
缓存问题
前言
在使用缓存的时候,简单的缓存处理流程如下。针对如下流程会遇到缓存穿透、缓存击穿、缓存雪崩等问题。
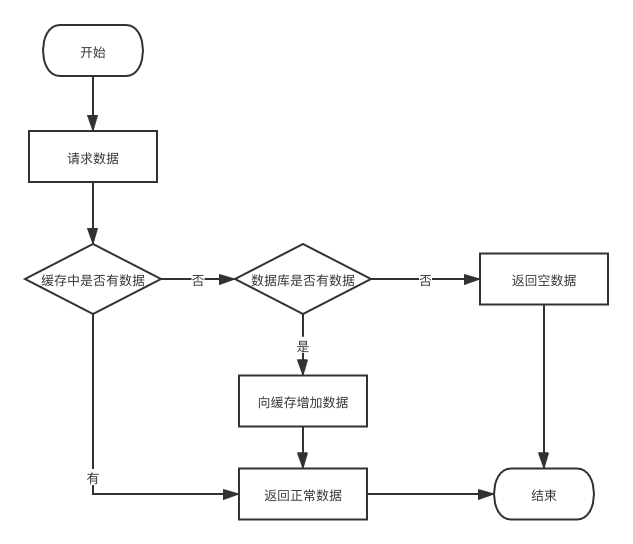
缓存穿透
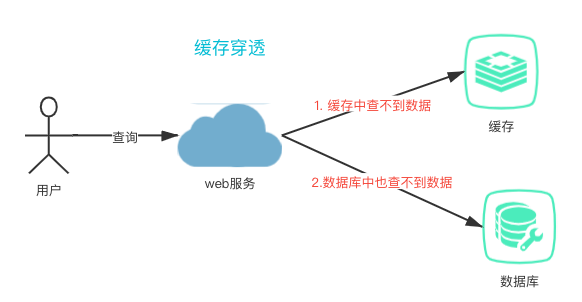
缓存穿透:当用户请求查询某个数据时,先从缓存查询,缓存中没有这个数据。然后向数据库查询数据,数据库中也没有这个数据,导致查询失败。
像一些恶意攻击时,故意查询数据库中不存在的数据,比如查询 id = -1 的数据,会造成数据库压力非常大。
解决方案
对空值做缓存。
当出现从缓存和数据库都查不到数据的情况时,可以将空值存到缓存中,即 K-V 存为 key-null,缓存过期时间可以设置短点,来防止短时间的频繁恶意攻击。
由于将空值存放到了缓存中,存在的问题:
- 缓存需要内存空间存放空值。
- 对空值设置了过期时间,导致缓存和数据库中的数据可能出现不一致的问题(数据库中有真实数据,而缓存中的空值数据未过期),不能保证数据一致性。
设置可访问 IP 的白名单,防止恶意攻击。
针对可能出现的恶意攻击情况,使用 bitmaps 存放白名单(可以访问的 IP 地址)。
存在的问题:
- 在每次查询之前,都需要判断是否在白名单中,影响效率。
使用布隆过滤器。
布隆过滤器是一种数据结构,能够很快的判断某个数据是否存在。
在查询数据之前,先从布隆过滤器判断数据是否存在,若存在,则继续从缓存开始查数据。若是不存在,则不继续查询。
存在的问题:
布隆过滤器存在误判的情况。
若布隆过滤器判断数据不存在,则一定不存在。
若布隆过滤器判断数据存在,则不一定存在。
布隆过滤器不支持删除元素。
缓存击穿
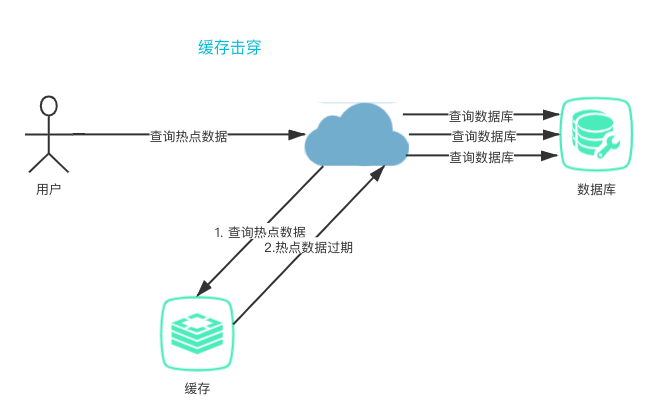
缓存击穿:当缓存中某个热点数据过期后,用户从缓存中查不到数据,然后去查询数据库,由于热点数据访问频率高,导致大量请求查询数据库,造成数据库压力过大,即发生了缓存击穿。
注意发生缓存击穿的时候,redis 是正常的,redis 中不会发生大量 key 过期的问题,只是数据库受到了很大的访问压力。
解决方案
