
Java工程师成长计划-高并发
_______________________________________________
| _ __ __ |
________| | | /| / / ___ / / ____ ___ __ _ ___ |_______
\ | | |/ |/ / / -_) / / / __// _ \ / ' \/ -_) | /
\ | |__/|__/ \__/ /_/ \__/ \___//_/_/_/\__/ | /
/ |_______________________________________________| \
/__________) (__________\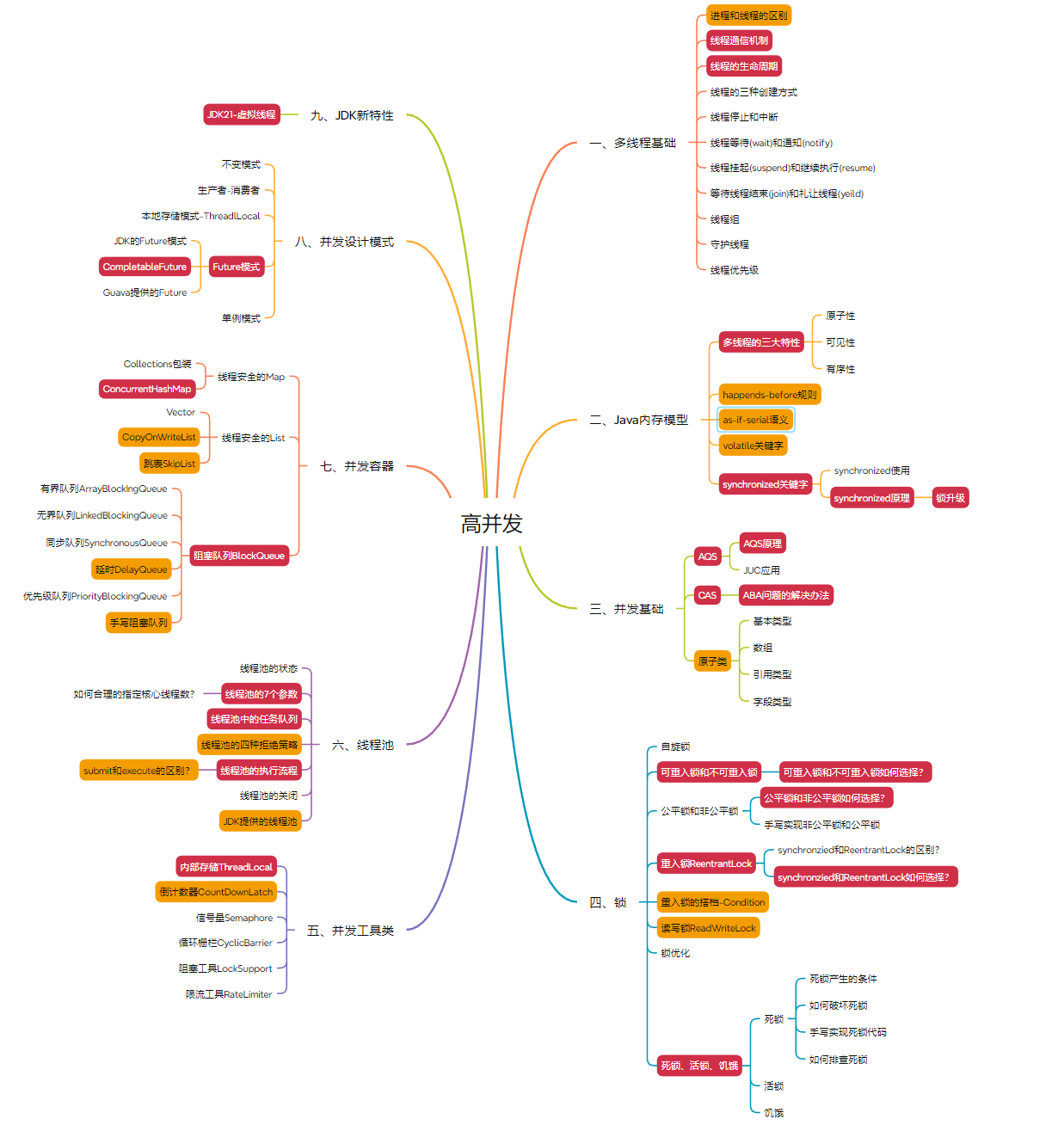
一、多线程基础
进程和线程的区别
一个程序至少有一个进程,一个进程至少有一个线程。
进程:指在系统中正在运行的一个应用程序;程序一旦运行就是进程;从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的基本单位,进程是系统进行资源分配和调度的基本单位。
线程:线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
线程的生命周期
线程的三种创建方式
Thread
不推荐使用。
Java是单继承,所以不推荐使用继承来实现并发类。 注意:直接调用run()方法,相当于调用了该方法,没有开启新线程。只有调用start()方法,才是开启了一个新线程和主线程争夺资源。Ruunable
推荐使用。没有结果返回,可以作为 Thread 类的参数创建线程,也可以与线程池捆绑使用。
- Callable
推荐使用,有结果返回。可与 FutureTask 搭配使用,也可以与线程池捆绑使用,搭配 Future 获取任务执行完成的返回值。
线程停止和中断
线程停止
stop()方法 (不推荐使用)stop()方法被调用的时候,会直接释放线程拥有的锁对象,这样会破坏临界区的原子性。stop()方法的优化 优化stop()方法,在调用时不直接释放锁资源,保证临界区资源执行完成后再释放锁资源。
中断方法
线程中断并不会立即将线程退出,而是发出一个中断信号。目标线程接收中断信号后,如何退出由目标线程的逻辑决定。
Java中Thread类提供了关于线程中断的三个方法:interrupt(): 中断线程。
isInterrupted(): 判断线程中断的状态。interrupted(): 判断线程中断的状态,并重置中断标志。实际是调用了isInterrupted()方法,并传入中断标志数据。
线程等待(wait)和通知(notify)
wait() 方法和 notify() 方法是 Object 类里的方法,意味着任何对象都可以调用这两个方法。
wait()方法使用时会释放锁对象,进入等待。notify()会随机唤醒一个等待的线程,被唤醒的线程会重新竞争锁对象。- 还有一个方法
notifyAll(),会唤醒所有进入等待的线程。
注意:不论是 wait() 方法还是 notify() 方法,都需要获取锁对象才能调用。
扩展知识
Thread.sleep()方法和Object.wait()一样也可以让线程等待,而sleep()可以指定等待时间,wait()可以被唤醒。还有一个主要区别,wait()会释放目标对象的锁,而sleep()不会释放任何资源。Lock有一个好搭档Condition实现的功能和wait和notify基本一致,只不过Condition依赖于Lock。
线程挂起(suspend)和继续执行(resume)
常用方法
