
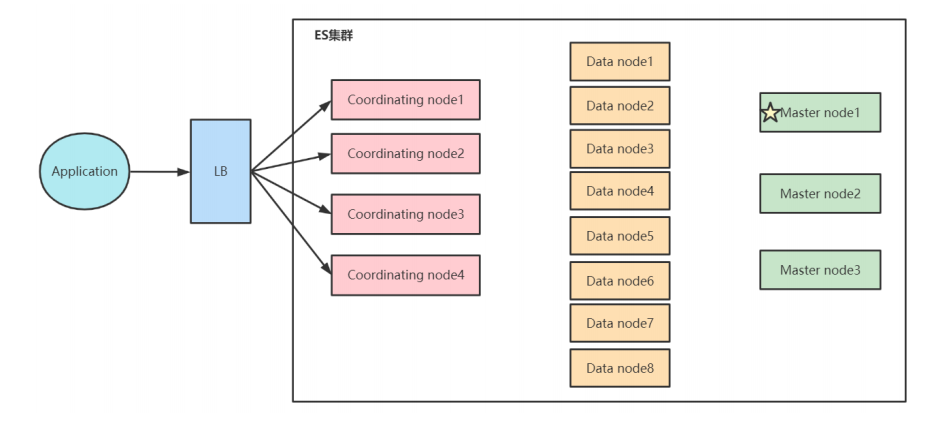
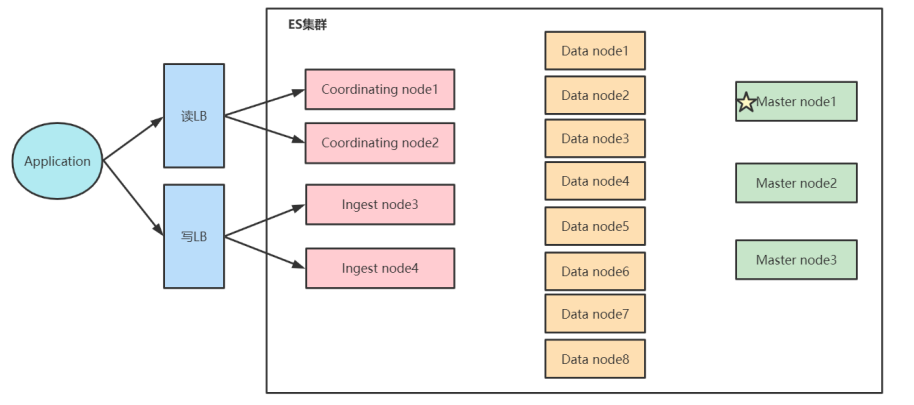
ES集群
集群节点类型
- Master Node - 主节点
- DataNode - 数据节点
- Coordinating Node - 协调节点
Master Node
- 处理创建,删除索引等请求。
- 决定分片被分配到哪个节点。
- 维护并更新集群 state。
Master Node节点最佳实践
- Master节点非常重要,在部署上需要解决单点问题。
- 为一个集群设置多个Master节点,而且节点只承担 Master 角色。
Data Node
保存数据的节点,负责保存分片数据。
通过增加数据节点可以解决数据水平扩展和解决数据单点的问题。
Coordinating Node
- 负责接收 Client 的请求,将请求分发到合适的节点,最终把查询结果汇总到一起。
- 每个节点默认都是 Coordinating Node。
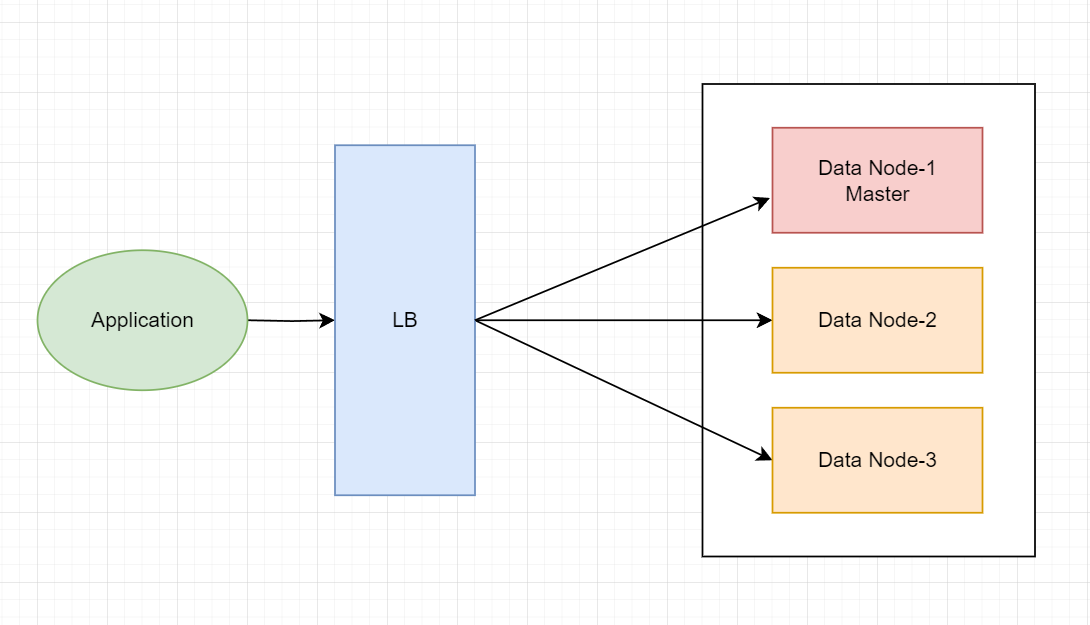
普通规模
一般es集群是三个节点。三个分片,一个副本。
三个节点配置了都可以作为master节点,同时又是data节点。
- master节点会管理元数据操作,比如创建、删除索引,以及管理分片。
- data节点会保存数据,master节点将索引按照分片划分到data节点上面。
# 指定集群名称3个节点必须一致
2 cluster.name: es‐cluster
3 #指定节点名称,每个节点名字唯一
4 node.name: node‐1
5 #是否有资格为master节点,默认为true
6 node.master: true
