
布隆过滤器
1. 什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种数据结构,用来判断一个元素是否在一个集合中。布隆过滤器的本质上使用的是二进制向量和 k 个哈希函数组成。
布隆过滤器具有如下优点:
空间利用率高。
布隆过滤器底层使用二进制向量保存数据,不需要保存元素本身,只需要在指定 bit 存放标识即可,故空间利用率非常高。
int 类型占用四个字节,对应 4*8 个 bit,对比能存放 32 个数据。(注意存放的不是元素本身)
时间效率也较高,插入和查询效率高。
布隆过滤器的时间复杂度只跟哈希函数的个数 k 有关,插入和查询的时间复杂度均为 O(k);
结合布隆过滤器原理的数据结构理解效率高的原因。
同样的,布隆过滤器也存在一些缺点。
存在一定程度的误判。
布隆过滤器主要作用是用来判断一个元素是否在一个集合中,但是存在一定的误判率。
若布隆过滤器判断数据不存在,则一定不存在。
若布隆过滤器判断数据存在,则不一定存在。
不支持删除集合中的元素。
布隆过滤器不支持删除元素。
针对删除元素的优化可见:Counting Bloom Filter 的原理和实现
2. 为什么使用布隆过滤器?
解决缓存穿透
布隆过滤器一个经典的应用场景就是用来解决缓存穿透。
缓存穿透:当用户请求查询某个数据时,先从缓存查询,缓存中没有这个数据。然后向数据库查询数据,数据库中也没有这个数据,导致查询失败。
布隆过滤器在 redis 中解决缓存穿透的应用流程:
- 在向缓存中添加数据时,同时向布隆过滤器插入数据。
- 在向缓存查询数据时,先查询布隆过滤器,判断是否存在数据。
- 若布隆过滤器中存在,再查询缓存。
- 若布隆过滤器不存在数据,则不再继续向下查询。
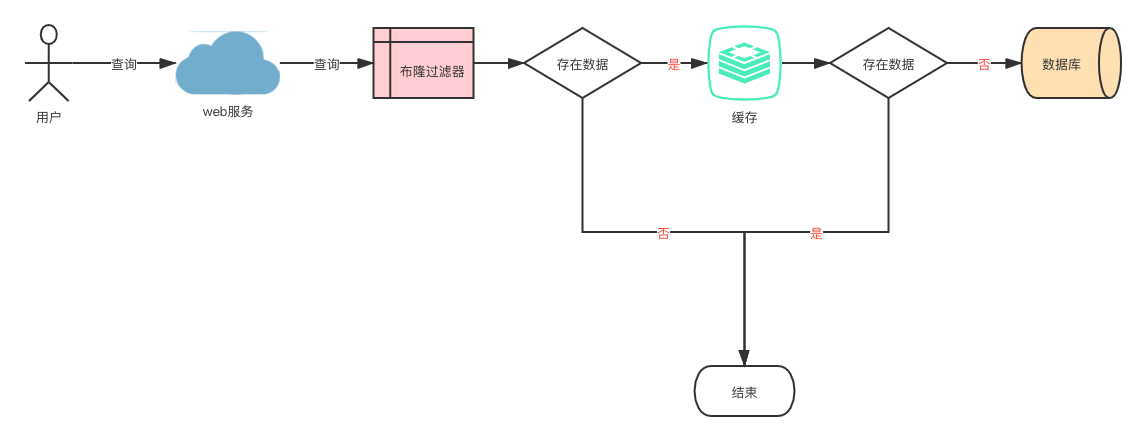
结合布隆过滤器的特点,当判断出数据不存在于布隆过滤器时,缓存中一定不存在该数据。就能解决缓存穿透的问题,减少无效请求访问缓存和数据库。
其他应用场景
布隆过滤器除了能够解决缓存穿透的问题之外,还有很多的应用场景。但是前提是这些应用场景能够接受布隆过滤器带来的一定误判率的影响。
判断用户名是否重复。
只有当布隆过滤器判断用户名不存在时,才可以使用当前用户名。
垃圾邮件问题。
当判断邮件为垃圾邮件时(经过哈希函数指定位设置为 1)。
布隆过滤器判断出邮件不是垃圾邮件时,那该邮件一定是正常邮件。
布隆过滤器判断出邮件是垃圾邮件时,该邮件有可能是正常邮件。存在正常邮件被识别为垃圾邮件的情况,这个时候可以选择为误判邮件增加白名单来解决。
3. 布隆过滤器的原理
数据结构和存储原理
布隆过滤器底层由 bit 数组和 k 个哈希函数组成,bit 数组每个位上均初始化位 0,所有哈希函数尽量保证均匀分布。
- 哈希函数用来计算,计算存入的数据映射到 bit 数组的位置。
- bit 数组用来存放数据经过哈希函数映射的结果,指定位数值为 1。
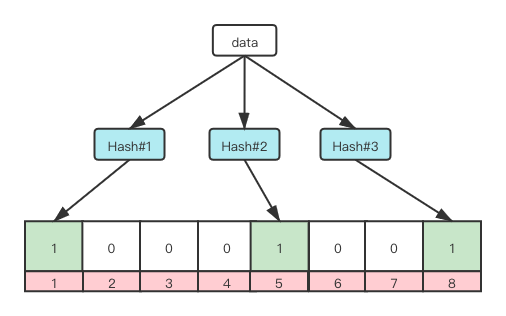
存储原理
- 插入元素时,分别使用多个哈希函数计算元素,得到哈希函数计算结果,对应 bit 数组中的位次。
- 根据得到的位次,将 bit 数组中指定位次设置为 1。
查询原理
- 根据查询元素,分别使用多个哈希函数计算,得到计算结果。
- 根据计算结果查询 bit 数组指定位次,若结果都为 1,则认为元素存在,若有一个位次值为 0 ,则认为元素不存在。
为什么会存在误判?
因为布隆过滤器的存储机制,简单概括为:插入元素经过不同的哈希函数计算,得到不同的位置,并将位数组指定位次设置为 1。