suspend()会阻塞当前线程,但是不会释放锁对象。(不推荐使用,推荐使用并发工具 -LockSupport)resume()会取消当前线程的阻塞状态。
注意:Thread.suspend() 阻塞当前线程时,不会释放锁对象。若不调用 resume() 方法,或者在 suspend() 方法调用之前调用了 resume() 方法,则该线程会一直持有锁对象,进而造成死锁。
等待线程结束(join) 和 礼让线程(yeild)
join(): 等待调用线程执行结束。
源码分析
join() 实际上是调用了 wait() 方法,在当前线程实例上实现了线程等待。而线程在执行完成之前会调用 notifyAll() 方法通知等待线程继续执行。
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
//通知本地方法实现线程等待
public final native void wait(long timeout) throws InterruptedException;yeild()方法:让出线程资源,但是会重新竞争。
线程组
可按照功能将不同线程进行分组。
守护线程
守护线程是一种特殊的线程,会在所有的用户线程执行完成之后,随之结束。
线程优先级
可以为线程设置优先级,在线程之间抢占资源时,线程优先级越高,机会越大。
Thread highThread = new Thread(new HignPriority());
Thread lowThread = new Thread(new LowPriority());
//设置优先级
highThread.setPriority(Thread.MAX_PRIORITY);
lowThread.setPriority(Thread.MIN_PRIORITY);线程优先级默认为 5 ,最大为 10,最小为 1。
/**
* The minimum priority that a thread can have.
*/
public final static int MIN_PRIORITY = 1;
/**
* The default priority that is assigned to a thread.
*/
public final static int NORM_PRIORITY = 5;
/**
* The maximum priority that a thread can have.
*/
public final static int MAX_PRIORITY = 10; __ __ _______ __ __ ______ .___________. __ __ .______ _______ ___ _______ .______ ______ ______ __
| | | | | ____|| | | | / __ \ | || | | | | _ \ | ____| / \ | \ | _ \ / __ \ / __ \ | |
| |__| | | |__ | | | | | | | | ______`---| |----`| |__| | | |_) | | |__ / ^ \ | .--. || |_) | | | | | | | | | | |
| __ | | __| | | | | | | | | |______| | | | __ | | / | __| / /_\ \ | | | || ___/ | | | | | | | | | |
| | | | | |____ | `----.| `----.| `--' | | | | | | | | |\ \----.| |____ / _____ \ | '--' || | | `--' | | `--' | | `----.