7 #是否为data节点,默认为true
8 node.data: true- 三个节点作为data节点,同时都可以竞争master。
- 一个集群只有一台活跃的主节点。
- 平均查询和写入流量。
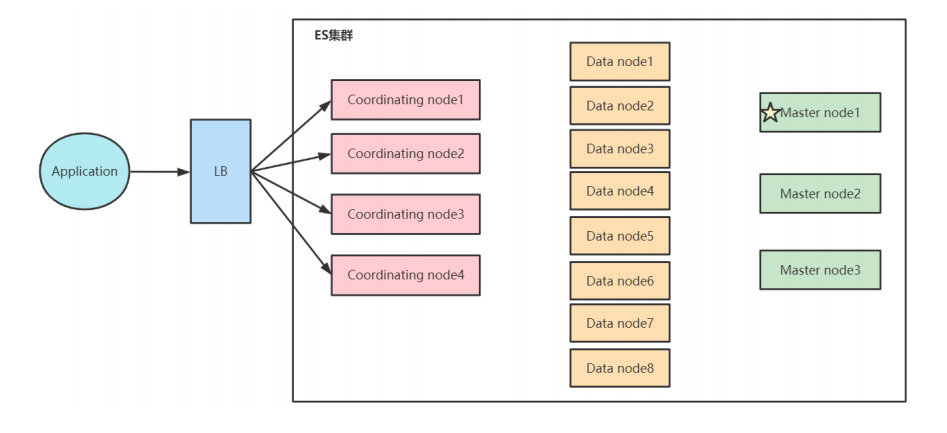
大规模生产环境
- 3个master节点
- 6个data节点
- 3个协调节点
master和data节点要分开。
master节点可以专注于元数据操作。
data节点则专注于数据存储和检索。
注意data节点和分片数的关系。
协调节点作为查询入口,汇总数据。
- 当磁盘容量不够,磁盘写入压力过大的时候,可以水平扩展data节点。
- 当系统中有大量复杂查询和聚合查询的时候,增加协调节点,提高查询的性能。
协调节点的问题
3master-6node这种高可用情况,master节点一般资源较少。
由于es默认请求打到哪台节点上面,哪台节点作为协调节点来查询数据,并做最终的汇总。所以master节点可能也会吃资源。
所以尽量避免master作为协调节点,可以配置专门的协调节点。一般要求CPU和内存高,提高查询和聚合的效率。
集群脑裂问题
节点单一职责分离
在大规模生产中,一个节点只承担一个角色。
这种单一角色职责分离的好处:
单一 master eligible nodes: 负责**集群状态(cluster state)**的管理
使用低配置的CPU,RAM和磁盘
单一 data nodes: 负责数据存储及处理客户端请求
使用高配置的CPU,RAM和磁盘
单一Coordinating Only Nodes(Client Node):负责发起数据查询,汇总data上报的数据。