设置热点数据永不过期。
预热热点数据。
在能够提前知道高并发情况时,预先延长热点数据的过期时间来避免缓存击穿。
使用互斥锁。
- 默认值的选择可以为缓存加逻辑过期时间,先检验逻辑过期时间是否过期,过期了就去抢锁。没抢到就返回旧缓存。
- 热点数据,QPS 高的情况下,其它线程不应该等待锁,应该直接返回默认值。
在高并发访问热点数据的情况下,若缓存中没有数据,对访问数据库数据并添加到缓存中的过程加锁。
比如 redis 的 setnx 或者 Redission。
javapublic String query(String key){ //1.从缓存查询数据 String result = getResultForCache(key); //2.缓存中没数据 if(result==null){ //获取锁 if(lock.tryLock()){ //从数据库查数据 result=getDataForMySQL(key); //添加到缓存中 setDataToCache(result); }else{ Thread.sleep(100); //没获取到锁的,睡眠100ms,再重新查询缓存 result=query(key); } } }逻辑过期时间
- 在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间。
- 当查询的时候,从redis取出数据后判断时间是否过期。
- 如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新的。
本地缓存缓冲。
- 本地缓存和 redis 缓存时间不一致。
- 通过热点数据探测,更新本地缓存,延长redis缓存过期时间。
本地缓存+cache
针对热点数据的缓存击穿问题,可以通过二级缓存解决。
一般来说引入 Redis 作为缓存是可以满足要求的。但是对于热点数据和高访问的情况下,redis可能会成为性能瓶颈。
比如 redis 缓存过期导致的缓存雪崩、或者 redis 宕机等问题,引入本地缓存便可以有效避免这种问题。
但是要注意本地缓存和 redis 缓存过期时间要不一致。
添加本地缓存,做二级缓存。