|__| |__| |_______||_______||_______| \______/ |__| |__| |__| | _| `._____||_______/__/ \__\ |_______/ | _| \______/ \______/ |_______|二、Java内存模型
多线程三大特性
1. 原子性
原子性是指在一个操作中就是 CPU 不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。 如果一个操作是原子性的,那么多线程并发的情况下,就不会出现变量被修改的情况。
比如
a = 0;( a 非long和double类型) 这个操作是不可分割的,那么我们说这个操作是原子操作。再比如
a++; 这个操作实际是a = a + 1;是可分割的,所以它不是一个原子操作。
非原子操作都会存在线程安全问题,需要我们使用同步技术( sychronized 等)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。
Java 的 concurrent 包下提供了一些原子类,我们可以通过阅读 API 来了解这些原子类的用法。
比如:AtomicInteger、AtomicLong、AtomicReference等。
(由 Java 内存模型来直接保证的原子性变量操作包括 read、 load、 use、 assign、 store 和 write 六个,大致可以认为基础数据类型的访问和读写是具备原子性的。如果应用场景需要一个更大范围的原子性保证,Java 内存模型还提供了 lock 和 unlock 操作来满足这种需求,尽管虚拟机未把 lock 与 unlock 操作直接开放给用户使用,但是却提供了更高层次的字节码指令 monitorenter 和 monitorexit 来隐匿地使用这两个操作,这两个字节码指令反映到 Java 代码中就是同步关键字 synchronized,因此在 synchronized 块之间的操作也具备原子性。)
1.1 Java 中的原子性
除了
long和double类型的赋值操作。原因:
在 32 位长度操作系统中,
long和double类型的赋值不是原子操作。 因为long和double都是 64 位的,在 32 位系统上,对long和double类型的数据进行读写都要分为两步完成。若同时两个线程同时写一个变量内存,一个写低 8 位,一个写高 8 位,就会导致无效数据出现。解决办法:
long和double类型声明为volatile。Java的内存模型保证声明为volatile的long和double变量的get和set操作是原子的。
所有引用
reference的赋值操作(如AtomicReference)。java.concurrent.Atomic.*包中所有类的一切操作。
1.2 如何保证原子性
- 使用
synchronized关键字定义同步代码块或同步方法来保证原子性。 - 受用
lock加锁来保证原子性。 - 使用
Atomic相关类保证原子性。
1.3 参考链接
2. 可见性
当一个线程修改了共享变量的值,其他线程能够看到修改的值。Java 内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值这种依赖主内存作为传递媒介的方法来实现可见性的。
2.1 如何保证可见性
- 通过
volatile关键字标记变量保证可见性。 - 使用
synchronized关键字定义同步代码块或同步方法来保证可见性。 - 使用
lock加锁来保证可见性。 - 使用
Atomic相关类保证可见性。 - 通过
final关键字来保证可见性。
3. 有序性
即程序执行的顺序按照代码的先后顺序执行。java 存在指令重排,所以存在有序性问题。
3.1 如何保证有序性
- 通过
volatile关键字标记变量保证有序性。 - 使用
synchronized关键字定义同步代码块或同步方法来保证有序性。 - 使用
lock加锁来保证有序性。
参考博客:并发三大特性
happends-before 规则
定理
- 如果操作 A happends-before 操作 B(A hb B),那么 A 操作所产生的所有内存效果(如写入的变量)在操作 B 执行之前,对 B 都是可见的。
- 但是,两个操作之间如果没有 happends-before 关系,JVM 可以对它们进行任意重排序。
Java中的 8 大 happends-before 规则
Java 内存模型(JMM)定义了以下八条天然的 规则,无需任何同步手段就已经存在。
程序次序规则 (Program Order Rule)
- 在一个线程内,按照控制流顺序,书写在前面的操作 happends-before 书写在后面的操作。
管程锁定规则 (Monitor Lock Rule)
- 对一个锁的 unlock 操作 happends-before 后续对同一个锁的 lock 操作。
- 线程 A 释放了锁,线程 B 拿到了这个锁。那么线程 A 在释放锁之前的所有操作结果,对线程 B 拿到锁之后的所有操作都是可见的。这是
synchronized关键字能保证可见性的根本原因。
- 线程 A 释放了锁,线程 B 拿到了这个锁。那么线程 A 在释放锁之前的所有操作结果,对线程 B 拿到锁之后的所有操作都是可见的。这是
- 对一个锁的 unlock 操作 happends-before 后续对同一个锁的 lock 操作。
volatile 变量规则 (Volatile Variable Rule)
- 对一个 volatile 变量的写操作 happends-before 后续对这个变量的读操作。
- 这是
volatile关键字保证可见性的直接体现。线程 A 写了一个 volatile 变量,线程 B 之后去读它,一定能读到最新值,并且能看到线程 A 在写这个 volatile 变量之前的所有操作结果。
- 这是
- 对一个 volatile 变量的写操作 happends-before 后续对这个变量的读操作。
线程启动规则 (Thread Start Rule)
Thread对象的start()方法调用 happends-before 此线程的每一个动作(即run()方法中的操作)。- 主线程在启动子线程(调用
start())之前的所有操作结果,对子线程都是可见的。
- 主线程在启动子线程(调用
线程终止规则 (Thread Termination Rule)
线程中的所有操作都 happends-before 其他线程检测到该线程已经终止。
检测方式:可以通过
Thread.join()方法返回,或者Thread.isAlive()返回false来检测线程是否终止。线程 T1 执行了
T2.join()并成功返回,那么 T2 线程中的所有操作对 T1 都是可见的。
线程中断规则 (Thread Interruption Rule)
- 对线程
interrupt()方法的调用 happends-before 被中断线程检测到中断事件。- 被中断线程可以通过
Thread.interrupted()或isInterrupted()方法检测到中断。
- 被中断线程可以通过
- 对线程
对象终结规则 (Finalizer Rule)
- 一个对象的初始化完成(构造函数执行结束) happends-before 它的
