2021-07-09T14:00:00.000Z",
"key": 1625839200000,
"doc_count": 24442,
"max_user": {
"value": 5760.0
}
}
]
}
}
}Java API
//聚合(区分时间间隔,比如每两个小时一条记录) DateHistogramAggregationBuilder dateHistogramAggregationBuilder = AggregationBuilders
.dateHistogram("max_user").field("userTotal") .dateHistogramInterval(DateHistogramInterval.hours(2)); //聚合,对应字段取平均值 AggregationBuilder avgBuilder = AggregationBuilders.sum(avgKey).field("userTotal"); //连接聚合条件 dateHistogramAggregationBuilder.subAggregation(avgBuilder); //执行查询 SearchRequestBuilder searchRequestBuilder = esSearch.getSearchRequestBuilder(); searchRequestBuilder.addAggregation(dateHistogramAggregationBuilder);4. 分组-聚合
根据某个字段分组,然后再进行聚合操作。
DSL查询语句
{
"size": 10,
"query": {
"bool": {
"must": {
"terms": {
"contentKey": [
"/baidu/request",
"/metrics"
]
}
}
}
},
"aggs": {
"url_count": {
"terms": {
"field": "contentKey"
},
"aggs": {
"5xxCount": {
"sum": {
"field": "code4xx"
}
},
"4xxCount": {
"sum": {
"field": "code5xx"
}
}
}
}
}
}查询结果
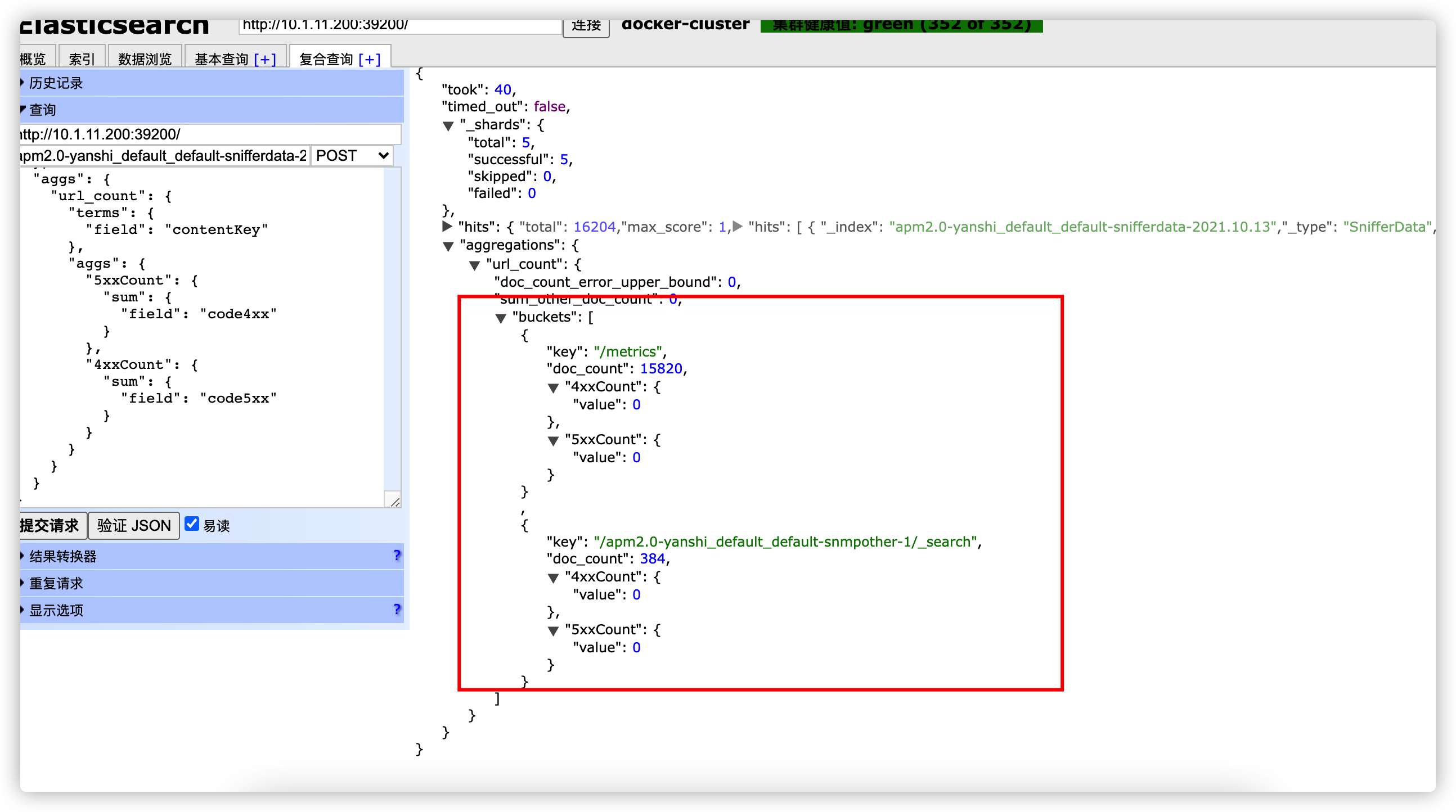
Java API
查询条件代码如下:
/**
* 封装查询条件
*/
private SearchSourceBuilder fillSourceBuilder(String masterIp, String namespace, String from, String to, List<String> urlList) {
// 过滤
BoolQueryBuilder query = QueryBuilders.boolQuery();
// 过滤指标
// query.filter(QueryBuilders.termQuery("name", Constant.METRIC_PREFIX_NPM_AGG_ENTITY_REQUEST));
query.filter(QueryBuilders.rangeQuery(TIMESTAMP).from(from).lt(to));
query.filter(QueryBuilders.termQuery("labels.masterip", masterIp));