使用高配置CPU; 高配置的RAM; 低配置的磁盘
单一ingest nodes: 负责数据处理
使用高配置CPU; 中等配置的RAM; 低配置的磁盘
数据前置处理转换节点,支持pipeline管道设置,可以使用 ingest 对数据进行过滤、转换等操作
大集群单独设置协调节点
在大的集群中,为了降低master和data的负载,可以单独设置协调节点。
如果不设置协调节点,默认每个节点都可以作为协调节点。但是master节点一般资源较低,不适合作为协调节点来使用,因为协调节点汇总数据比较耗内存。
- Load Balancers
- 负责搜索结果的聚合和判定。
- 分离故障,避免请求占用大量内存导致oom影响其他节点。
架构
普通架构
高可用
读写分离
Hot&Warm 冷热分离架构
- ES数据通常不会有update操作。
- 适合于 Time Based 索引数据,同时数据量比较大的情况。(比如监控数据)
- Hot节点(通常使用SSD):索引不断有新文档写入。
- Warm节点(通常使用HHD):存放不更新的数据,同时不存在大量的数据查询。
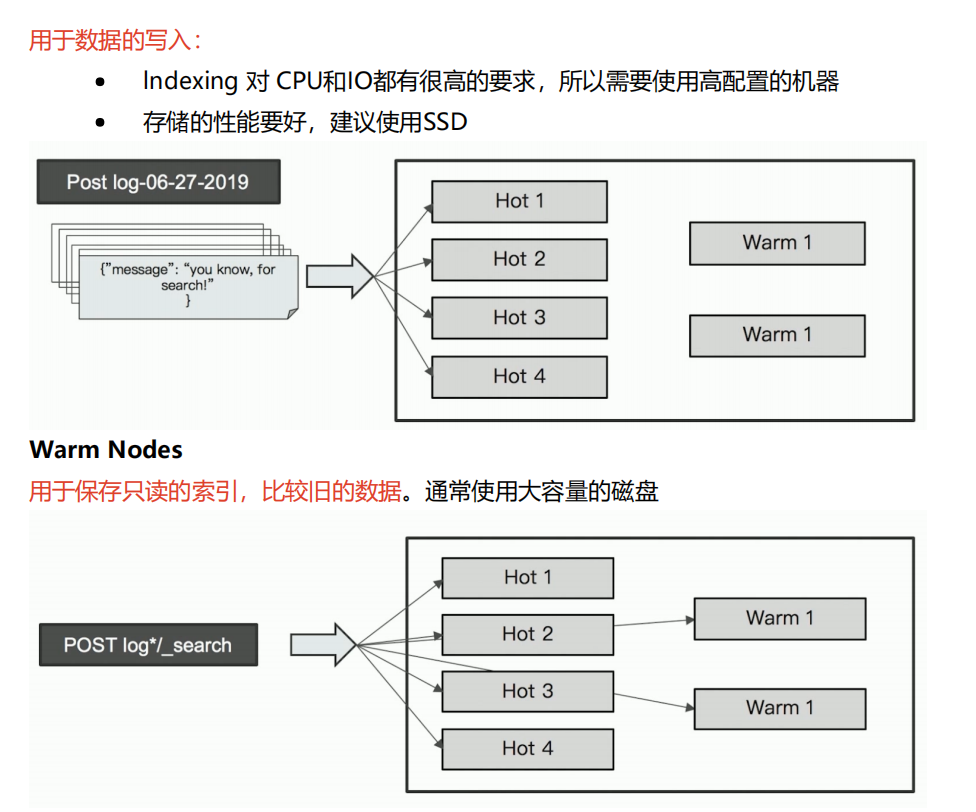
冷热分离架构需要考虑数据是如何复制的。
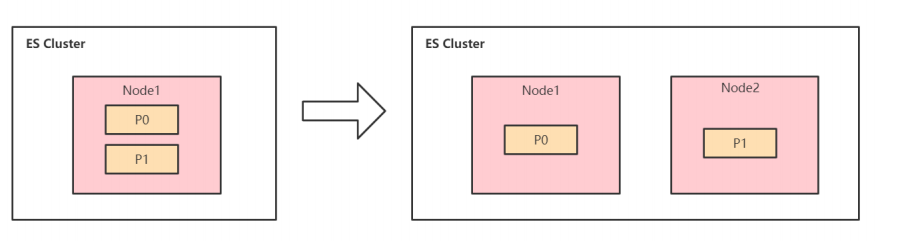
分片设计
单个分片
7.0开始,新建索引默认只有一个分片。
单个分片,查询算分,聚合查询的问题可以得到避免。
聚合top是每个data Node取top数据然后计算。
但是单个分片,集群无法水平扩展。
多个分片
es会自动进行分片的移动,类似Rebalance。
算法不准
多分片存在算法不准的问题。
因为每个分片都是基于自己的分片上的数据进行相关度计算的。
解决算法不准?