finalize()方法的开始。
- 一个对象的初始化完成(构造函数执行结束) happends-before 它的
传递性 (Transitivity)
- 如果 A happends-before B,且 B happends-before C,那么 A happends-before C。
as-if-serial语义
为了尽可能提高程序的执行效率,编译器和处理器会对指令进行重排序优化,但这种优化必须保证,在单线程环境下,程序的最终执行结果与代码顺序(Serial)执行的结果完全一致。
解决的问题是:在最大化性能的同时,保证单线程程序的正确性。
- as-if-serial 保证:单线程程序不需要担心重排序问题。
- happens-before 保证:正确同步的多线程程序不需要担心重排序和内存可见性问题。
volatile 关键字
volatile变量可保证可见性,但不保证原子性。volatile修饰变量时,会把该线程本地内存中的该变量刷新到主内存中。同时让其它线程本地缓存里面该变量失效,这样就会读取主内存里面的最新数据。
- 立即刷新回主内存+失效处理。
volatile变量会禁止指令重排。保证有序性。
原理-读写屏障
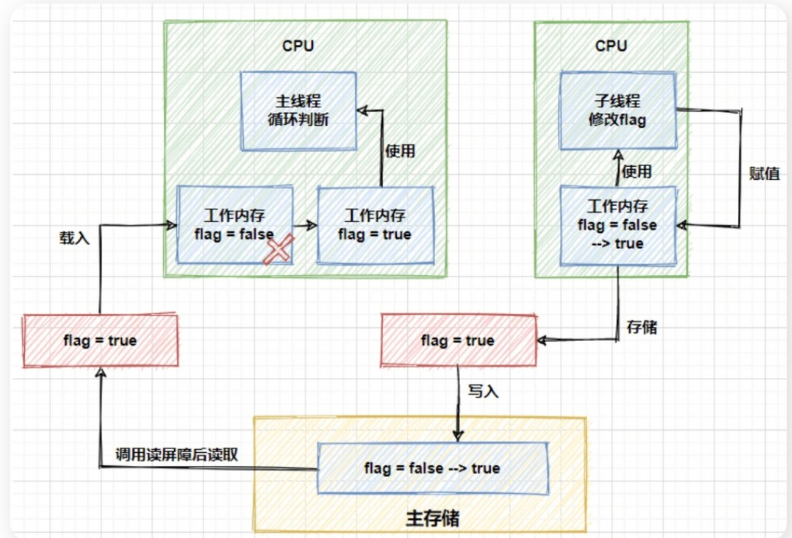
运行中的线程不是直接读取主内存中的变量,而是只能操作自己工作内存的变量。然后同步到主内存,线程之间的工作内存不共享。
- 阻止屏障两边的指令重排序。
- 写数据时加入屏障,强制将线程私有工作内存的数据刷回主物理内存。
- 读数据时加入屏障,线程私有工作内存的数据失效,重新到主物理内存中获取最新数据。
参考链接
synchronized关键字
synchronized 关键字的作用是实现线程之间的同步。是一个互斥锁,保证同时只能有一个线程进入同步块,维持线程间的安全性。
synchronized 特点
- 可重入(主要解决死锁的问题)
- 不可中断
- 非公平
同步代码块
重点是保证多个线程的锁对象是一致的。
- this作为锁对象
//this的锁对象指当前类的实例
synchronized (this) {
i++;
}- 当前类作为锁对象
//使用当前类作为锁对象
synchronized (SynchrodizedCodebolck.class) {
x++;
}- 不变对象作为锁对象
static final Object OBJECT = new Object();
//正确使用对象作为锁
synchronized (OBJECT) {
n++;
}同步方法
synchronized 加在普通方法上或者静态方法上,可实现同步方法。
- 同步普通方法 普通同步方法,锁对象为当前类的实例对象等同于this。
public synchronized void increaseI() {
i++;
}
等价于
public void increase() {
synchronized (this) {
i++;
}
}- 同步静态方法 静态同步方法,锁对象为当前类对象
private synchronized static void increaseM() {
m++;
}
等价于
private static void increase() {
synchronized (NumberOperatingStatic.class) {
m++;
}
}参考链接
synchronized原理
三、并发基础
针对并发重要的 AQS 和 CAS 进行总结,还有 Java 提供的原子类总结。
AQS
CAS
原子类
四、锁
自旋锁
概述
自旋锁是采用让当前线程不停地的在循环体内执行实现的,当循环的条件被其他线程改变时才能进入临界区。使用原子引用变量AtomicReference<V>可实现自旋锁。
代码实现
public class SpinLock {
/**
* 原子引用变量
*/
private static AtomicReference<Thread atomicReference = new AtomicReference<();
public void lock() {
Thread thread = Thread.currentThread();
//当atomicReference为空时,将当前线程赋值给atomicReference(注意:第一个线程进入,while内条件为false,不会进入循环)
while (!atomicReference.compareAndSet(null, thread)) {
}
}
public void unlock() {
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread, null);
}
}实现原理
第一个线程进入之后,请求
lock()方法,可以正常拿到锁资源,不会进入到循环体。首次
atomicReference默认为空,atomicReference.compareAndSet(null, thread)意为若atomicReference为null,则将thread赋值给atomicReference,并返回 true。所以第一个线程不会进入到循环体,并正常执行。在第一个线程持有锁资源时,其他线程进入会不停的在循环体执行。
因为在第一个线程不释放锁的情况下,
atomicReference的值为第一个线程值,atomicReference.compareAndSet(null, thread)判断会返回 false。第一个线程请求
unlock()方法,释放锁资源。atomicReference.compareAndSet(thread,null)意为若atomicReference等于当前线程值,则将atomicReference赋值为 null。当第一个线程请求
unlock()方法之后,atomicReference的值变为 null。其它在循环体的线程,
atomicReference.compareAndSet(null, thread)判断为 true,会跳出循环体,抢占锁资源,多个线程之间会随机抢占。
注意:该例子为不可重入锁,且为非公平锁(多个在循环体里的线程,随机抢占锁,非公平),获得锁的先后顺序,不会按照进入 lock 的先后顺序进行(可重入锁和公平锁的实现见下方章节)。
可重入锁/不可重入锁
可重入锁
当线程获取某个锁后,还可以继续获取它,可以递归调用,而不会发生死锁。基于自旋锁可实现可重入锁。
代码实现
javapublic class ReentrantSpinLock{ private static int count = 0; public static AtomicReference<Thread> atomicReference = new AtomicReference<>(); public void lock() { Thread thread = Thread.currentThread(); //如果引用变量等于当前线程,计数器加1 if (atomicReference.get() == thread) { count++; return; } while (!atomicReference.compareAndSet(null, thread)) { } } public void unlock() { Thread thread = Thread.currentThread(); if(atomicReference.get()==thread){ //如果计数器为0,释放锁资源 if(count==0){ atomicReference.compareAndSet(thread,null); return; } count--; } } }实现原理