假设存在 A 和 B 两个元素,布隆过滤器中有三个哈希函数,A 和 B 经过哈希函数的结果相同。A 插入到布隆过滤器中,B 不存在布隆过滤器中。
当判断 B 是否存在于布隆过滤器时,经过三个哈希函数的结果,得到位数组指定位上值为 1,由此判断 B 存在于布隆过滤器中。但实际上 B 并没有插入到布隆过滤器中,这时就发生了误判。
误判的原因可以归结为:当插入的元素很多的情况下,某个元素即使之前不存在,但是它所映射的 k 位已经被之前其他的元素置为 1 了,这样就会出现误判,BloomFilter 会认为它已经存在了。
误判率
简单来说,误判率受到哈希函数个数和位数组长度的影响。要求误判率越低意味着需要的哈希函数和位数组长度越多。当误判率低的时候,新增查询元素的时候效率相应会降低。当误判率高的时候,效率相对会高一些。
为什么不支持删除?
如果删除布隆过滤器中的元素,会对后续结果产生误判的影响。
若要删除元素,首先将元素经过多个哈希函数计算,得到指定位次,并将位数组指定位设置为 0。但是由于位数组的每个位可能被多个元素指定,若某个位被修改为 0,其它存在于布隆过滤器中并指向该位的元素会被判断不存在,产生了误判。
比如 C 和 D 元素,C经过三个哈希函数的结果为 1、4、7,D 的结果为 1、5、8,当删除 C 时,1、4、7位对应值为 0 。此时查询 D ,对应 1、5、8 位置为 0、1、1,得到 D 元素不存在的结果,发生了误判。
Counting Bloom Filter 是一种优化数据结构,支持删除。
4. 怎样使用布隆过滤器
Guava
引入依赖
java<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>27.1-jre</version> </dependency>创建布隆过滤器
java//布隆过滤器存放数据类型,预期插入数据长度,误判率 BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.1);测试代码
javapublic class UserLoginService { public static void main(String[] args) { int size = 10000; //布隆过滤器存放数据类型,预期插入数据长度,误判率 BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,0.1); //插入0~10000 for (int i = 0; i < size; i++) { bloomFilter.put(i); } for (int i = 0; i < size; i++) { if (!bloomFilter.mightContain(i)) { System.out.println("用户登陆过但是布隆过滤器没有判断出来"); } } int count = 0; //10001~13000 for (int i = 10001; i < size + 3000; i++) { if(bloomFilter.mightContain(i)){ count++; } } System.out.println("3000个元素发生误判的个数:"+count); } } //output 3000个元素发生误判的个数:301
Redis实现布隆过滤器
redis 默认不支持布隆过滤器,需要安装插件。
Centos7 Redis5 BloomFilter 安装及使用
参考链接
布隆过滤器(Bloom Filter)原理及Guava中的具体实现
Linux安装布隆过滤器过程中make编译报错“fatal error:tdigest.h:没有那个文件或目录”处理指南