
Elasticsearch查询原理
ES查询原理
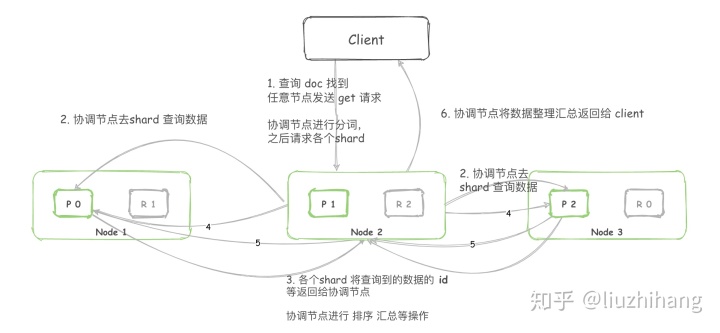
查询方式
- 根据 doc_id 查询。
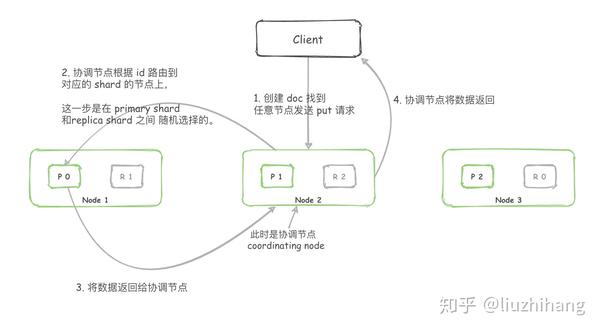
- 根据条件查询
倒排索引
根据文档中的每个字段建立倒排索引。
倒排索引的查询流程
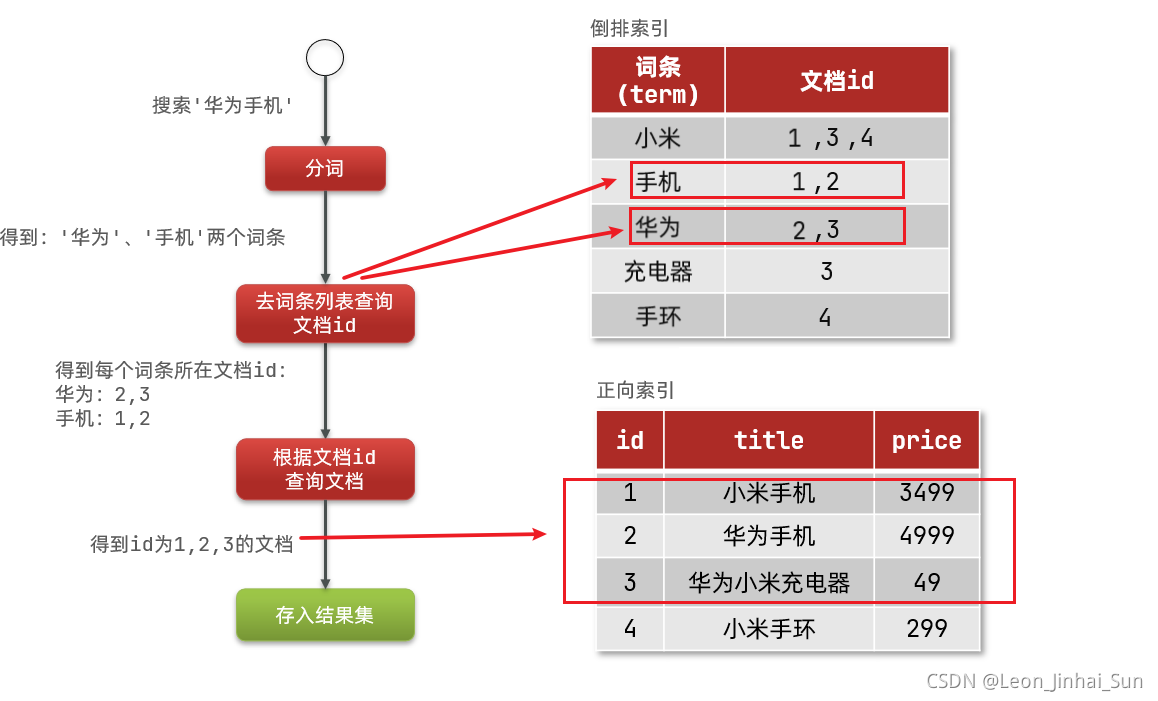
- 查询条件分词。
- 查询单词词典 (term dictionary)。
- 获取对应分词的 doc_id 列表。
- 将查询结果返回。
不需要分词的字段,直接使用 keyword 类型,查询的时候不需要分词,查询效率会更高。
倒排索引的组成
postings list
文档列表。
term dictionary
单词字典表。包含文档中所有的单词,es 会将单词排序。
单词字典表为了快速查找,按照理论应该放到内存中。但是 es 默认可以对所有字段进行索引,单词 (term)的量会非常大,直接放到内存,内存肯定会爆的。所以需要引入其它数据结构来帮助查询单词字典表。
term index
类似字典树,专门处理字符串匹配的数据结构。它里面存放的是 单词(term)的前缀,对应数据存放的是 term dictionary 中的对应前缀的第一个 offset,然后从该 offset 顺序查找即可快速查到对应的单词(term)。
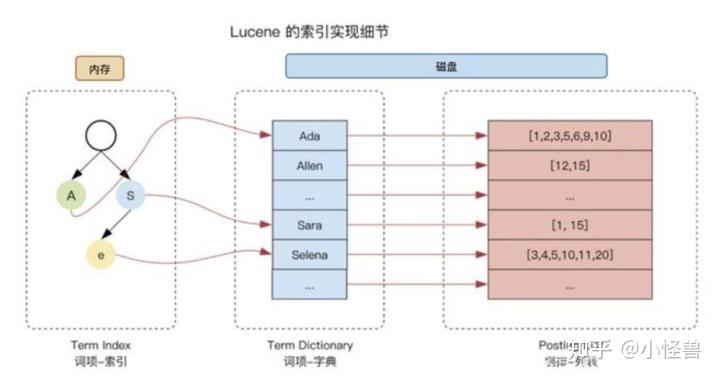
当数据量不断增加时,内存中放不下 Term index。针对这种情况,es 采用了 FST 数据结构来压缩 Term index。