- 第一个线程首次获取锁资源时,设置引用变量值为第一个线程值。若第一个线程再次获取相同锁资源,将锁计数器加 1,允许重复获取锁。
- 当线程释放锁时,若锁计数器不为 0,则锁计数器减 1。当锁计数器为 0 时,重置引用变量值为空,释放锁资源。
不可重入锁
与可重入相反,获取锁后不能重复获取,否则会死锁(自己锁自己)。上一章节中实现的自旋锁就是一个不可重入锁。
代码实现
javapublic class NoReentrantSpinLock extends SpinLock { @Override public void lock() { Thread thread = Thread.currentThread(); //当atomicReference为空时,将当前线程赋值给atomicReference(注意:第一个线程进入,while内条件为false,不会进入循环) while (!atomicReference.compareAndSet(null, thread)) { } } @Override public void unlock() { Thread thread = Thread.currentThread(); atomicReference.compareAndSet(thread, null); } }不可重入原因
第一个线程获取锁资源之后,如果同线程再次请求锁资源,会进入到循环里面,同线程不能获取锁资源。
可重入锁和不可重入锁的对比练习
代码参考
javapublic class SpinLockPractice implements Runnable { private static int i = 0; /** * 控制锁对象是否可重入 */ private static SpinLock spinLock = SpinLockFactory.getSpinLock(true); private void methodA() throws InterruptedException { spinLock.lock(); System.out.println("加第一把锁"); //在同一个线程中第二次获取锁对象 methodB(); spinLock.unlock(); } private void methodB() throws InterruptedException { spinLock.lock(); System.out.println("加第二把锁"); for (int j = 0; j < 100000; j++) { i++; } System.out.println("job done"); Thread.sleep(3000); spinLock.unlock(); } @Override public void run() { try { methodA(); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) throws InterruptedException { SpinLockPractice spinLockPractice = new SpinLockPractice(); Thread one = new Thread(spinLockPractice); Thread two = new Thread(spinLockPractice); one.start(); two.start(); one.join(); two.join(); System.out.println(SpinLockPractice.i); } }实现效果
可重入锁
允许同一个线程多次获取同一个锁。能够正常计算,得出结果 200000.
不可重入锁
同一个线程只能获取一次锁对象,同线程第二次获取锁对象时会进入到循环体无限循环,无结果打印。
公平锁和非公平锁
非公平锁:已经获取锁对象的线程有更大概率继续持有相同的锁对象。
- 优点:执行效率高
- 缺点:容易造成饥饿现象。
公平锁:多个线程会按照顺序执行
- 优点:不会造成饥饿现象。
- 缺点:需要维护一个有序队列,实现成本高,性能低下。
注意:synchronized 关键字实现的同步,锁对象是非公平的。
手写实现非公平锁和公平锁
非公平锁。
在上方介绍自旋锁部分,基于原子引用变量
AtomicReference<V>实现的自旋锁是一个非公平锁。当多个线程处于自旋中时,锁资源释放的时候,多个线程之间存在竞争,是无序的。javapublic class NoReentrantSpinLock extends SpinLock { @Override public void lock() { Thread thread = Thread.currentThread(); //当atomicReference为空时,将当前线程赋值给atomicReference(注意:第一个线程进入,while内条件为false,不会进入循环) while (!atomicReference.compareAndSet(null, thread)) { } } @Override public void unlock() { Thread thread = Thread.currentThread(); atomicReference.compareAndSet(thread, null); } }公平锁
以非公平锁的实现为基础进行优化,维护一个有序队列实现公平锁。当引用变量为空的时候,设置应用变量值为队头元素,保证了按照线程入队的顺序获取锁资源。
javapublic class NoReentrantFairSpinLock extends SpinLock { /** * 线程队列 */ private static BlockingQueue<Thread> blockingQueue = new ArrayBlockingQueue<Thread>(10); @SneakyThrows @Override public void lock() { Thread thread = Thread.currentThread(); blockingQueue.add(thread); //自旋 while (true){ //若变量为null,则代表锁未被持有,将队头元素设置未引用变量。 if(atomicReference.compareAndSet(null,blockingQueue.poll())){ //若队列不包含当前线程对象,则说明,当前引用对象为当前线程,跳出自旋,获取锁资源。 if(!blockingQueue.contains(thread)){ break; } } } } @Override public void unlock() { Thread thread = Thread.currentThread(); atomicReference.compareAndSet(thread, null); } }
题目练习
