
倒排索引图解
原理图
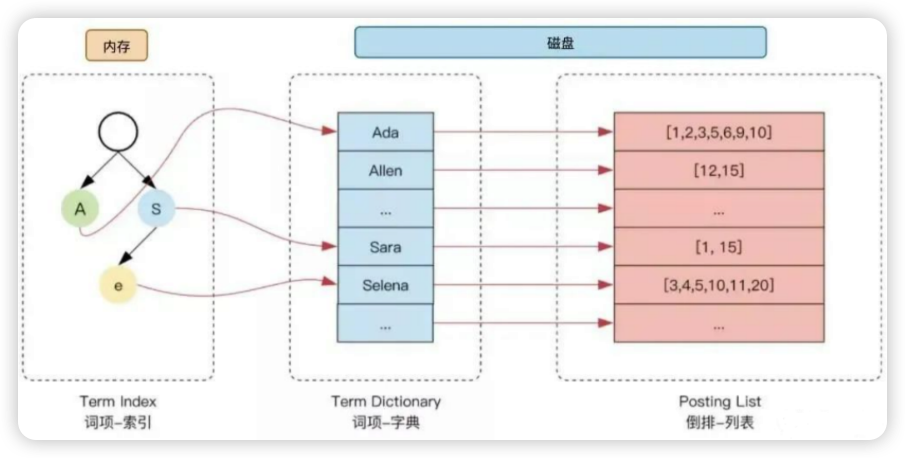
倒排索引的搜索过程
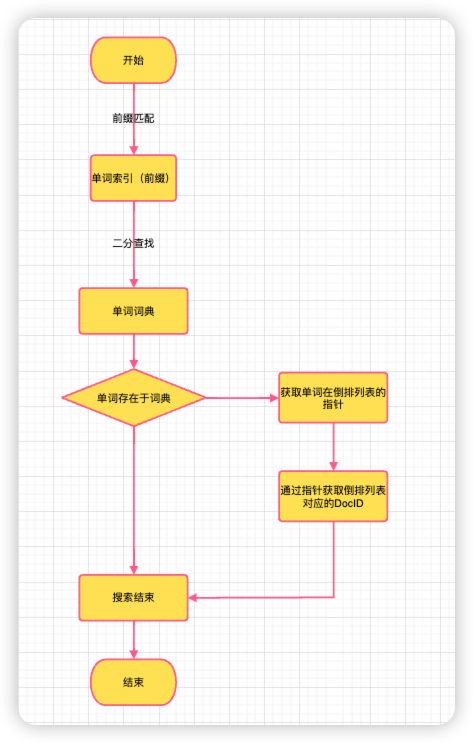
倒排索引原理
Elasticsearch 主要功能就是搜索,为了提高搜索效率,其内部使用了倒排索引。
正排索引
在搜索引擎中,每个文件对应一个文件 ID (doc_id),文件内容是关键词的集合。

根据 doc_id 可以查找到文档详情。
这种方式本质上就是通过文档的 key 查找 value 值。
比如查找 name=jetty wan 的文档,只能按照顺序从前向后匹配每个文档的 name 字段。
这种查找方式的效率非常低下。
倒排索引
倒排索引和正向索引相比,通过数据结构保存包含每个单词的文档列表,来实现单词的快速查询。
如下图,比如说我想搜索 name 中包含 wang 的文档,先从单词词典中查找到 wang ,再去倒排列表中查找 wang 对应的文档列表。能够大大提升查询速率。
倒排索引组成
倒排索引的结构由三部分组成:单词词典、倒排列表和倒排文件。
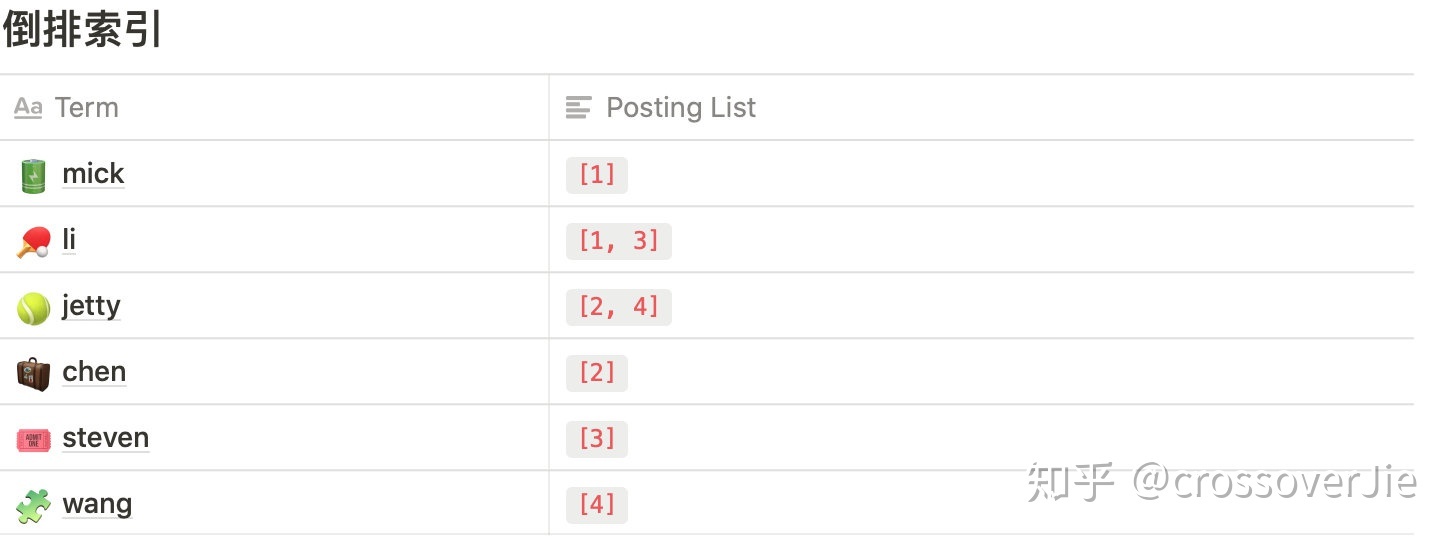
单词词典
搜索引擎搜索时单位通常是单词,而单词词典就是文档集合中出现的所有单词列表,每个单词都包含一个指向倒排列表的指针。
倒排列表
根据倒排列表可以知道包含某个单词的所有文档信息。倒排列表中的每条记录又叫做倒排项。
主要包含:
- 单词和出现该单词的文档列表。
- 记录每个单词在所有文档中的出现次数和所在位置。
倒排文件介绍
