
Elasticsearch基础概念
基础概念
一、索引库(index)
Elasticsearch的索引库是一个逻辑上的概念,存储了相同类型的文档内容。类似于 MySQL 数据表,MongoDB 中的集合。
新建索引库
number_of_shards
设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同 的结点,提高了ES的处理能力和高可用性,入门程序使用单机环境,这里设置为 1。
number_of_replicas
设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为 0。
新建测试
例如新建一个 order 索引库,5 个分片,无副本。
javacurl --location --request PUT 'http://localhost:9200/order/' \ --header 'Content-Type: application/json' \ --data-raw '{ "settings": { "index": { "number_of_shards": 5, "number_of_replicas": 0 } } }'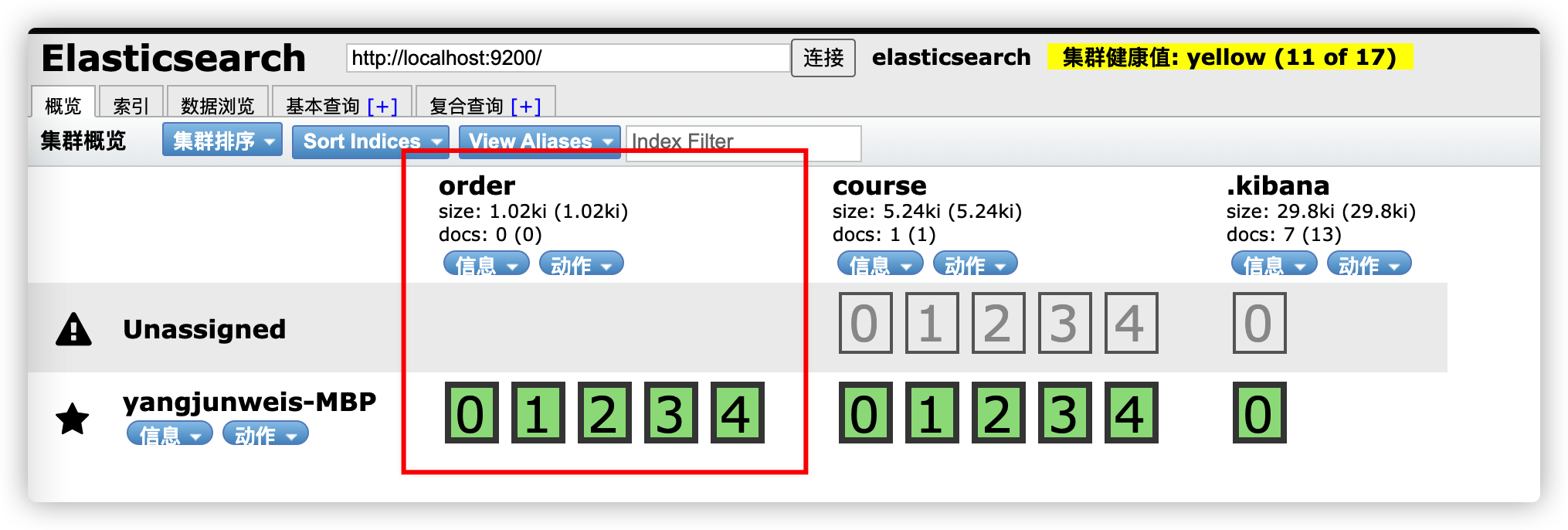
索引含义区分
索引(名词)
一个索引(index)对应一个索引库,就像是传统关系数据库 MySQL 中的数据库,是存储文档的地方。
索引(动词)
索引一个文档,代表将一个文档存储到索引库里,以便于文档被检索或者查询。
类似于 MySQL 中的
INSERT插入数据,不同的是索引会将旧文档覆盖。倒排索引
在传统数据库中为了提高查询效率,通常会为特定列增加索引来达到。
而在 Es 中采用了倒排索引的数据结构来提高查询效率。
二、类型(_type)
映射的元数据字段中的_type 字段。代表着索引的类型,每个文档中都会有_type字段信息进行区分文档。
Elasticse arch 官网提出的近期版本对 type 概念的演变情况如下:
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index 下只能存在一个 type;默认为 _doc;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。
为什么ElasticSearch要在7.X版本去掉type?