基于上方实现的公平锁,使多个线程根据传入的顺序按序打印结果。
public class FairSpinLockPractice extends Thread {
/**
* 实现公平锁
*/
private static SpinLock lock = SpinLockFactory.getFairSpinLock(true);
/**
* 线程顺序
*/
private int order;
/**
* 线程休眠时间
*/
private long sleepTime;
public FairSpinLockPractice(int order, long sleepTime) {
this.order = order;
this.sleepTime = sleepTime;
}
@SneakyThrows
@Override
public void run() {
lock.lock();
Thread.sleep(sleepTime);
lock.unlock();
System.out.println(order+" end");
}
@SneakyThrows
public static void main(String[] args) {
FairSpinLockPractice test = new FairSpinLockPractice(1, 1000);
test.start();
Thread.sleep(500);
//在第一个线程执行完成之前,按顺序开启多个线程。若为公平锁,则会按照顺序打印结果。
FairSpinLockPractice two = new FairSpinLockPractice(2, 100);
two.start();
FairSpinLockPractice three = new FairSpinLockPractice(3, 200);
three.start();
FairSpinLockPractice four = new FairSpinLockPractice(4, 300);
four.start();
four.join();
}
}
public class SpinLockFactory {
......
/**
* 获取公平锁或不公平锁
* @param fair 是否公平
*/
public static SpinLock getFairSpinLock(boolean fair) {
return fair ? new NoReentrantFairSpinLock() : new NoReentrantSpinLock();
}
}
//output
//1 end
//2 end
//3 end
//4 end公平锁和非公平锁如何选择?
| 特性 | 非公平锁 | 公平锁 |
|---|---|---|
| 核心原则 | 效率优先,允许插队 | 公平优先,先来后到 |
| 吞吐量 | 高(减少线程切换开销) | 相对较低(增加线程切换开销) |
| 线程饥饿 | 可能发生 | 绝不会发生 |
| 顺序性 | 无法保证获取顺序 | 严格保证请求顺序 |
| 实现复杂度 | 简单 | 相对复杂 |
| 默认选择 | 是 (ReentrantLock、synchronized) | 否 |
| 适用场景 | 高并发、短任务、追求极致性能 | 对顺序敏感、长任务、防止饥饿、交易系统 |
重入锁ReentrantLock
可重入、可中断、可实现公平锁、可获取锁状态。
特点
- 可重入
可重入可多次获取锁对象,但是释放锁的次数要和获取锁的次数保持一致。
若获取锁对象比释放的次数多。则当前线程会一直持有锁对象而不释放,其他线程会因为拿不到锁对象而无法进入临界区。
若释放锁的次数比获取锁对象的次数多,则会产生IllegalMonitorStateException异常。
可重入的练习
可中断
提供
lockInterruptibly()方法;在获取锁之后,若有中断发生,会响应中断,停止获取锁对象,并释放已有锁。中断可有效解决线程间的死锁问题,线程限时等待请求锁也可以有效解决死锁问题。
可实现公平锁
java//创建锁对象时,指定为true,即可实现公平锁。 ReentrantLock fairLock = new ReentrantLock(true);
主要方法
lock():获得锁,如果锁已经被占用,则等待。unlock():释放锁。tryLock():尝试获得锁,如果成功返回true,失败返回false。该方法不等待,立即返回。tryLock(long timeout, TimeUnitunit):在指定时间内尝试获得锁,如果成功返回true,失败返回false。(使用此方法申请锁,可有效避免死锁问题)isHeldByCurrentThread():判断当前线程是否持有该锁。
参考练习
synchronized和Lock的区别
| 类别 | synchronized | Lock |
|---|---|---|
| 存在类型 | Java关键字 | 是一个接口 |
| 锁的获取 | 加在方法上,或者同步代码块 | 手动创建 |
| 锁的释放 | 1.获取锁的线程执行完同步代码,释放锁。2.线程执行发生异常,jvm会释放锁。 | 需要手动释放,不然会造成死锁。 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入、不可中断、非公平 | 可重入、可判断、可指定是否公平 |
| 调度 | 使用Object对象本身的wait、notify、notifyAll调度机制 | 使用Condition进行线程之间的调度 |
重入锁的好搭档:Condition
Condition 是和 重入锁ReentrantLock 搭配使用的,类似于 wait() 和 notify() 方法。Object.wait() 和 Object.notify()方法是与 synchronized 搭配使用的,而 Condition 是与 重入锁ReentrantLock 搭配使用的。
通过 lock 接口的 newCondition() 方法即可创建一个与当前锁绑定的 Condition 对象,利用该对象,就可以实现让线程在合适时机等待或得到通知。
主要方法
void await() throws InterruptedException;
void awaitUninterruptibly();
boolean await(long time, TimeUnit unit) throws InterruptedException;
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();await()方法会使当前线程等待,并释放锁。当其他线程使用signal()方法或者signalAll()方法时,线程会被唤醒并开始竞争锁资源。当线程被中断时,也能跳出等待。awaitUninterruptibly()和await()方法基本一致,区别是在等待过程中不会响应中断。signal()用于唤醒一个在等待中的线程,调用该方法的线程必须拥有锁对象,否则会报异常。signalAll()方法会唤醒所有在等待中的线程。
参考练习
源码应用