query.filter(QueryBuilders.termQuery("labels.namespace", namespace));
//url过滤
query.filter(QueryBuilders.termsQuery(CONTENT_KEY, urlList));
//指定字段聚合
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(query).size(0);
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms(URL_COUNT).field("content_key");
termsAggregationBuilder.subAggregation(AggregationBuilders.sum(AGG_4XX).field("values.statuscode_4xx_total"))
.subAggregation(AggregationBuilders.sum(AGG_5XX).field("values.statuscode_5xx_total"));
sourceBuilder.aggregation(termsAggregationBuilder);
logger.debug("getNodeHealthCheckUrlListsourceBuilder:{}",sourceBuilder.toString());
return sourceBuilder;
}处理返回结果代码如下:
try {
SearchResponse response = ConnectEs.instance().doSearchAction(request);
if (response != null) {
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get(URL_COUNT);
for (Terms.Bucket bucket : terms.getBuckets()) {
//4.封装es返回值
healthCheckUrlListBeanList.add(fillHealthCheckUrlListBean(bucket));
}
}
} catch (Exception ex) {
logger.warn("[getNodeHealthCheckUrlList] Occurred exp, msg:{}", ex.getMessage());
ex.printStackTrace();
}
/**
* 封装es返回值
*/
private HealthCheckUrlListBean fillHealthCheckUrlListBean(Terms.Bucket bucket) {
Aggregations singleAggregations = bucket.getAggregations();
Long code4xxCount = Convert.toLong(MathUtil.decimal(((Sum) singleAggregations.get(AGG_4XX)).getValue()), 0L);
Long code5xxCount = Convert.toLong(MathUtil.decimal(((Sum) singleAggregations.get(AGG_5XX)).getValue()), 0L);
