
redis数据类型原理
- linkedlist (双向链表)
- 当列表元素较多或元素大小超过一定阈值时,Redis 会使用双向链表来存储
list键。 - linkedlist 是一种指针结构,每个节点包含指向前后节点的指针,这使得插入和删除操作非常高效。
- linkedlist 的优点是支持高效的插入和删除操作,但缺点是比 ziplist 更占用内存。
- 当列表元素较多或元素大小超过一定阈值时,Redis 会使用双向链表来存储
全局哈希表
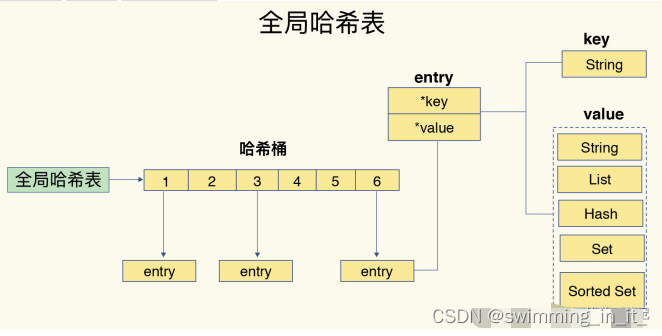
Redis是一个 K-V 数据库,有一个全局的哈希桶存放所有的 key。
key 对应的 entry 包含了实际的 key 和 value。这里的 value 对应着不同的数据类型。
- 高效查找:能根据 key 计算 hash 值,快速找到对应的键。
- **快速插入和删除:**哈希加链表的结构,插入删除很快。
链式哈希
哈希表发生冲突之后,采用拉链法。
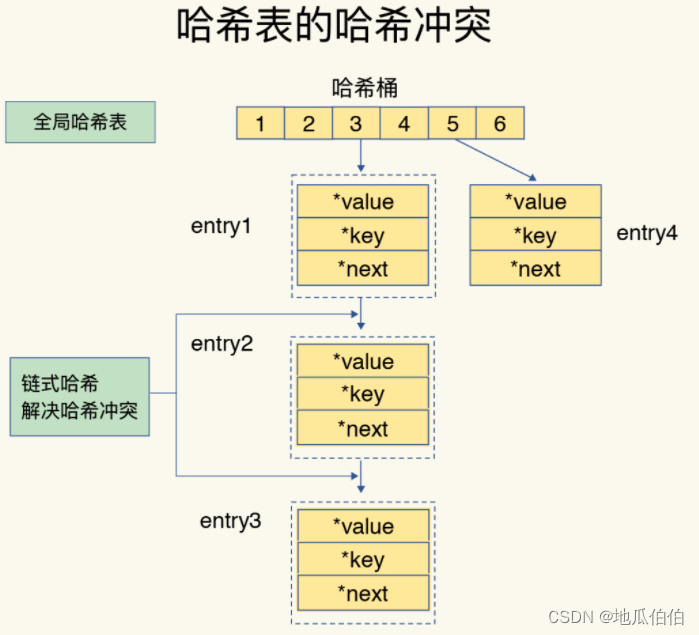
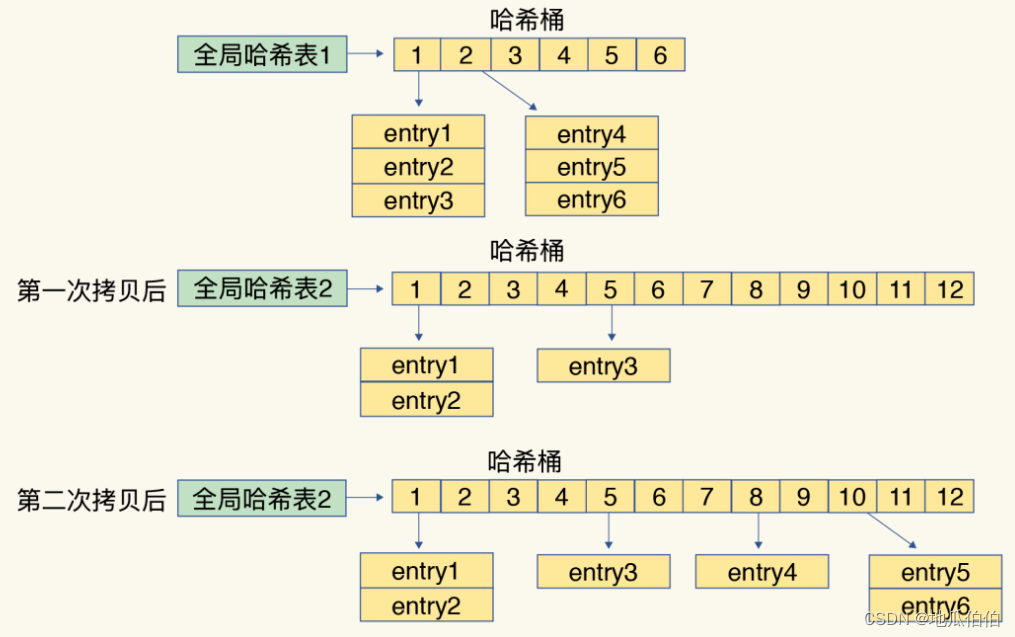
渐进式rehash
rehash是指重新构建哈希表的过程。当哈希表中的键值对数量与哈希表的大小比例不合适时,redis会进行rehash。
但是一次将全部键rehash,比较耗资源,容易造成阻塞。
redis采用的是渐进式rehash,将单次rehash的过程分为多次。
这种方法将rehash操作分成多个小步骤,每个步骤只迁移一小部分键值对。这样,Redis可以在处理客户端请求的同时,逐步完成整个rehash操作。渐进式rehash通过维护两个哈希表(一个旧的和一个新的)并在处理客户端请求时逐步迁移键值对来实现。
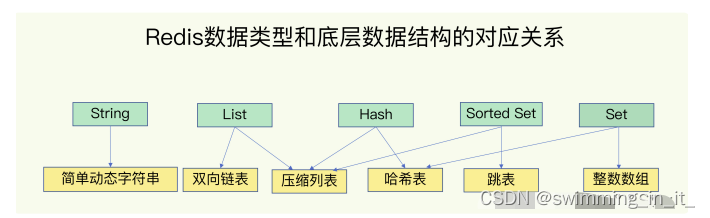
底层数据结构