在阻塞队列 BlockQueue 实现阻塞的 put() 方法和 take() 里,就使用了 Condition,下面以ArrayBlockQueue 源码为例。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** The queued items */
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
//根据传入的长度创建数组
this.items = new Object[capacity];
//在构造方法中初始化锁(可指定公平/非公平)
lock = new ReentrantLock(fair);
//在构造方法中初始化锁的Condition
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
//******************************入队*********************************
public void put(E e) throws InterruptedException {
//判断为空抛出空指针异常
checkNotNull(e);
//获取全局锁
final ReentrantLock lock = this.lock;
//加锁,响应中断
lock.lockInterruptibly();
try {
//当队列数据长度为内部数组的长度的时候,即队列满的情况,进行等待。
while (count == items.length)
//使用Condition的await()方法进行等待,会使当前线程等待,并释放锁。当其他线程使用signal()方法或者signalAll()方法时,线程会被唤醒并开始竞争锁资源。当线程被中断时,也能跳出等待。
notFull.await();
//添加元素
enqueue(e);
} finally {
//释放锁
lock.unlock();
}
}
/**
* Inserts element at current put position, advances, and signals.
* Call only when holding lock.
*/
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
//添加元素
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
//总数+1
count++;
//通知队列为空时候,调用的notEmpty的await()方法。
notEmpty.signal();
}
//******************************出队*********************************
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//当队列长度为0的时候进行等待。
while (count == 0)
//await()方法进行等待,会使当前线程等待,并释放锁。当其他线程使用signal()方法或者signalAll()方法时,线程会被唤醒并开始竞争锁资源。notEmpty对应的signal()方法在enqueue()方法内部。
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
/**
* Extracts element at current take position, advances, and signals.
* Call only when holding lock.
*/
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//获取出队元素
E x = (E) items[takeIndex];
//将出队元素位置置为null
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
//唤醒notFull.await()
notFull.signal();
return x;
}
......
}读写锁ReadWriteLock
锁可分为排他锁和共享锁。
synchronized 和 ReentrantLock都是排他锁,只允许线程独占资源。而在多个线程进行读操作的时候,单个线程占用资源进行读取,其他需要读取的线程会进行等待,而这种等待是不合理的。
读写锁 ReadWriteLock 就是针对读操作和写操作进行的锁优化。
读写锁互斥规则
- 读-读不互斥:并发执行读操作,提高效率。
- 读-写互斥:读会阻塞写,写也会阻塞读。
- 写-写互斥:写线程会独占。
读写锁需要注意:
- 读锁与读锁之间是不互斥的,读锁与写锁之间是互斥的。
- 写锁与其它锁都是互斥的。
- 保证写锁是独占资源的。
- 读线程之间是并发执行的,而写线程执行的时候是独占的。能提高读线程的执行效率。
读写锁的练习和可重入锁的效率对比
与可重入锁比较:
- 可重入锁是互斥的。
- 将读线程和写线程的锁换成可重入锁,之后线程会按照顺序执行,执行效率变慢。
参考练习
锁优化
加锁之后线程之间竞争必然会导致性能下降,针对锁的使用,可以优化提高性能。
减小锁持有时间
如果一个线程持有锁的时间过长,其它线程等待时间就会过长,进而可能造成等待线程增加。所以可以从减少锁持有时间入手,只在必要时进行同步,这样能明显减少线程持有锁的时间,进而提高系统的吞吐量。
减小锁粒度
通过减小锁锁定对象的范围,从而降低锁之间的竞争,进而提高系统的并发能力。
用读写分离锁来替换独占锁
在读多写少的场合使用读写锁可以有效提高系统的并发能力。
锁分离
在 ArrayBlockingQueue 队列源码中 ,take() 和 put() 分别实现了从队列中取得数据和往队列中增加数据,而这两个方法使用的是同一把重入锁来保证线程安全。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
final ReentrantLock lock;
public E take() throws InterruptedException {
//加锁
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
......
}而在 LinkedBlockingQueue 源码中,其实就应用了锁分离的思想。
LinkedBlockingQueue 里面的 take() 和 put() 同样实现了从队列中取得数据和往队列中增加数据。但是由于 LinkedBlockingQueue 是基于链表实现的,两个操作分别作用于队列的头部和尾部。所以,两个操作并不冲突。
如果和 ArrayBlockingQueue 一样使用同一把锁, take() 和 put() 操作就不能实现并发,两个操作之间还是会有竞争,进而影响性能。
而 JDK 实现 LinkedBlockingQueue 时,使用了两把不同的锁分离了 take() 和 put() 操作。
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private final ReentrantLock takeLock = new ReentrantLock();
private final ReentrantLock putLock = new ReentrantLock();
......
