
Elasticsearch写入原理
基本概念
索引
Elasticsearch的索引是一个逻辑上的概念,指存储了相同类型的文档集合。
映射
映射(mapping)定义索引中有什么字段、进行字段类型确认。类似于数据库中表结构定义。
ES 默认动态创建索引和索引类型的 映射(mapping),就像是非关系型数据中的,无需定义表结构,更不用指定字段的数据类型。
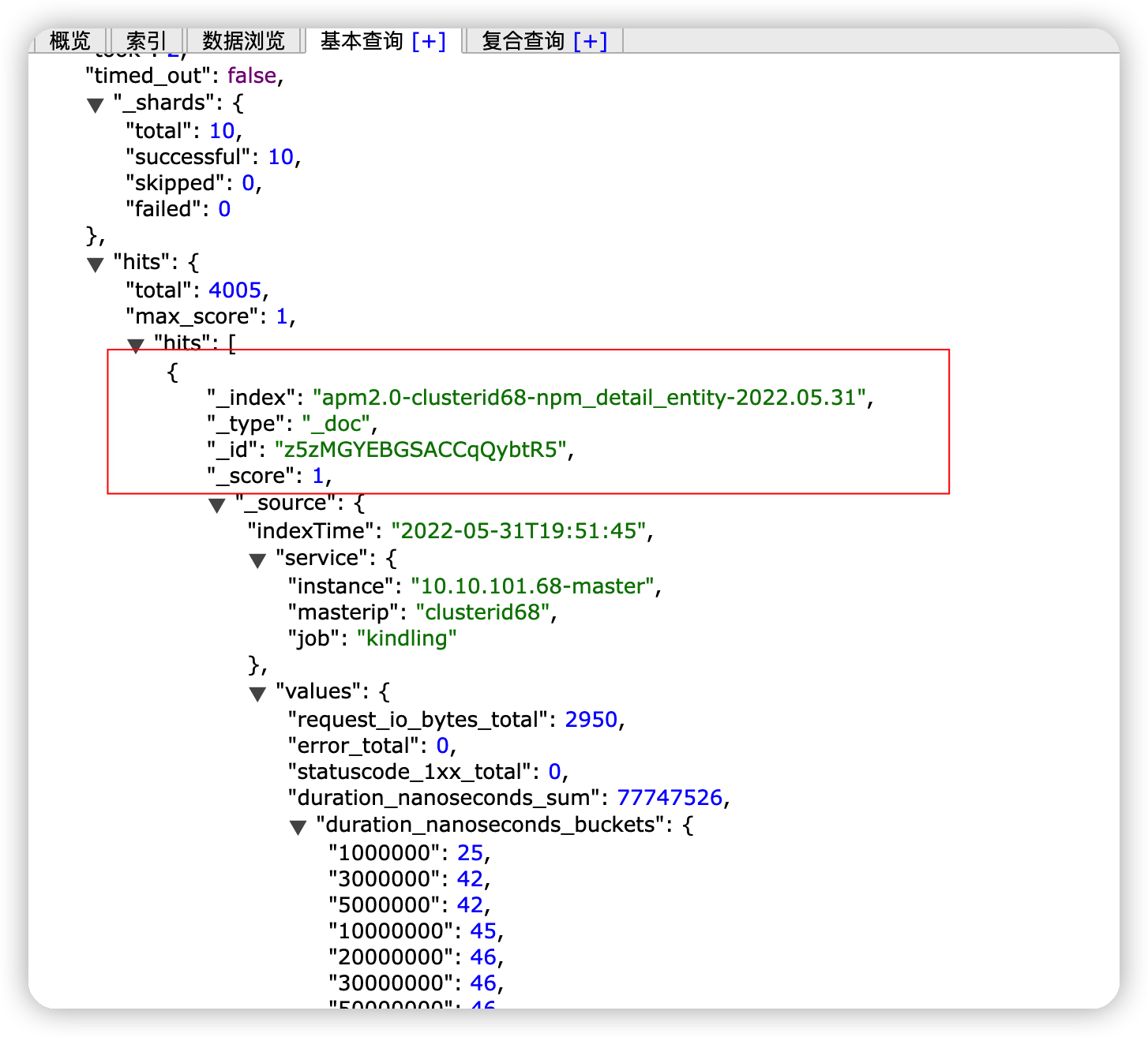
也可以手动指定 mapping 类型,比如通过请求设置索引的映射(mapping)。
curl --location --request POST 'localhost:9200/course/_mapping' \
--header 'Content-Type: application/json' \
--data-raw '{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}'
动态映射字符串
字符串类型 string 可被分为 text 和 keyword 类型。若不为索引指定映射,6.x 版本的 es 会把字符串定义为 text 类型,并增加一个 keyword 的类型字段。
云监控索引模版中,增加了动态映射规则,string 类型指定为 keyword 类型字段。
text 字段类型可以被分词查询,而 keyword 字段类型不会被分词。聚合查询的时候需要用到 keyword 类型字段。
文档
ES 索引中存放的记录就做文档,可以理解为关系型数据库中表的一行数据记录。
文档数据字段表
| 数据字段 | 含义 | |
|---|---|---|
| _index | 文档所属索引 | |
| _type | 文档映射类型(7.x 已废弃),对应关系数据库中表的概念。 | |
| _id | 文档 ID | |
| _source | 表示文档正文的原始 JSON |
集群