ES 最先的设计是用索引类比关系型数据库的数据库,用 mapping type 来类比表,一个索引中可以包含多个映射类别。这个类比存在一个严重的问题,就是当多个mapping type中存在同名字段时(特别是同名字段还是不同类型的),在一个索引中不好处理,因为搜索引擎中只有 索引-文档的结构,不同映射类别的数据都是一个一个的文档(只是包含的字段不一样而已)
三、映射(mapping)
映射定义索引中有什么字段、进行字段类型确认。类似于数据库中表结构定义。
元字段
每个文档都有与之关联的元数据,例如_index、_type和 _id 等字段。创建映射类型时,可以自定义其中一些元数据字段的行为。
| 元数据字段 | 含义 |
|---|---|
| _index | 文档所属索引 |
| _type | 文档映射类型(7.x 已废弃) |
| _id | 文档 ID |
| _source | 表示文档正文的原始 JSON |
Elasticsearch Guide [7.13]-Mapping-Metadata fields
映射方式
ES 支持手动定义映射和动态映射两种映射方式。
动态映射
默认情况下,当在文档中找到以前未见过的字段时,Elasticsearch 会将新字段添加到类型映射中。object 通过将
dynamic参数设置为false(忽略新字段)或设置为strict(在遇到未知字段时抛出异常),可以在文档和级别禁用此行为。(6.8 版本和 7.x 版本字段映射关系不同)。6.8 版本字段映射关系截图:

手动映射
可以通过 RestAPI 请求手动指定索引的映射。
javacurl --location --request POST 'localhost:9200/course/_mapping' \ --header 'Content-Type: application/json' \ --data-raw '{ "properties": { "name": { "type": "text" }, "description": { "type": "text" }, "studymodel": { "type": "keyword" } } }'
常用 API
索引映射
java//查看所有映射 curl --location --request GET 'http://localhost:9200/_mapping' //查看指定索引的映射 curl --location --request GET 'localhost:9200/{索引}/_mapping'创建映射
javaPOST localhost:9200/{索引名}/_mapping curl --location --request POST 'localhost:9200/course/_mapping' \ --header 'Content-Type: application/json' \ --data-raw '{ "properties": { "name": { "type": "text" }, "description": { "type": "text" }, "price": { "type": "long" } } }'更新映射
映射创建成功之后,已有字段不允许更新,可以添加新字段。
删除映射
通过删除索引来删除映射。
四、文档(documents)
ES 是面向文档的,搜索和索引数据的最小单位是文档。官方文档基础介绍。