倒排列表是倒排索引的主要组成部分,而倒排文件就是磁盘中保存倒排列表的文件,是存储倒排列表的物理文件。
倒排索引位置
倒排索引的结构由三部分组成:单词词典、倒排列表和倒排文件。
单词词典通过特定结构存在于内存中,而倒排文件存在磁盘中。
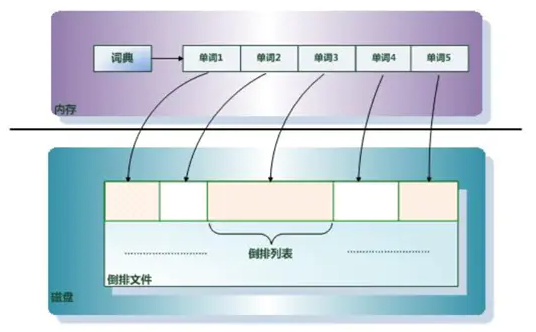
单词词典
单词列表中包含的数据是文档中出现过的所有单词,每个单词都包含一个指向倒排列表的指针。
当想要查询包含某个单词的所有文档时,第一步就要从单词列表中查询该单词。若单词列表数据结构是线性表的话,查询效率是非常低下的。
常见的单词列表数据结构有 哈希加链表 和 B+树)。
哈希加链表
和 HashMap 1.7 时的底层数据结构一样。
通过计算单词的 hash 值计算出其所在哈希表的位置,若哈希表同一位置上出现多个单词,则会在该位置形成链表结构。
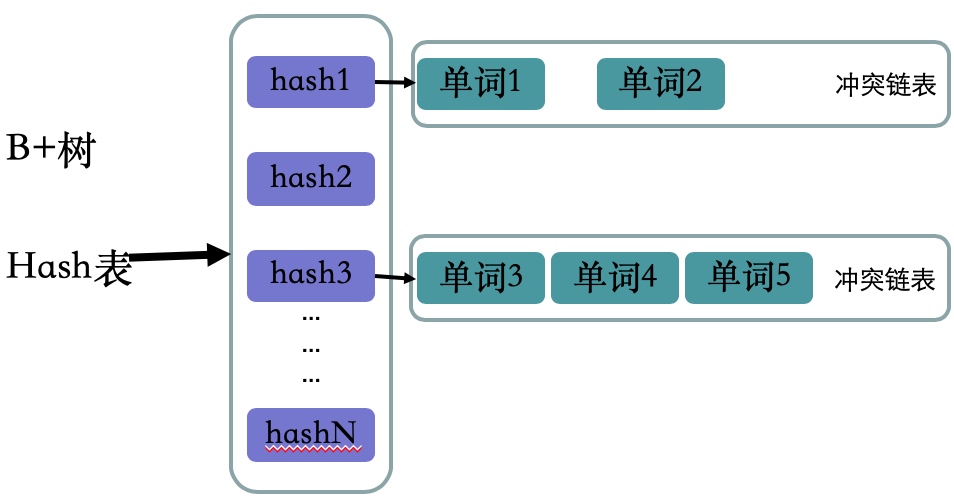
哈希加链表最大的缺点就是不能支持单词的顺序或者范围查找。
B+树
B+ 树要求存入的单词字典项能够按照大小排序(数字或字符串),而哈希表是无需满足该要求的。
同样的 B+ 树结构可以满足顺序查找和范围查找。
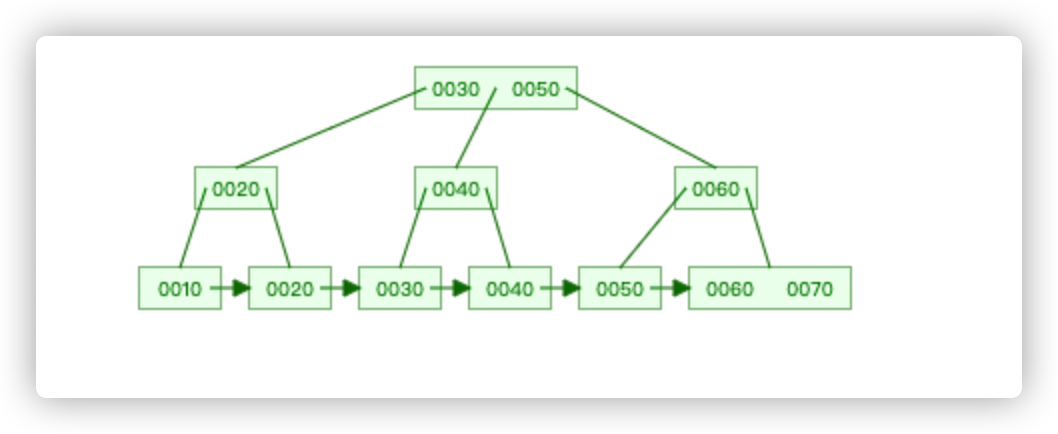
B+ 树的叶子结点保存了单词的地址信息,通过地址信息就能找到单词信息。
使用 B+ 树能够大大减少查找次数,提高查询效率。
单词词典索引
单词词典保存了文档中所有存在的单词。
在Elasticsearch(ES)的倒排索引中,
Term Index(有时也称为前缀索引或加速索引)包含了倒排索引中词条(terms)的前缀,而不是完整的词条本身。其主要目的是为了加速词条的查找过程。