一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名称作为标识。
节点
一个 es 实例即为一个节点,一台机器可以有多个节点,正常使用下每个实例都应该会部署在不同的机器上。ES的配置文件中可以通过node.master、 node.data 来设置节点类型。
node.master
指定该节点是否有资格被选举成为 master 节点,默认是true。es 默认集群中的第一台机器为 master,如果这台机挂了就会重新选举 master。
node.data
指定该节点是否存储索引数据,默认为 true。
我们部署的 es 集群未指定节点类型,所以 3 个节点都是 true。
分片
shard(分片)是物理空间的概念,ES通过将索引数据拆分存储到不同的节点,用来提高ES的处理能力和可用性。
ES的一个索引可以包含多个分片(shard)
- 每一个分片(shard)都是索引最小的工作单元,承载部分数据。
- 每个shard 都是一个 lucene 实例,有完整的简历索引和处理请求的能力。
- 增减节点时,shard 会自动在 nodes 中负载均衡。
- 一个文档只能完整的存放在一个shard上。
- 一个索引中含有 shard 的数量,默认值为 5,在索引创建后这个值是不能被更改的。
- 每一个shard关联的副本分片(replica shard)的数量,默认值为1,这个设置在任何时候都可以修改。
副本
shard(分片)的冗余备份。主要作用如下:
- 冗余备份,防止数据丢失;
- shard 异常时负责容错和负载均衡;
ES写入原理
Lucene的介绍
Elasticsearch 和 Lucene 的关系很简单:Elasticsearch 是基于 Lucene 实现的。ES 基于底层这些包,然后进行了扩展,提供了更多的更丰富的查询语句,并且通过 RESTful API 可以更方便地与底层交互。类似 ES 还有 Solr 也是基于 Lucene 实现的。
ES整体结构
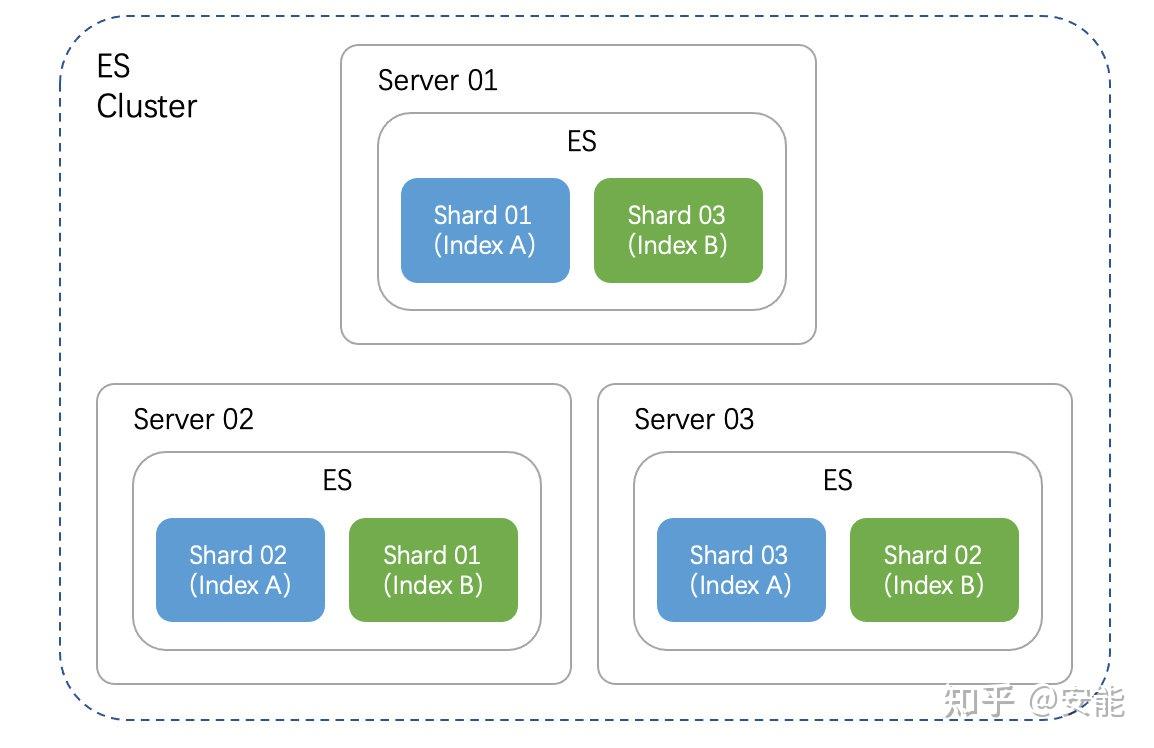