文档是可以被索引的基本信息单元。例如,您可以为单个客户创建一个文档,为单个产品创建另一个文档,以及为单个订单创建另一个文档。该文档以 JSON(JavaScript Object Notation)表示,这是一种普遍存在的互联网数据交换格式。
在索引/类型中,您可以存储任意数量的文档。请注意,尽管文档物理上位于索引中,但文档实际上必须被索引/分配给索引内的类型。
ES 中的文档类似 MySQL 数据表中的记录。
ES 可以存储数据复杂的数据,而且每个数据还存在索引,便于搜索文档内容。)(关系型数据库存储数据结构复杂的数据时,先要打散数据存入数据库,再取出的时候往往需要拼接数据)
常用 API
创建文档
不指定Id的话,es 会自动创建 Id。
javaPOST http://localhost:9200/{索引名}/_doc/{id} curl --location --request POST 'http://localhost:9200/course/_doc' \ --header 'Content-Type: application/json' \ --data-raw '{ "name":"Java进阶", "price":120, "description":"Java yyds" }'更新文档
javaPOST http://localhost:9200/{索引名}/_doc/{文档Id} curl --location --request POST 'http://localhost:9200/course/_doc/q_PQW3oBBs5dY209hPKx' \ --header 'Content-Type: application/json' \ --data-raw '{ "name":"Java进阶", "price":130, "description":" updateJava yyds" }'删除文档
javaDELETE http://localhost:9200/{索引名}/_doc/{文档Id} curl --location --request DELETE 'http://localhost:9200/course/_doc/qvPHW3oBBs5dY2098vLu'搜索所有文档
javaGET http://localhost:9200/{索引}/_doc/_search curl --location --request GET 'http://localhost:9200/course/_doc/_search'根据文档Id查询文档
javaGET http://localhost:9200/{索引名}/_doc/{文档Id} curl --location --request GET 'http://localhost:9200/course/_doc/qvPHW3oBBs5dY2098vLu'搜索指定参数文档
javaGET http://localhost:9200/{索引}/_doc/_search?q={参数key}:{查询值} curl --location --request GET 'http://localhost:9200/course/_doc/_search?q=name:java'
五、数据类型
字符串类型
Elasticsearch 指南 [6.8] - 文本数据类型
字符串 string 可被分为 text 和 keyword 类型。若不为索引指定映射,6.x 版本的 es 会把字符串定义为 text类型,并增加一个keyword的类型字段。
- text
文本数据类型,该类型下字符串会被分词,并根据字符串内容生成倒排索引,便于查询。主要用于适合分词查询的场景。
analyzer