HealthCheckUrlListBean healthCheckUrlListBean = new HealthCheckUrlListBean();
healthCheckUrlListBean.setUrl(bucket.getKeyAsString());
healthCheckUrlListBean.setCode4xxCount(code4xxCount);
healthCheckUrlListBean.setCode5xxCount(code5xxCount);
healthCheckUrlListBean.setTotalCount(NumberUtil.add(code4xxCount, code5xxCount).longValue());
return healthCheckUrlListBean;
}5. 分组-聚合结果排序
查询时根据某字段聚合,然后对聚合结果进行排序。
{
"query": {
"bool": {
"must": [
{
"term": {
"monitor-item-id": "103" }
}
]
}
},
"aggs": {
"top_score": {
"terms": {
"field": "timestamp.keyword",
"size": 255, //聚合查询的总条数(不传,默认为10)
"order": [
{
"_key": "desc" //排序,根据聚合的主键进行排序
}
]
}
}
}
}返回结果如下:
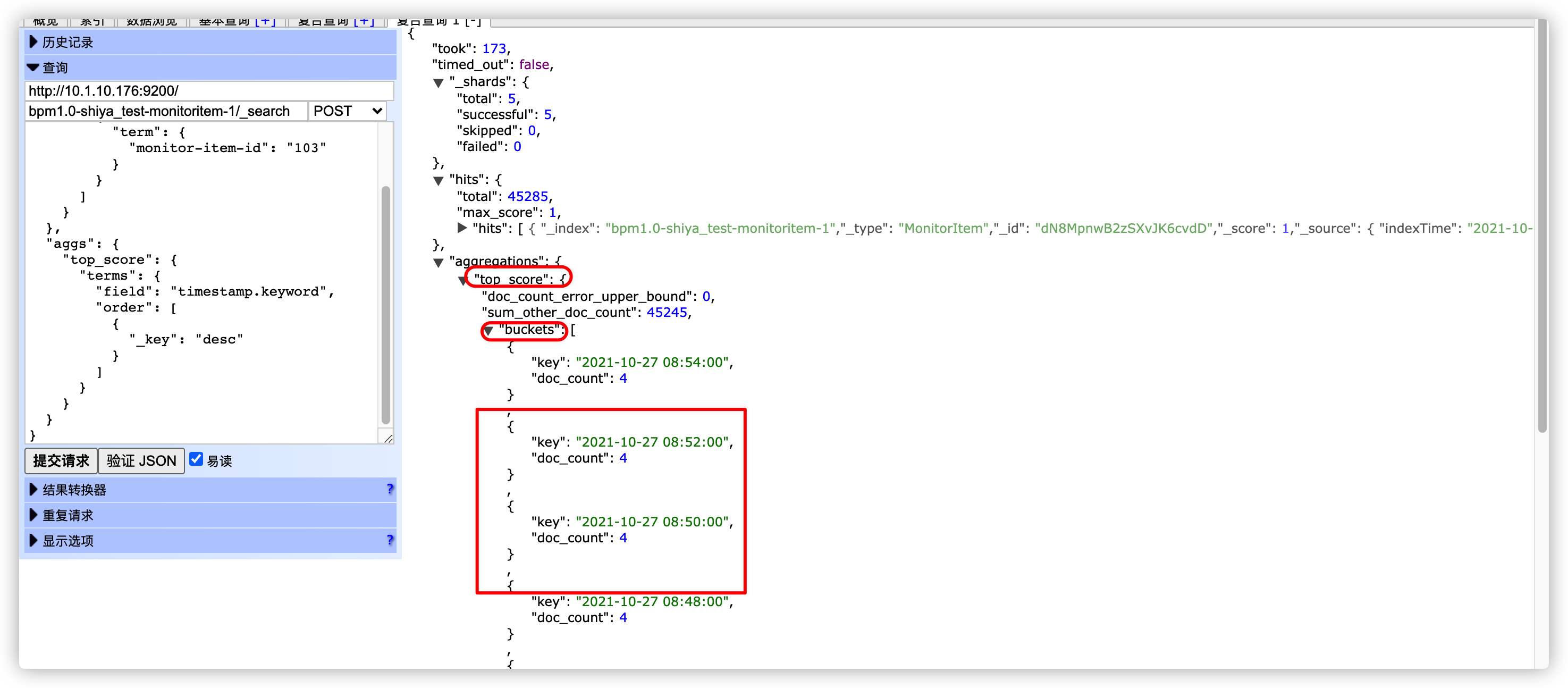
代码如下:
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders
.terms(topCient).field(AlarmMonitoringConstant.TIMESTAMP + ".keyword")
.size(from + size)
.order(BucketOrder.key(false));6. 查找聚合后分组内的数据 - top_hits
数据根据某字段聚合后,获取每个分组内的数据列表。使用的是 top_hits
{
"query": {
"bool": {
"must": [
{
"term": {
"monitor-item-id": "103" }
}
]
}
},
"aggs": {
"top_score": {
"terms": {
"field": "timestamp.keyword" },
"aggs": {
"top_score_hits": { //自定义聚合名称
"top_hits": { //top_hits函数
"_source": [ //指定返回的数据字段,不填则全部返回
]
}
}
}
}
}
}返回结果如下:
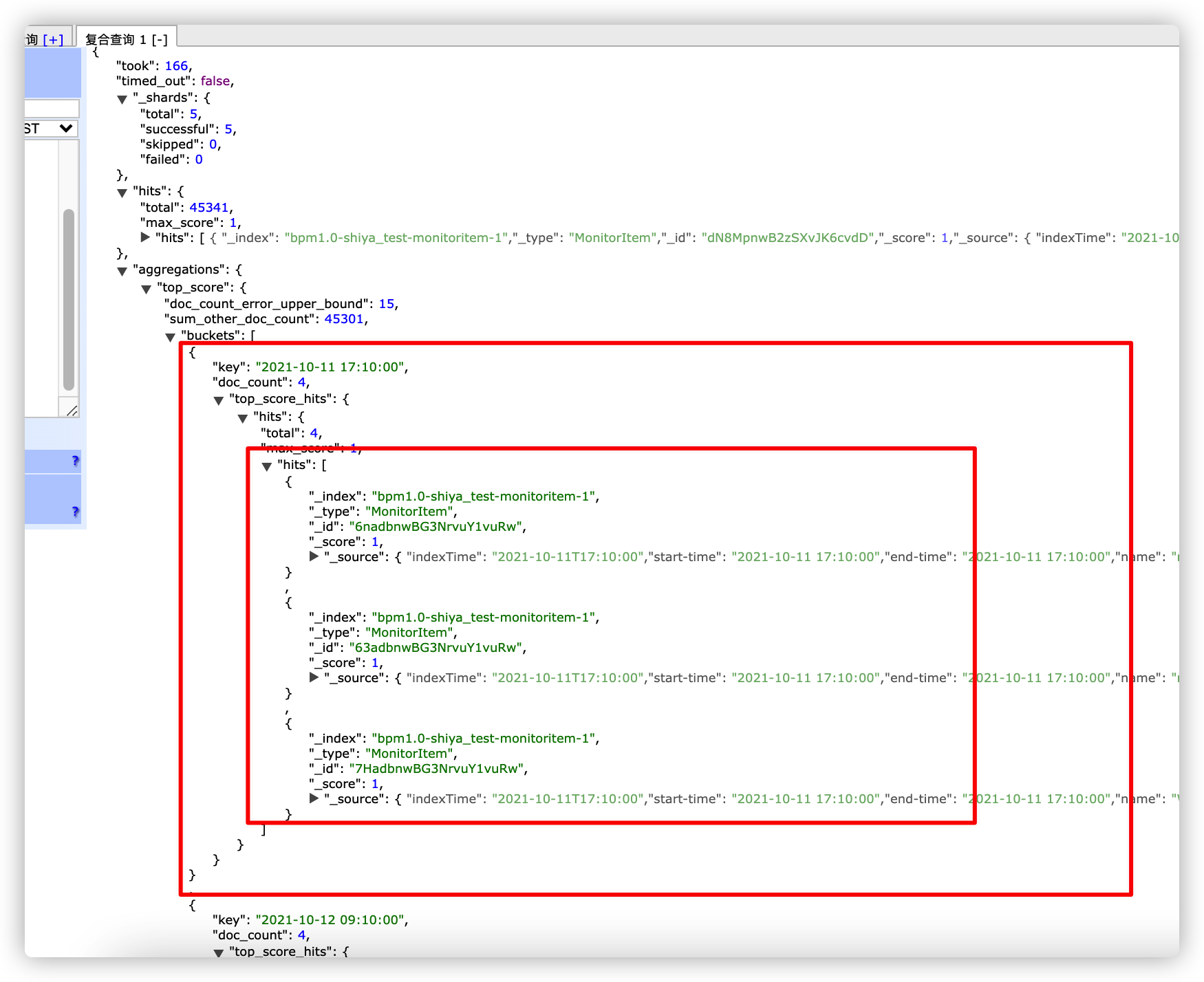
Java API
//聚合后返回分组内的数据
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits(topList)
.fetchSource(Strings.EMPTY_ARRAY, Strings.EMPTY_ARRAY);解析部分代码如下:
TopHits topHits = bucket.getAggregations().get("top_score_hits");
SearchHits hits = topHits.getHits();