分片结构
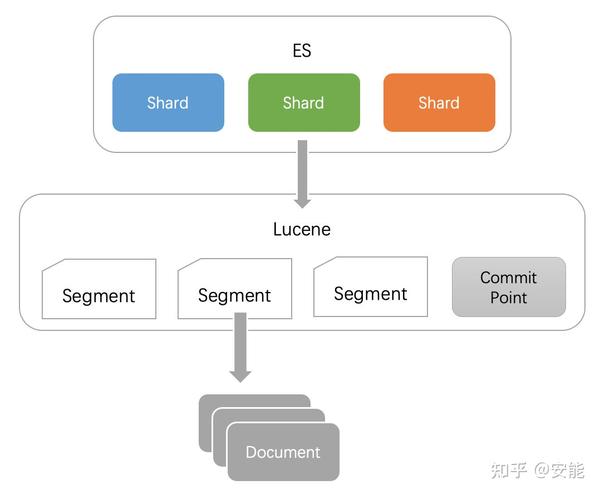
Lucene
Lucene 是 Elasticsearch所基于的 Java 库。
Segment
也叫段,类似于倒排索引,相当于一个数据集。
Commit point
提交点,记录着所有已知的 Segment 信息。
del 文件
记录着删除文档的信息。
- 文档新写入时,会生成新的 segment。同样会记录到 commit point 里面
- 文档查询,会查询所有的 Segment。
- 当一个段中的文档被删除或更新时,会将之前文档添加到该文件中。
分片写入的流程
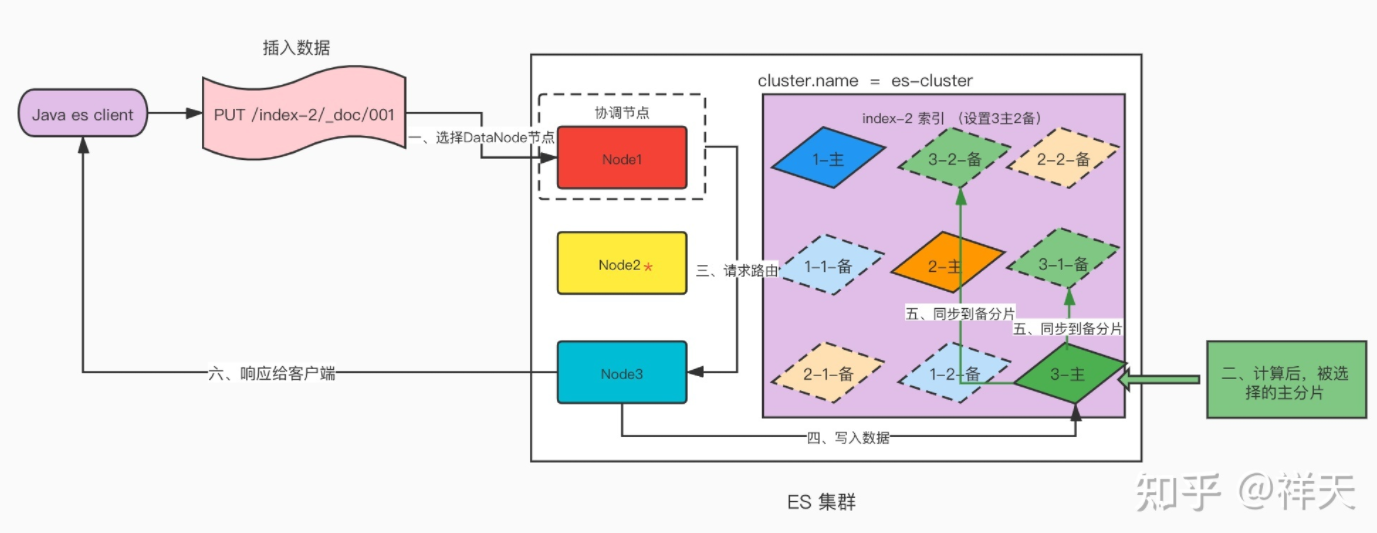
向 es 的节点发起文档写入请求(每个节点都可以接受请求),接收请求的节点 Node1 作为协调节点(cooridiniate)的角色。
根据文档的
_routing字段(若不指定,默认采用_id字段)采用路由算法计算文档存放的分片为分片 3 。javashard = hash(routing) % number_of_primary_shards由于分片 3 的主分片位于 Node3上,此时请求会转发到 Node3。
索引的分片数设置好之后不能修改。原因就在于修改分片数后不能通过路由算法找到原文档。
在Node3上将数据写入到分片 3 的主分片。写入成功后,会将请求转发给其余副本分片所在的节点,继续副本分片的写入。
所有分片写入成功之后,Node3 向协调节点报告写入成功,协调节点向客户端报告写入成功。
写入分片的流程
ES 写入数据到分片时的步骤:write -> refresh -> flush -> merge。
1. write
数据并不直接落磁盘,而是先写入内存缓冲区,同时写入日志文件 Translog。
注意,此时数据不能被查询到。
Translog作用
- 保证缓存中的数据不会丢失。
- 系统重启时,从 Translog 中恢复数据。