本地缓存和 redis 缓存过期时间不一致。(热点探测服务检测热点数据加到本地缓存)
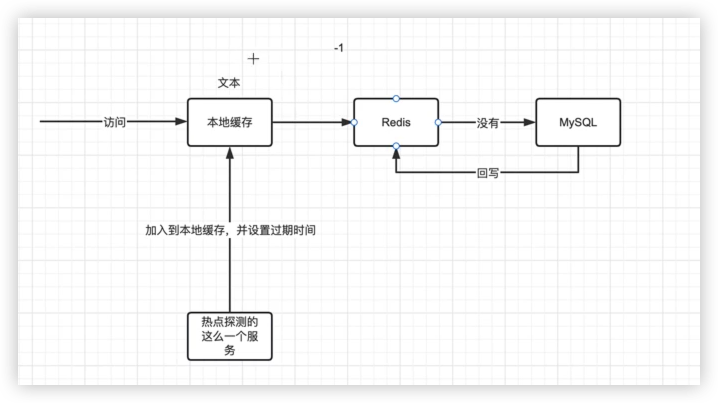
延长缓存过期时间
热点探测服务发现热点数据时。
- 将缓存数据写入本地缓存。
- 同时延长 redis 中缓存的过期时间。
优点
Redis 加本地缓存(通常指应用服务器内存中的缓存,如Guava Cache、Caffeine等)形成的二级缓存架构,主要用于解决以下几类问题:
- 减轻Redis压力:当应用对缓存的读取非常频繁时,部分读请求可以直接在应用本地缓存中命中,无需每次都经过网络请求到Redis,减少了Redis服务器的访问压力。
- 降低网络延迟:本地缓存位于应用服务器的内存中,相比于远程访问Redis,本地缓存的访问速度极快,几乎无网络延迟,提高了数据读取的响应速度。
- 提高系统稳定性:即使Redis服务出现短暂故障或网络分割,应用仍能通过本地缓存继续服务,提高了系统的可用性和韧性。
- 应对Redis性能瓶颈:当Redis成为系统瓶颈时,二级缓存可以分担一部分读取压力,尤其是在大流量、高并发的场景下,能够显著提升系统处理能力。
- 减少成本:虽然Redis已经非常高效,但在大规模部署时,硬件资源和运维成本仍然是考虑因素。本地缓存能在一定程度上减少对Redis集群规模的需求,从而节省成本。
- 数据热点问题:对于访问极为频繁的热点数据,本地缓存可以更有效地缓存这部分数据,减少Redis中相同数据的重复访问。
- 优化复杂查询:对于需要聚合、排序等复杂操作的数据,可以在首次从Redis或数据库获取后,将结果存储在本地缓存中,后续直接使用缓存结果,减少计算和数据传输的开销。
Redis 加本地缓存的二级缓存策略,旨在通过多层次的缓存机制,进一步提升数据访问速度,增强系统的稳定性和伸缩性,同时优化资源利用和成本。
缓存雪崩
缓存雪崩:在短时间内,缓存中的大量 key 集中过期,导致大量请求去查询数据库,导致数据库压力过大。
解决方案
锁或者队列。
在高并发情况访问缓存时,增加锁或者队列,来确保同一时间不会有多个线程同时访问缓存。