SearchHit[] hitArray = hits.getHits();
for (SearchHit hit : hitArray) {
//单条数据处理
}7. 聚合后分页并排序 - bucket_sort
使用 bucket_sort 可以对聚合查询返回的多个桶进行分页。bucket_sort 包含 from 和 size 两个参数。bucket_sort 还可以对分页后的数据进行排序。
- from:从第几条数据开始
- size:取几条数据。
{
"query": {
"bool": {
"must": [
{
"term": {
"monitor-item-id": "103"
}
}
]
}
},
"aggs": {
"top_score": {
"terms": {
"field": "timestamp.keyword",
"size": 20 //限制返回的桶数量(不填则默认为10)
},
"aggs": {
"bucket_truncate": {
"bucket_sort": {
"sort": [{
"_key": {
"order": "asc" //1.对分页后的数据进行排序
}
}],
"from": 0, //2.分页参数
"size": 5
}
}
}
}
}
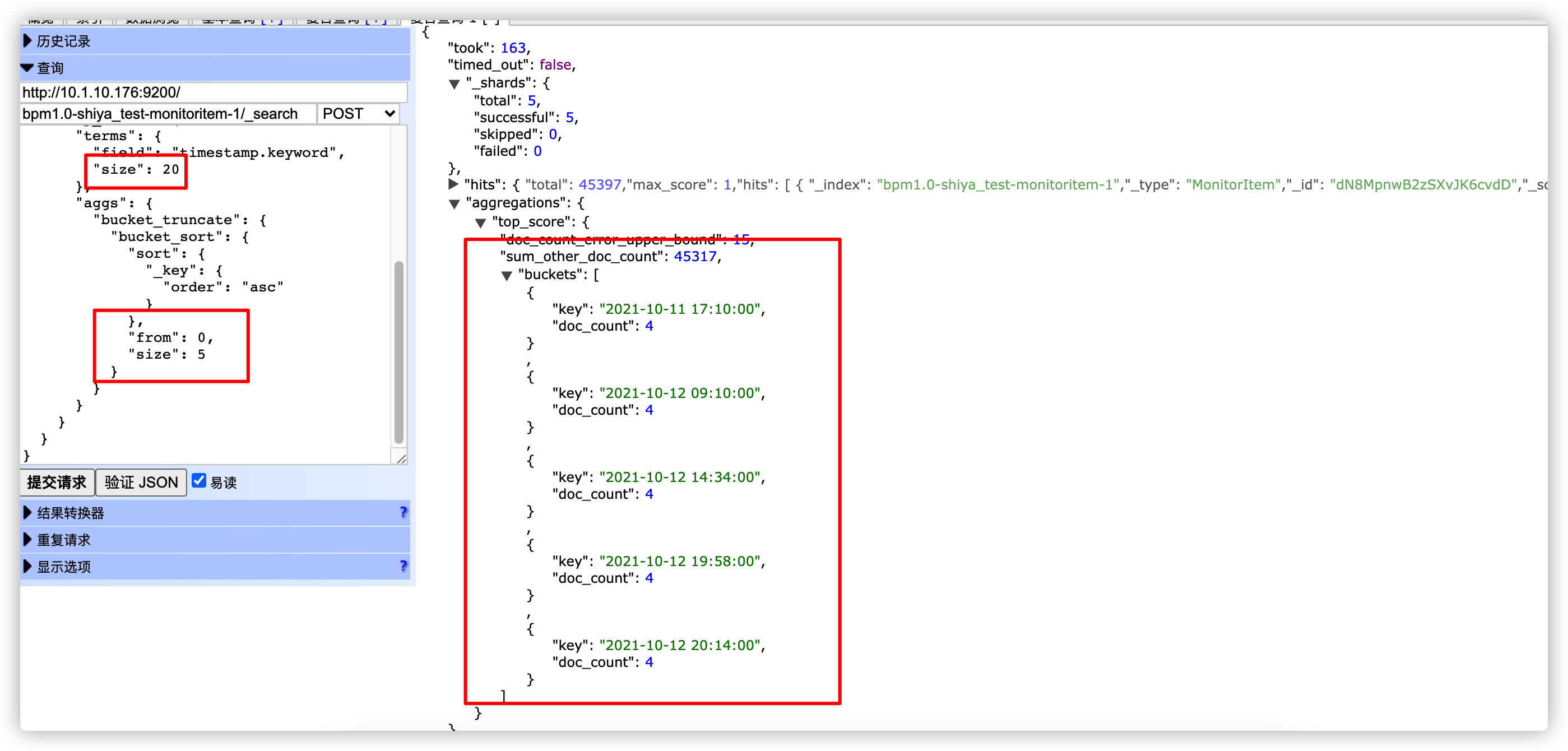
}bucket_sort 使用时是作为子聚合来使用的,嵌套在 terms 父聚合里面。针对父聚合返回的结果进行分页操作,比如父聚合只返回 100 个桶,则 bucket_sort 只能对 100 个桶进行操作。
在分页查询的时候,一定要注意 from + size 要小于返回的桶数量(size),否则会因为返回桶数量的限制导致分页查询结果为空。
测试设置返回桶数量 size=20,from=20,size=5。分页参数设置超过了返回的桶数量,测试查询结果为空。
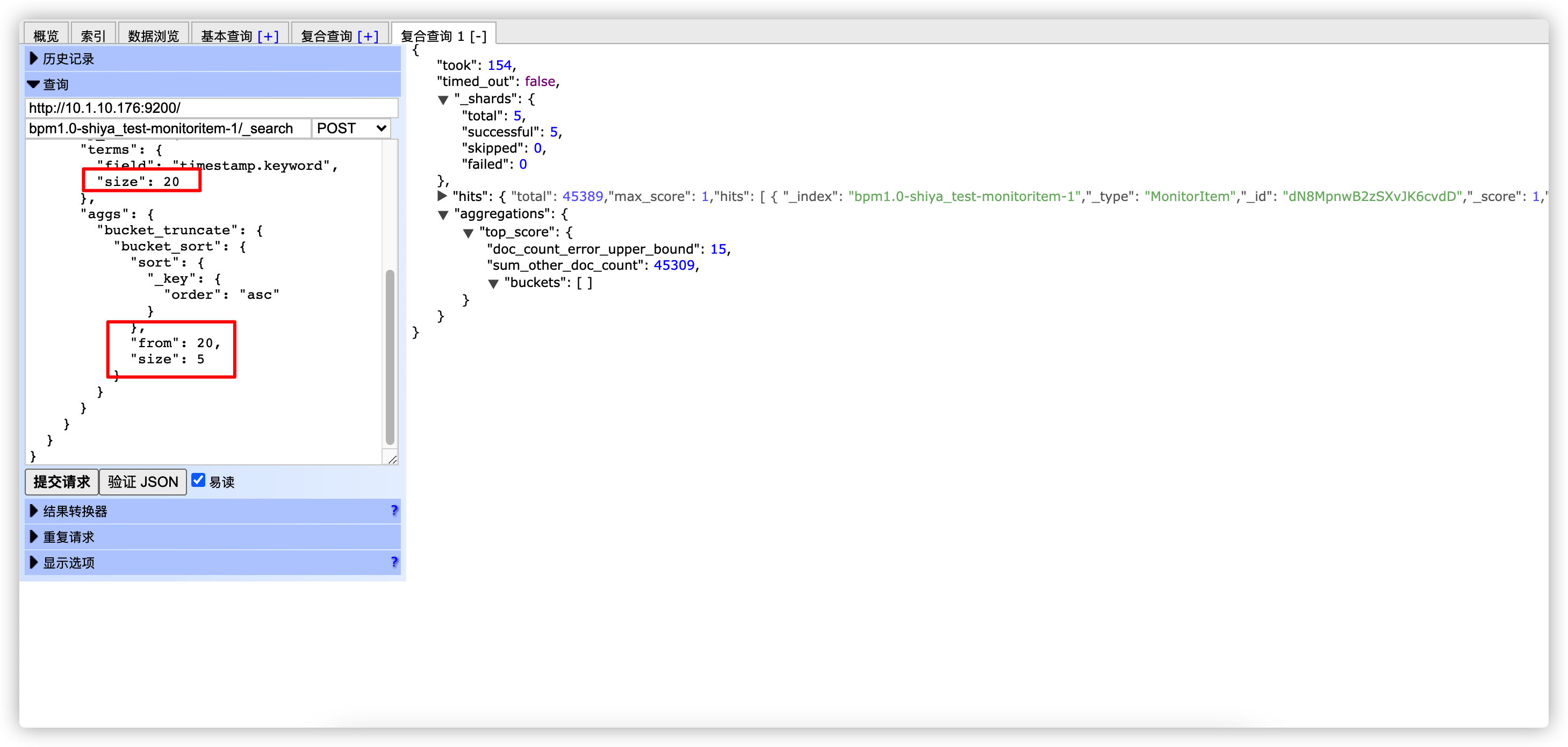
测试设置返回桶数量 size=20,from=0,size=5。分页参数设置在返回的桶数量范围内,正常返回数据。
Java API
//指定字段排序
FieldSortBuilder fieldSortBuilder = new FieldSortBuilder("_key");
fieldSortBuilder.order(SortOrder.ASC);
List<FieldSortBuilder> fieldSortBuilderList=new ArrayList<>();
fieldSortBuilderList.add(fieldSortBuilder);
//聚合后分页(设置分页参数)
BucketSortPipelineAggregationBuilder bucketSortPipelineAggregationBuilder =
new BucketSortPipelineAggregationBuilder("bucket_field", fieldSortBuilderList)
.from(from).size(size);8. 分组-聚合结果排序-再分页
- 先根据某字段聚合。
- 聚合后根据某字段排序。
- 对聚合查询的结果进行分页查询
DSL查询语句
{
"query": {
"bool": {
"must": [
{
"term": {
"monitor-item-id": "103" }
}
]
}
},