SDS-简单动态字符串
String 的数据结构是简单动态字符串(Simplie Dynamic String,SDS),是可以动态修改的字符串,类似 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
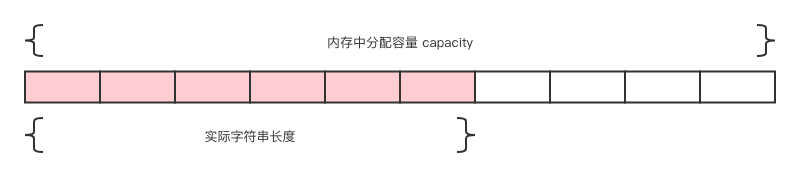
内存中分配给当前字符串的容量 capacity 一般要高于实际字符串长度。
- 当字符串长度 < 1MB 时,扩容时当前空间加倍。
- 当字符串长度 > 1MB 时,扩容时一次增加 1MB 的空间。
- 字符串最大限制长度为 512MB。
链表
双端无环链表。
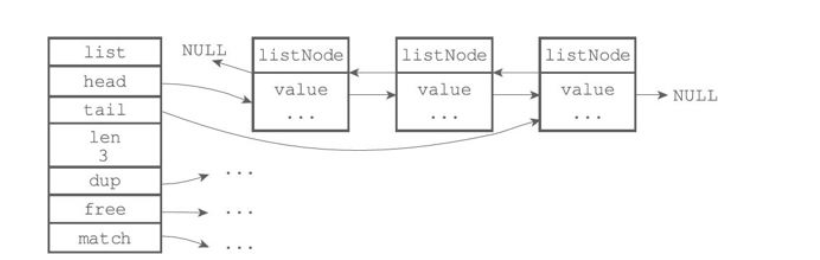
应用场景
链表是list键的底层实现之一,当一个列表键包含了数量比较多的元素,又或者列表中保存的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
字典
Redis 的字典使用哈希表作为底层实现。
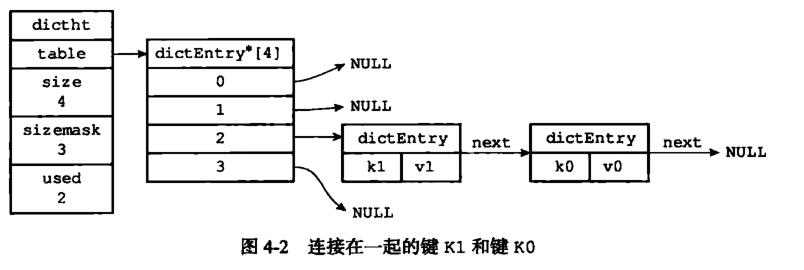
字典使用哈希表,同样会有哈希冲突的问题。
一般解决哈希冲突的方式有几种:
- 开放地址法
- 拉链法
- 再哈希
这里还是使用了拉链法。在达到阈值之后出发 rehash,但是redis不会一次性全部rehash,采用了渐进式rehash,减少因为rehash造成的资源阻塞问题。
跳表
跳表是一种有序的数据结构,类似于平衡树,但是实现更简单。
跳表每个节点维护多个指向其它节点的指针,从而达到快速访问节点的目的。
跳表的时间复杂度是平均 O(logN),但是最坏是 O(N)。
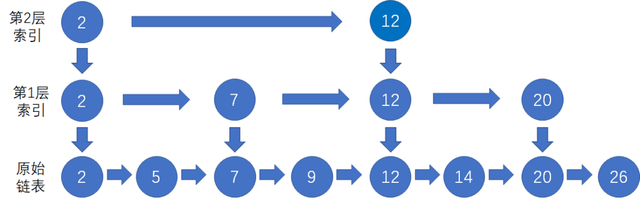
搜索过程:
- 从最高层开始查询,比如查找9。
- 判断是否比最高层头节点大是否比头节点的下一个节点大?