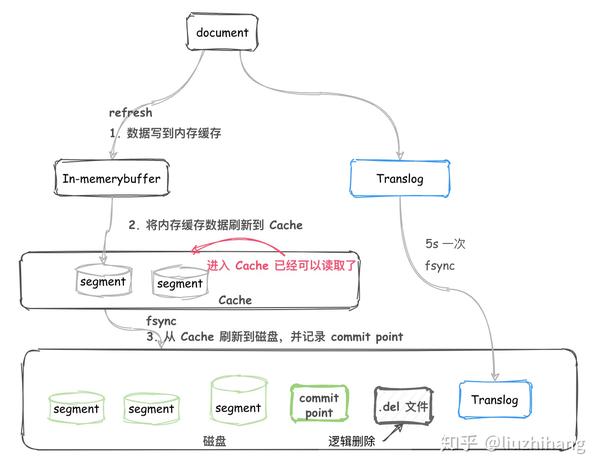
2. refresh
数据从内存缓冲区写入到新的 Segment 中。但是并不是真正写到磁盘上,而是写到了系统文件的缓存中,避免频繁的磁盘 IO操作。
写操作完成后,清空 Buffer,但是不会清空 Translog(最终写到磁盘)。
注意,写入 Segment后建立了倒排索引,数据此时可以被查询到。由此 es 并不是可以实时查询到,而是准实时的。
refresh 的时间间隔默认是 1s,可以通过修改配置项 index.refresh_interval 调整该值,减少性能的损耗。
如果对数据实时性,要求不高,可以适当调大该配置。比如 5s。
3. flush
随着 refresh 操作,Translog 会变得越来越大,当满足以下条件时,会触发 flush 操作。
- 达到限定时间,默认30分钟。
- 达到 Translog 文件限制大小,默认 512m。
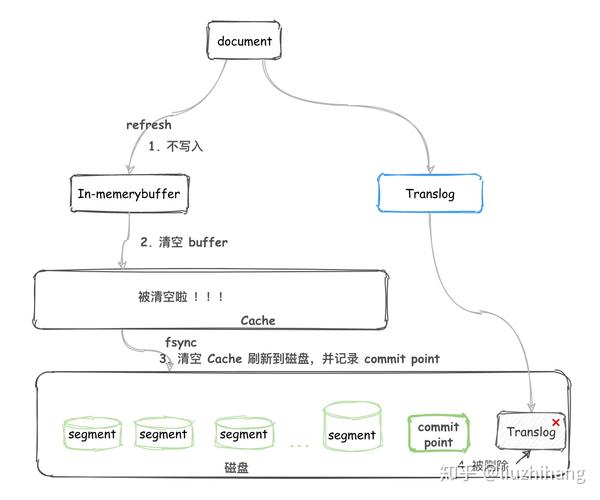
- 执行一次 refresh操作,将内存中的数据写到系统文件缓存中的 Segment。
- 将 commit point 写入磁盘,标明 所有的 segment。
- 文件系统缓存中的 Segment 被 fsync 刷到磁盘中。
- 清空并删除 translog,然后创建一个新的 translog。
清空 Translog 的原因是 Segment 也存入磁盘中了,此时 Translog 中的数据没意义了。
4. merge
每次 refresh 操作都会生成一个 Segment ,导致 Segment 越来越多(搜索分片时会搜索所有的Segment,会导致搜索变得越来越慢)。
es 后台有个线程会进行 Segment 的合并。
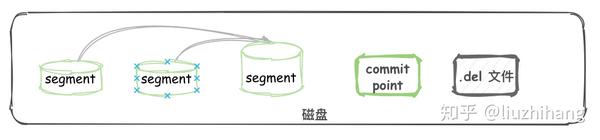
Elasticsearch 中的一个 shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,以保持索引大小并消除删除。