"aggs": {
"top_score": {
"terms": { //1.根据某字段聚合
"field": "timestamp.keyword",
"size": 255, //限定聚合总数量(限制分页参数from和size)
"order": [
{
"_key": "desc" //2.根据聚合的主键倒序排列
}
]
},
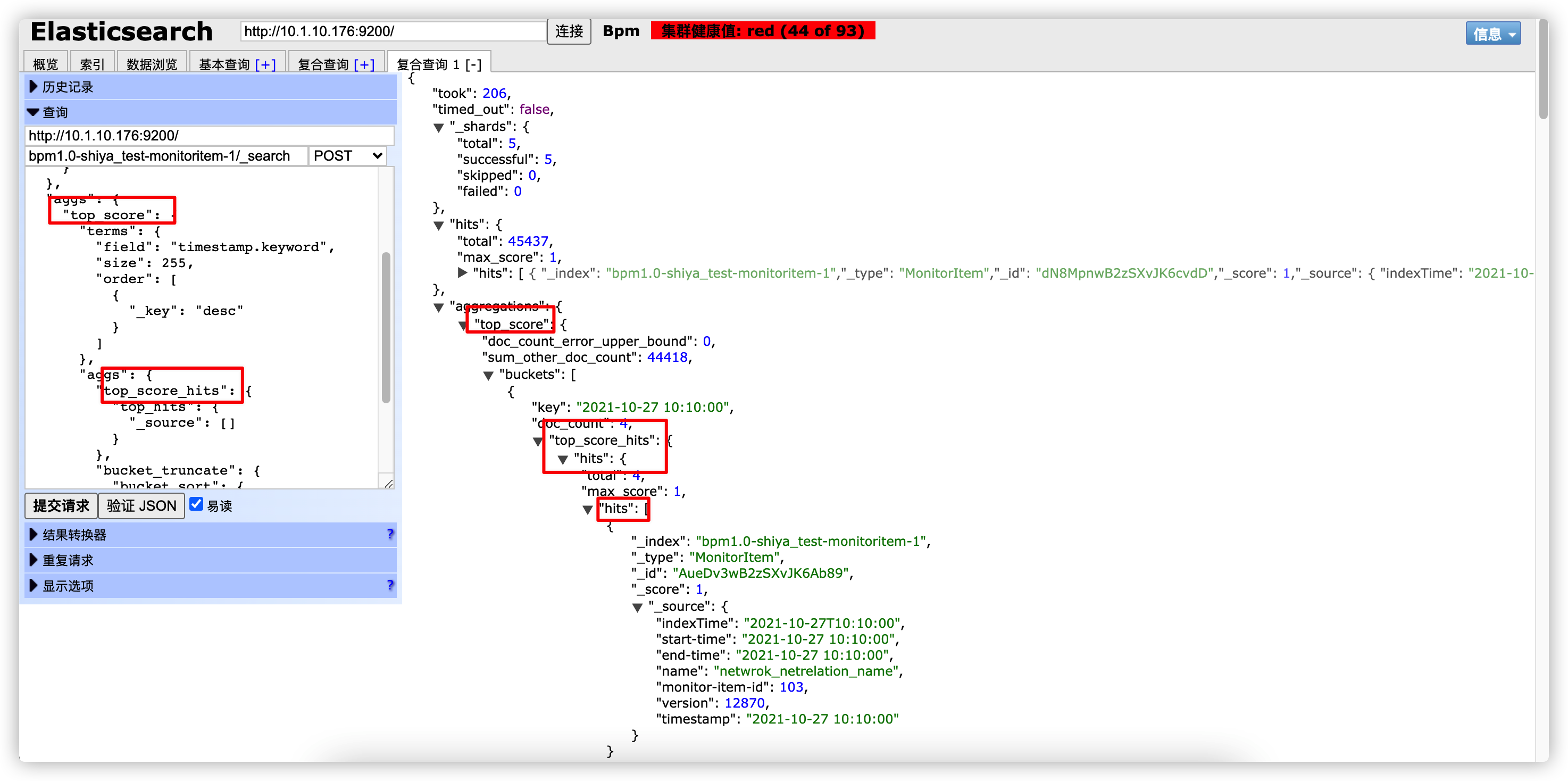
"aggs": {
"top_score_hits": { //返回聚合后,分组内的详细数据
"top_hits": {
"_source": [] //指定返回的数据字段,不填则全部返回
}
},
"bucket_truncate": { //3.对聚合查询后的字段进行分页
"bucket_sort": {
"from": 0,
"size": 5 }
}
}
}
}
}查询结果
Java API
查询部分代码:
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders
.terms(topCient).field(AlarmMonitoringConstant.TIMESTAMP + ".keyword")
.size(from + size)
.order(BucketOrder.key(false));
//聚合后返回分组内的数据
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits(topList)
.fetchSource(Strings.EMPTY_ARRAY, Strings.EMPTY_ARRAY);
//聚合后分页
BucketSortPipelineAggregationBuilder bucketSortPipelineAggregationBuilder =
new BucketSortPipelineAggregationBuilder("bucket_field", null)
.from(from).size(size);
//连接分组条件
termsAggregationBuilder.subAggregation(topHitsAggregationBuilder).subAggregation(bucketSortPipelineAggregationBuilder);
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery()
.filter(QueryBuilders.matchQuery(Constants.ES_FIELD_MONITOR_ITEM_ID, monitorItem.getId()))
.filter(QueryBuilders.rangeQuery(AlarmMonitoringConstant.TIMESTAMP + ".keyword").from(startTime).to(endTime));
SearchRequestBuilder searchRequestBuilder = EsClient.getClient().prepareSearch(AlarmMonitoringConstant.getIndex(projectKey, AlarmMonitoringConstant.MONITOR_ITEM))
.setQuery(queryBuilder)