- 比下一个节点小,则向下查找。
- 比下一个节点大,则向右查找。
- 重复搜索,直到最后一层。
应用场景
redis使用跳跃表作为有序集合键的底层实现之一,如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳表来作为有序集合键的底层实现。
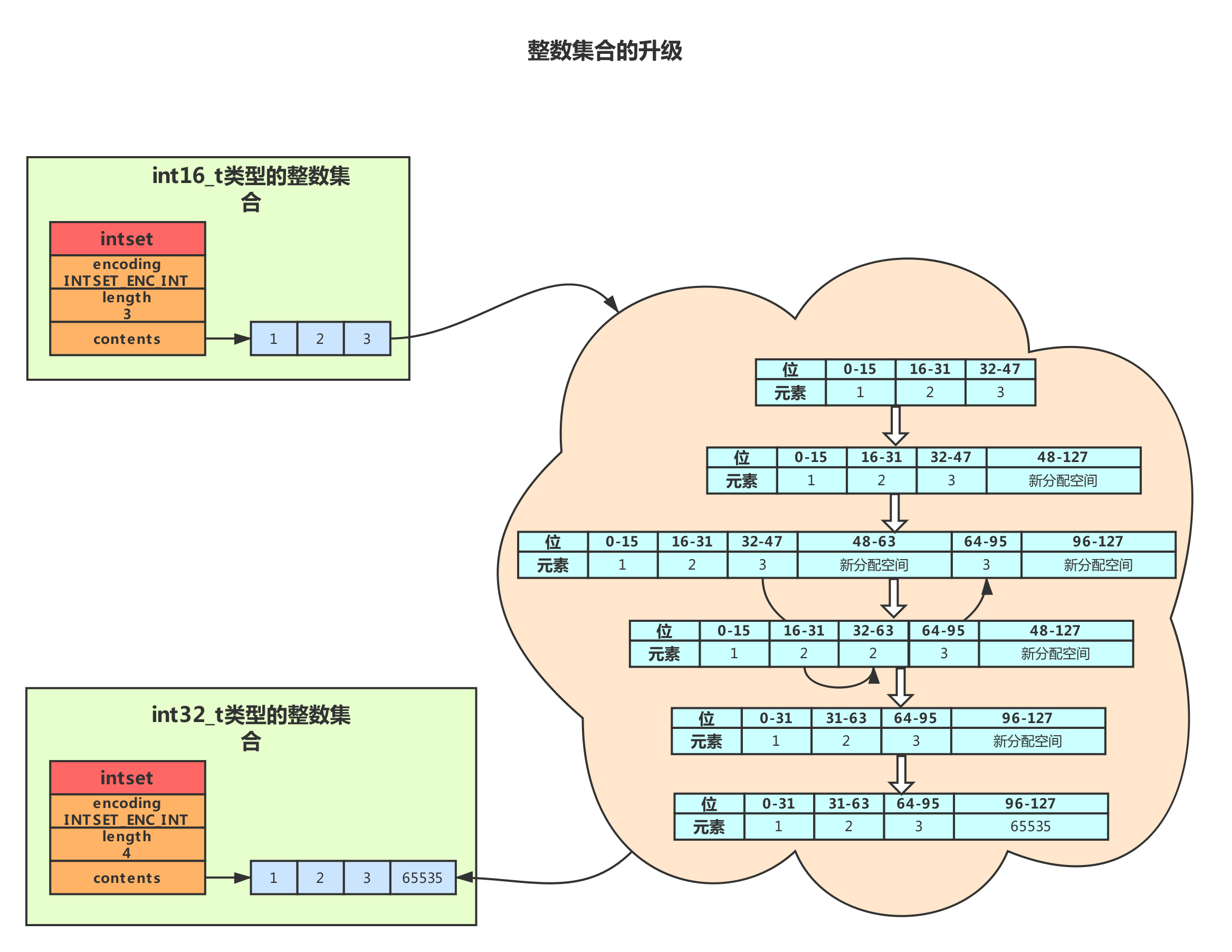
整数集合
整数集合是集合键的底层实现之一。
当一个集合只包含整数值元素,并且元素数量不多的时候,Redis会使用整型集合作为集合键的实现。
整数集合的底层实现为数组,这个数组以有序,无重复的方式保存集合元素,在有需要时,程序会根据新添加元素的数据类型,改变这个数组的数据类型(升级操作)。
整数集合只支持升级,不支持降级。
int16_t → int32_t → int64_t
应用场景
整数集合是 列表 键的底层实现之一。
压缩列表
压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
压缩列表的原理:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。

应用场景
压缩列表时列表键和哈希键的底层实现之一。
- 当一个列表键只包含少量列表项,并且每个列表项都是小整数值或长度较短的字符串时