- 小的 Segment 合并成大的 Segment。
- 合并结束删除旧的 Segment。
- 更新 commit point 中的 Segment 信息。
- 新的 Segment 打开用来搜索。
在 merge 的过程中,会清理已经删除的数据。Segment 合并时,数据会根据 .del文件 过滤数据,.del文件包含的数据不会写入到新的 Segment中。
文档数据只有在 merge 这个阶段才被真正的物理删除掉。
Translog 日志文件
translog 中的数据仅在 translog 被 fsync编辑和提交时才会持久化到磁盘。如果发生硬件故障或操作系统崩溃或 JVM 崩溃或分片故障,自上次 translog 提交以来写入的任何数据都将丢失。
无论写入操作如何,translog 多久被fsync写入磁盘并提交一次。默认为5s. 小于的值100ms是不允许的。
是否fsync在每次索引、删除、更新或批量请求后提交事务日志。此设置接受以下参数:
request
(默认)
fsync并在每次请求后提交。如果发生硬件故障,所有确认的写入都已经提交到磁盘。async
fsync并在后台提交每个sync_interval. 如果发生故障,自上次自动提交以来所有确认的写入都将被丢弃。
index.translog.flush_threshold_size
translog 存储所有尚未安全保存在 Lucene 中的操作(即,不是 Lucene 提交点的一部分)。尽管这些操作可用于读取,但如果分片要关闭并且必须恢复,则需要重新索引它们。此设置控制这些操作的最大总大小,以防止恢复时间过长。一旦达到最大大小,就会发生刷新,生成一个新的 Lucene 提交点。默认为512mb.
index.translog.flush_threshold_period
在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作。默认是30m。