.addAggregation(termsAggregationBuilder);解析返回值的代码:
SearchResponse searchResponse = searchRequestBuilder.get();
Aggregations aggregations = searchResponse.getAggregations();
Terms terms = aggregations.get(topCient);
for (Terms.Bucket bucket : terms.getBuckets()) {
//分组时间
String timestamp = bucket.getKeyAsString();
TopHits topHits = bucket.getAggregations().get(topList);
SearchHits hits = topHits.getHits();
SearchHit[] hitArray = hits.getHits();
//单个桶
for (SearchHit hit : hitArray) {
//桶内单条记录
}
}9. 多字段集合(script)&双重聚合(sum_bucket)
多字段聚合 - script
java"script": { "source": "doc['labels.node'].values+'#'+doc['labels.pod'].values+'#'+doc['labels.container'].values", "lang": "painless" }对聚合结果进行求和操作 - sum_bucket
java"sum_device": { "sum_bucket": { "buckets_path": "termsClient>avg_client" } }buckets_path:指定的是路径。
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"from": "2021-12-24T07:57:45.000Z",
"to": "2021-12-24T08:02:45.000Z",
"include_lower": true,
"include_upper": false,
"boost": 1
}
}
},
{
"bool": {
"should": [
{
"terms": {
"labels.node": [
"10.10.102.93-salve"
],
"boost": 1
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1
}
},
{
"bool": {
"should": [
{
"term": {
"name": {
"value": "kube_pod_container_resource_limits_cpu_cores",
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"aggregations": {
"name": {
"terms": {
"field": "name",
"size": 1000,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
},
"aggregations": {
"termsClient": {
"terms": {
"script": {