text类型支持分词,可通过 analyzer 属性指定分词器。
比如:指定参数的字段类型为text,设置 IK 分词器的分词模式。
java"name":{ "type":"text", "analyzer":"ik_max_word" }上边指定在索引(动词)和搜索的时候都进行细粒度分词。单独定义搜索时使用的分词级别可设置
search_analyzer属性。java"name":{ "type":"text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" }这里指定在索引的时候使用细粒度分词,在查询的时候使用粗粒度。(可提高查询精度)
index
可以通过设置 index 属性指定字段是否索引。
默认为
index = true,即都需要索引。设置字段需要索引,字段对应信息才会在索引库生成。当有些字段不需要索引时(图片,邮箱等),就可以通过设置 index 实现。
java"pic":{ "type":"text", "index":false }
keyword
关键字数据类型,该类型字符串不会被分词,主要用于准确匹配的字符串。比如身份证号、邮箱地址等。查询的时候只能根据完整字符串查询。
java"name":{ "type":"keyword" }
数值类型
Elasticsearch 指南 [6.8] - 数字数据类型
Elasticsearch 支持以下数字类型。

为了提高搜索效率,应尽可能选择范围小的数值类型。
选择浮点数的时候,尽量使用比例因子。
比如价格信息,单位为元,将比例因子设置为 100 的话 es 会按照分存储。比如输入价格23.123元,存入 es 中会按照 21134 存储。
java{ "price": { "type": "scaled_float", "scaling_factor": 100 } }选用比例因子的好处就是比浮点数容易计算,更容易压缩,节省磁盘空间。
日期类型
日期类型不用分词,通常日期类型用于排序等操作。
format
日期格式可以通过 format 自定义,但如果没有
format指定,则使用默认值:java"strict_date_optional_time||epoch_millis"这意味着它将接受带有可选时间戳的日期,这些时间戳符合
[strict_date_optional_time](https://www.elastic.co/guide/en/elasticsearch/reference/6.8/mapping-date-format.html#strict-date-time)或 纪元以来的毫秒数支持的格式。在设置字段的时候可以通过 format 设置日期格式。
java{ "properties": { "timestamp": { "type": "date", "format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd" } } }对应插入文档的参数为:
java{ "timestamp":"2018‐07‐04 18:28:58"}
六、分词机制
IK 分词器默认有两种分词模式,还支持自定义词库。
一种是粗粒度分词 ik_smart ,另一种是细粒度分词 ik_max_word。
粗粒度分词
设置 analyzer为ik_smart 会将文本进行粗粒度拆分。
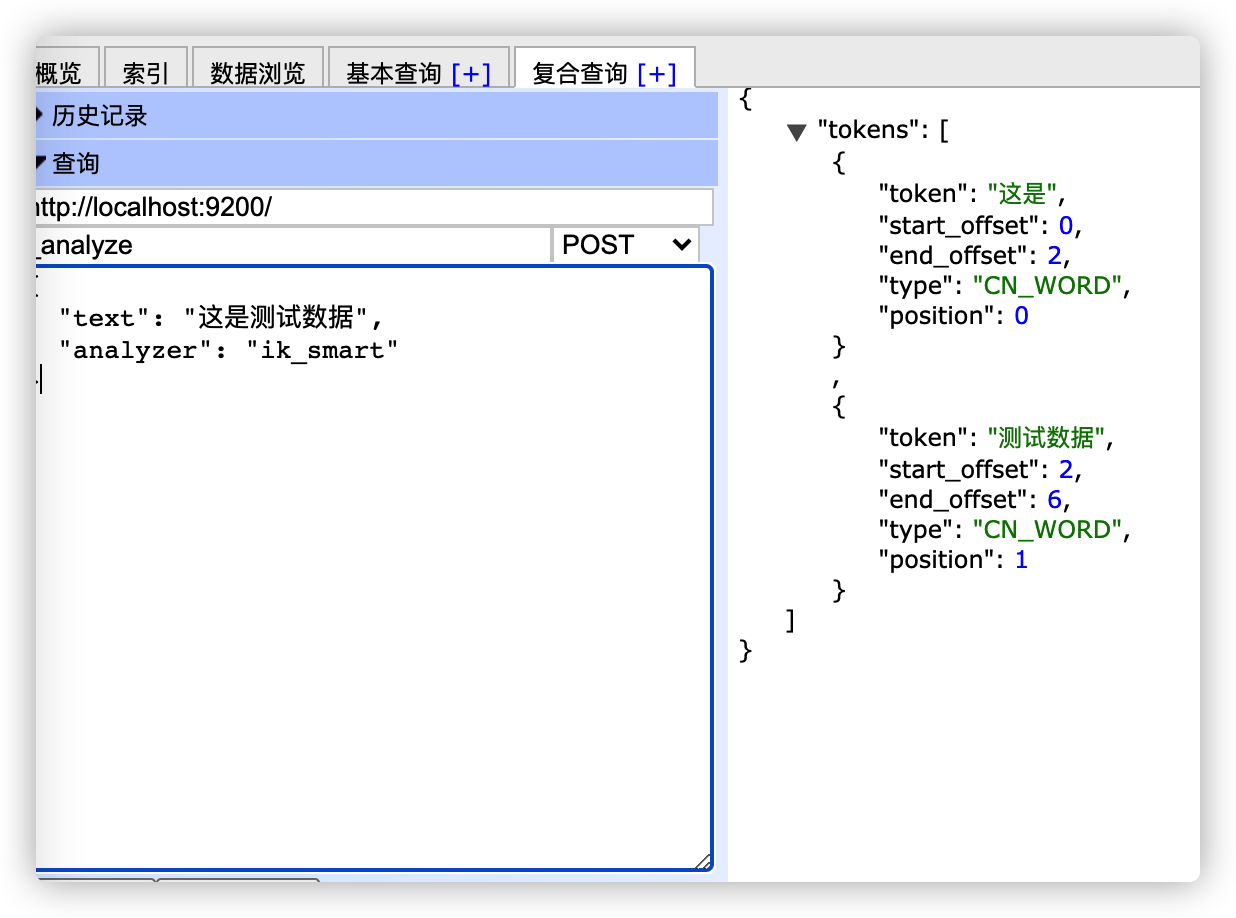
细粒度分词
设置 analyzer为 ik_max_word会将文本进行细粒度拆分。