- 单个分片
- 全部查询,整体计算。消耗CPU和内存,执行性能低下,一般不建议使用。
设计多分片的好处
- 一旦集群有新数据节点加入,分片就会自动进行分配。
- 分片重新分配时,系统不会有downtime。
- 查询可以并行查询。
- 数据可以分散到多个机器里。
多分片的缺点
- 分片过多会导致额外的性能开销,因为需要维护分片。
- 每次搜索的请求,需要达到每个分片上。
- 分片的meta信息由master节点维护,过多的分片会增加管理的负担。
云监控索引三个分片,一个副本分片。单个索引就是6个分片,7天是42个,100个索引就是4200个分片。
如何确定分片数
存储角度
- 搜索类应用,单个分片不要超过20GB
- 日志类应用,当分片不要超过50GB
为什么要控制分配存储大小
- 提高Update的性能。
- 进行Merge时,减少需要的资源。
- 丢失节点后,具备更快的恢复速度。
- 便于分片的Rebalance。
集群容量规划
es总体来说是比较吃内存和磁盘的。
- 磁盘表现在es数据压缩能力不好,以文档形式存放。
- 内存表现在:
- es的倒排索引、词典表和词典表的索引都在内存中。
- 协调节点在查询时,需要汇总node上报的数据。然后再做聚合等操作,也是耗内存的过程。
注意点
JVM内存配置为机器内存的一半。
因为lucene需要用到一半的堆外内存。
单节点数据量控制在2TB以内。
磁盘选择
- 搜索场景高的情况,选择SSD。
- 日志和查询并发低的场景,考虑使用机械硬盘。
内存和磁盘的比例
- 搜索场景高,1:16
- 日志类或者查询不高的场景,1:48 ~ 1:96
齐商,16G1TB的es满足这个要求。
假如32G内存,搜索类场景可以满足
32*16=500G的数据,加上预留空间,一个节点大概400G数据。日志场景
32*100=3200G,一个节点大概3T的数据。
容量规划案例
信息库搜索
这类数据特点
- 和时间范围无关
- 不会有大量的写入。
- 关注查询的效率和准确性。
按照索引数据量,确认分片的数量:
- 单个分片数据最好不要超过20G。
- 可以通过增加副本分片,来提高查询的吞吐量。
基于时间序列的数据
- 日志、指标等数据
这类数据特点
- 每条数据都有时间戳,数据基本不会被更新。
- 用户更多是查询近期的数据,对旧数据关注较少。
- 对数据写入性能要求过高。
按照时间对索引进行划分。
- 在索引名称中增加时间信息
- 可以按天、按周或者按月划分。
- 根据时间做冷热数据分离。
云监控数据就是这样做的。
查询优化
索引拆分
如果单个索引有大量的数据,可以考虑将索引拆分为多个索引。
- 减少单个索引数据量,提高查询性能
- 可以同时对多个索引进行查询。
按照字段划分
如果根据某字段进行查询较多,而且该字段是一个枚举值。比如地区。
可以按照地区拆分索引。
按照时间划分
比如将数据按天划分索引,提高并发查询的效率。
提高分片查询效率
在写入数据的时候,尽量将数据平均写到每个分片里面,这样在查询的时候能够提高并发查询效率。(类似kafka的paritationKey)
es分片路由的规则: shard_num = hash(_routing) % num_primary_shards
_routing字段的取值,默认是_id字段,可以自定义。
POST /users/_create/1?routing=fox{ "name":"fox"}