"source": "doc['labels.node'].values+'#'+doc['labels.pod'].values+'#'+doc['labels.container'].values",
"lang": "painless"
},
"size": 1000,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
},
"aggregations": {
"avg_client": {
"max": {
"field": "value"
}
}
}
},
"sum_device": {
"sum_bucket": {
"buckets_path": "termsClient>avg_client"
}
}
}
}
}
}返回值:
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 36,
"max_score": 0,
"hits": [
]
},
"aggregations": {
"name": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "kube_pod_container_resource_limits_cpu_cores",
"doc_count": 36,
"termsClient": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "[10.10.102.93-salve]#[apm-abnormal-alarm-0]#[apm-abnormal-alarm]",
"doc_count": 7,
"avg_client": {
"value": 1
}
},
{
"key": "[10.10.102.93-salve]#[node-exporter-6gpnn]#[node-exporter]",
"doc_count": 7,
"avg_client": {
"value": 0.25
}
},
{
"key": "[10.10.102.93-salve]#[process-exporter-gsnsm]#[process-exporter]",
"doc_count": 7,
"avg_client": {
"value": 0.512
}
},
{
"key": "[10.10.102.93-salve]#[apm-es-server-0]#[apm-es-server]",
"doc_count": 6,
"avg_client": {
"value": 2
}
},
{
"key": "[10.10.102.93-salve]#[node-exporter-6gpnn]#[kube-rbac-proxy]",
"doc_count": 5,
"avg_client": {
"value": 0.02
}
},
{
"key": "[10.10.102.93-salve]#[alertmanager-main-0]#[config-reloader]",
"doc_count": 4,
"avg_client": {
"value": 0.1
}
}
]
},
"sum_device": {
"value": 3.882
}
}
]
}
}
}Java 代码参考:
// 按照指标和instance聚合
Script script = new Script("doc['labels.pod'].values+'#'+doc['labels.container'].values");