加锁或队列是一种治标不治本的方式,虽然能够解决缓存雪崩的问题,但是没有提高系统吞吐量,在高并发情况下,阻塞问题严重。而且若是在分布式环境下,需要使用分布式锁,导致系统效率大大降低。
将缓存失效时间分散。
在设置缓存失效时间时,增加随即因子,保证失效时间的随机性,减少大量 key 集中过期的问题。
设置缓存永不过期。
设置缓存永不过期需要更多的内存空间。
缓存一致性解决
双写模式
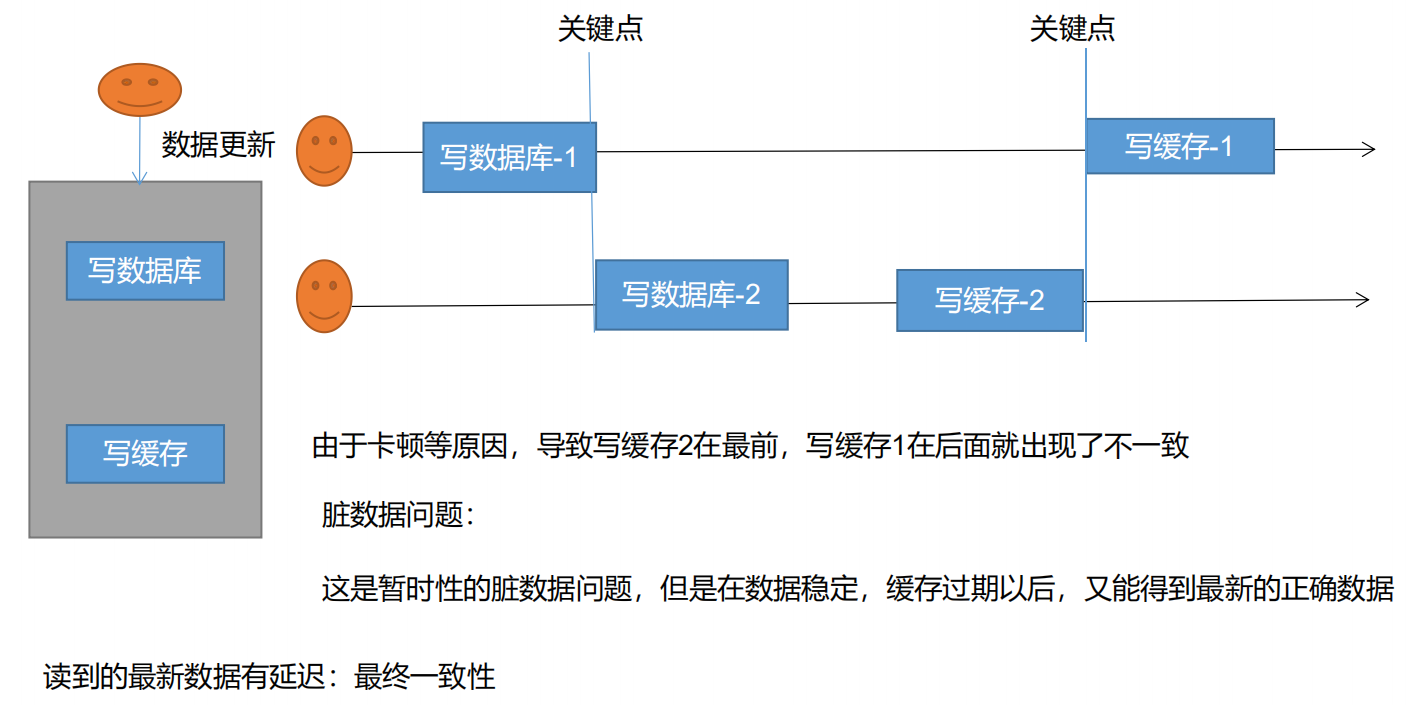
数据更新的过程 进行写数据库和写缓存。
存在并发问题。
并发情况,存在脏数据问题。多个线程写同一个 key 时,容易冲突。
失效模式
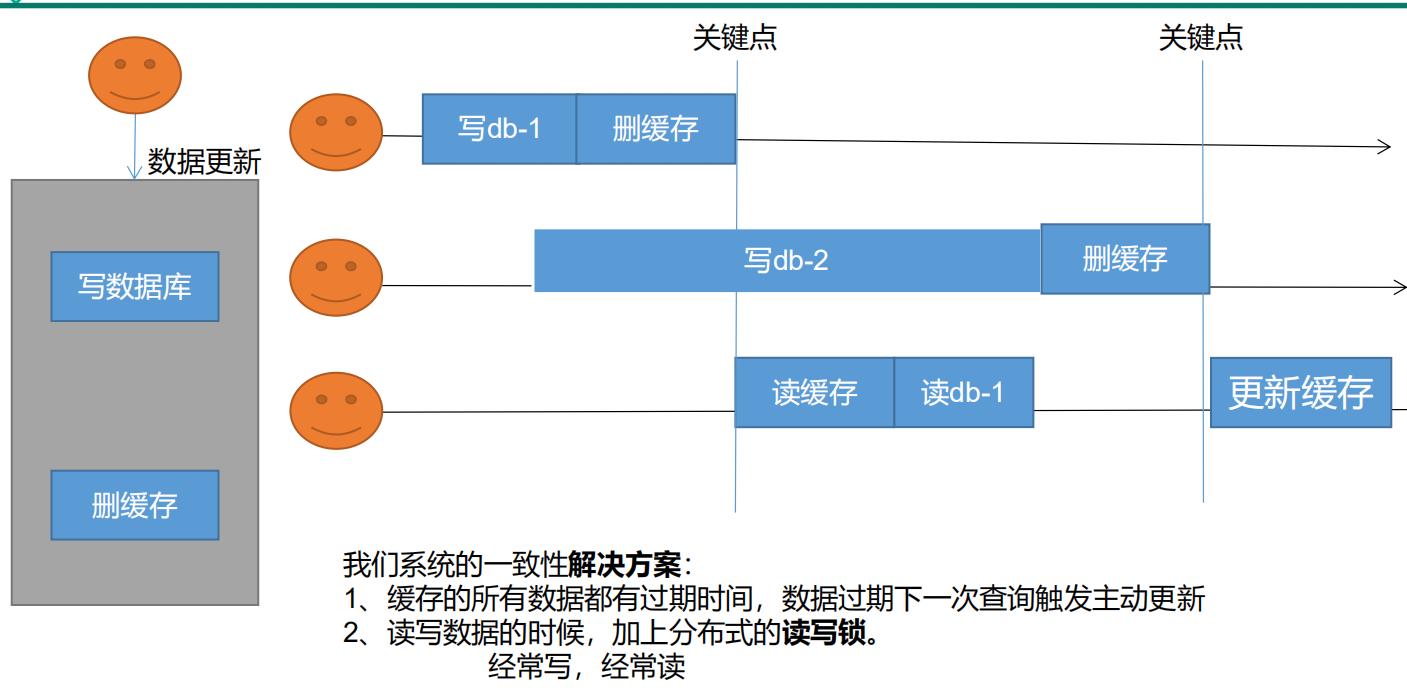
在数据更新的时候,写数据库,然后删除缓存。
更新完成之后,缓存中没有数据,数据库里是最新的数据。在下次查询的时候查询缓存中发现没数据,再去查 DB 更新缓存。
并发场景同样存在数据不一致问题。而且这种情况请求很容易打到DB。
异步更新缓存
先更新数据库,再更新缓存。
- 通过 canal 订阅 binlog
- 引入消息队列,通过消息队列排队更新缓存。
延时双删
先删除缓存
更新数据库
延时再删除缓存(200ms)
解决更新过程其它读请求导致的旧数据。其它读请求读缓存没数据,加载 DB里面的旧值。
读取最新的数据有延迟,只能保证最终一致性。
过期时间
给缓存加过期时间,过期之后重新加载就是最新的,也能保证最终一致性。
结论
无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办? 1、如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可 2、如果是菜单,商品介绍等基础数据,也可以去使用 canal 订阅 binlog 的方式。 3、延时双删+过期时间也足够解决大部分业务对于缓存的要求。 4、通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性。
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。