- 当一个哈希键只包含少量的键值对,并且每个键值对都是小整数值或长度较短的字符串时。
压缩列表只适用于数据少的情况,因为除了头尾,其它元素查找都是 O(N)。仅仅是为了节省内存将元素紧凑的放到了一起。
快速列表
quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
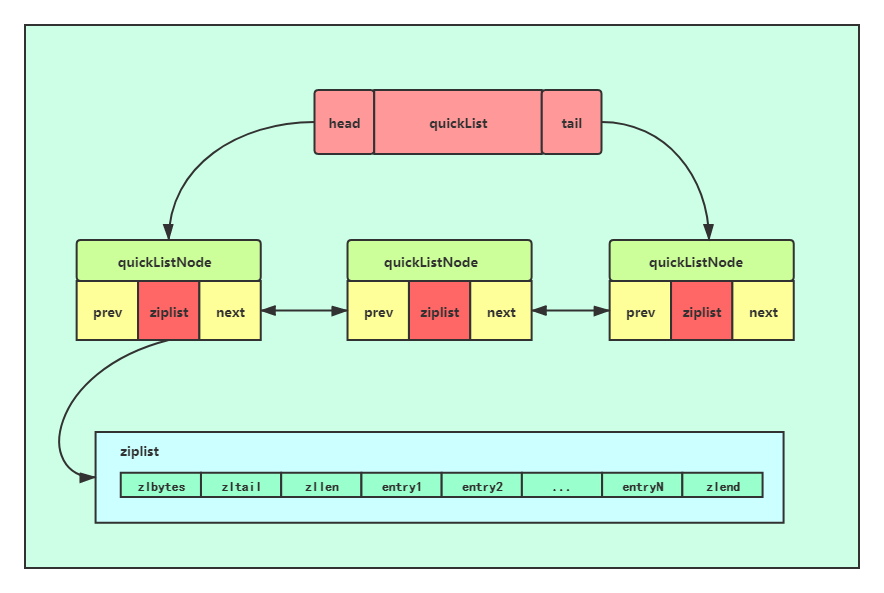
- 每个ziplist有队头和队尾
- 既拥有了链表的查询优点,又拥有压缩列表对内存的优化。
数据格式对应数据结构
list
3.2版本之前
压缩列表+链表
- 当列表元素长度较小,数量较少时,采用压缩列表(zipList)来存储。
- 当列表元素大于512,或者元素长度大于64时。使用链表。
- 支持快速删除和插入。
- 暗示内存利用率低,因为需要额外的内存空间维护链表结构(双向无环链表)。
3.2版本之后
快速链表:压缩列表+链表的结合体。
quicklist 是一个双向链表的复合结构体。quicklistNode 让它拥有链表的查询优点;ziplist 让它在内存使用上有着相对链表可以节省大量前后指针的优势。
但是需要合理的配置节点中 ziplist 的 entry 个数。entry 过少,则退化成普通链表。entry 过多,则会放大 ziplist 的缺点。