// 聚合生成各状态下最大值和最小值
TermsAggregationBuilder podAggs = AggregationBuilders.terms("pod_client").script(script)
.size(ESConstants.TERMS_SIZE)
.subAggregation(AggregationBuilders.avg("avg_client").field(EsQueryUtil.VALUE));
SumBucketPipelineAggregationBuilder sumBucketPipelineAggregationBuilder = new SumBucketPipelineAggregationBuilder("sum_client", "pod_client>avg_client");
sourceBuilder.aggregation(nameAggs.subAggregation(nodeAggs.subAggregation(podAggs).subAggregation(sumBucketPipelineAggregationBuilder)));
SearchRequest request = new SearchRequest().indices(getIndexesWithMasterIP(masterIp, TimeUtil.getDayZeroFinal(), new Date(), TYPE_INDEX_PROMETHUSBEAT)).source(sourceBuilder);
LinkedHashMap<String, List<NodeBasicMetricValue>> dataMap = new LinkedHashMap<>();
try {
// 执行ES查询
SearchResponse response = ConnectEs.instance().doSearchAction(request);
if (Objects.nonNull(response) && Objects.nonNull(response.getAggregations()) && Objects.nonNull(response.getAggregations().get("name_client"))) {
Terms terms = response.getAggregations().get("name_client");
for (Terms.Bucket bucket : terms.getBuckets()) {
String metricName = bucket.getKeyAsString();
Terms podTerems = bucket.getAggregations().get("node_client");
for (Terms.Bucket podBucket : podTerems.getBuckets()) {
String nodeName = podBucket.getKeyAsString();
double sumValue = ((ParsedSimpleValue) podBucket.getAggregations().get("sum_client")).value();
......
}
}
}
} catch (Exception e) {
......
}