倒排列表
倒排列表主要包含:
- 单词和出现该单词的文档列表。
- 记录每个单词在所有文档中的出现次数和所在位置。每条记录又称一个倒排项。
倒排列表元素数据结构:((DocID;TF;<POS>))
- DocID:出现某单词的文档ID
- TF(Term Frequency):单词在该文档中出现的次数
- POS:单词在文档中的位置
假设有下面单个文档
| 内容 | |
|---|---|
| 文档1 | 百度的年度目标 |
| 文档2 | AI技术生态部的年度目标 |
| 文档3 | AI市场的年度目标 |
则他们生成的倒排索引
| 单词ID | 单词 | 逆向文档频率 | 倒排列表(DocID;TF;) |
|---|---|---|---|
| 1 | 目标 | 3 | (1;1;<3>),(2;1;<5>),(3;1;<4>) |
| 2 | 年度 | 3 | (1;1;<2>),(2;1;<4>),(3;1;<3>) |
| 3 | AI | 2 | (2;1;<1>),(3;1;<1>) |
| 4 | 技术 | 1 | (2;1;<2>) |
| 5 | 生态 | 1 | (2;1;<3>) |
| 6 | 市场 | 1 | (3;1;<2>) |
比如单词“年度”,单词ID为2,在三个文档中出现过,所以逆向文档频率为3,同时倒排索引中的元素也有三个:(1;1;<2>),(2;1;<4>),(3;1;<3>)。
拿第一个元素(1;1;<2>)进行说明,它表示“年度”再文档ID为1的文档中出现过1次,出现的位置是第二个单词。