}- LinkedBlockingQueue 里面的
take()方法的实现具体如下:
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
//使用takeLock锁
final ReentrantLock takeLock = this.takeLock;
//加锁
takeLock.lockInterruptibly();
try {
//如果队列为空
while (count.get() == 0) {
//等待
notEmpty.await();
}
//获取队列头部数据并从队列删除
x = dequeue();
// 使用原子操作减1 (c是减1之前的值)
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
//通知put操作,队列有空余空间
signalNotFull();
return x;
}- LinkedBlockingQueue 里面的
put()方法的实现具体如下:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
//使用putLock锁
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
//如果当前队列满了
while (count.get() == capacity) {
//等待
notFull.await();
}
//将节点放到队列末尾
enqueue(node);
// 使用原子操作加1 (c是加1之前的值)
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
//通知take操作,队列不为空
signalNotEmpty();
}
private void enqueue(Node<E> node) {
//将node指向尾结点
last = last.next = node;
}通过两把锁,实现了读数据和写数据的分离,实现了真正意义上的并发。
锁粗化
在减少锁持有时间的时候,要求每个线程持有锁的时间尽量短。但是这样可能会造成对同一个锁不断的请求和释放,而重复请求和释放的过程也是一种资源的浪费,不利于性能优化。
而虚拟机在遇到连续的对同一个锁不断请求和释放的操作时,便会把所有的锁操作整合成一次对锁的操作,从而减少对锁请求同步的次数,这个操作叫做锁的粗化。
死锁活锁和饥饿
五、并发工具类
内部存储ThreadLocal
倒计数器CountdownLatch
CountDownLatch 是线程相关的一个倒计数器。位于 java.util.concurrent.CountDownLatch。
- 主要方法
//指定初始值
public CountDownLatch(int count);
//计时器倒数,即计数器减1
public void countDown();
//线程休眠,等到计数器countDownLatch为0时唤醒线程,继续执行
public void await() throws InterruptedException ;在创建的时候,可以为 CountDownLatch 设置初始值 n,线程可进行倒数操作 countDown() 和等待操作 await()。
CountDownLatch 计数器的操作是原子性的,同时只能有一个线程去操作这个计数器,所以同时只能有一个线程能减少这个计数器里面的值。任何线程都可以调用对应的 await() 方法,直到这个计数器的初始值被其他的线程减到 0 为止,调用 await() 方法的线程即可继续执行。
- 参考练习
例1:老板监督工人练习。
有三个工人为老板干活,这个老板会在三个工人全部干完活之后,检查工作。
设计
Worker类为工人。java@Slf4j public class Worker implements Runnable { private CountDownLatch countDownLatch; private String workerName; public Worker(CountDownLatch countDownLatch, String workerName) { this.countDownLatch = countDownLatch; this.workerName = workerName; } @Override public void run() { //开始工作 this.doWorker(); //计时器倒数,即计数器减1 this.countDownLatch.countDown(); } private void doWorker(){ log.info(this.workerName+"工人开始工作"); //当前线程休眠5秒, 即工人工作5秒 try { TimeUnit.SECONDS.sleep(new Random().nextInt(3)); } catch (InterruptedException e) { e.printStackTrace(); } log.info(this.workerName+"工人工作结束!"); } }设计
Boss类为老板。javapublic class Boss implements Runnable{ private CountDownLatch countDownLatch; public Boss(CountDownLatch countDownLatch) { this.countDownLatch = countDownLatch; } @Override public void run() { log.info("老板等待所有工人完成工作,准备视察工作"); try { //线程休眠,等到计数器countDownLatch为0时唤醒线程,继续执行 this.countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } log.info("工人工作都做完了,老板开始视察工作!"); } }在调用时指定计数器个数,
Worker类调用countDown()方法,使计数器减 1。Boss类调用await()方法,使Boss线程休眠,等待计数器减少到 0 时唤醒Boss类。java/** * 测试老板检查工人工作的例子 */ @Test public void testBossWatchWorker() { //创建自定义线程工厂 ThreadFactory myThreadFactory = new ThreadFactoryBuilder().setNameFormat("albert-pool-%d").build(); //使用线程池的构造函数进行创建线程池 ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(3,10, 0L,TimeUnit.MILLISECONDS,new LinkedBlockingDeque<Runnable>(), myThreadFactory,new ThreadPoolExecutor.DiscardPolicy()); //创建一个为3的计时器 CountDownLatch countDownLatch = new CountDownLatch(3); //创建Boss线程对象 Boss boss = new Boss(countDownLatch); //创建3个工人线程对象 Worker workerA = new Worker(countDownLatch, "孙圆圆"); Worker workerB = new Worker(countDownLatch, "艾伯特"); Worker workerC = new Worker(countDownLatch, "杨依惠"); //线程添加到线程池中执行 threadPoolExecutor.execute(workerA); threadPoolExecutor.execute(workerB); threadPoolExecutor.execute(workerC); threadPoolExecutor.execute(boss); try { //线程休眠,休眠结束关闭线程池 TimeUnit.SECONDS.sleep(8); } catch (InterruptedException e) { e.printStackTrace(); } //关闭线程池 threadPoolExecutor.shutdown(); }
例2:使用 CountDownLatch 实现多线程之间按照顺序执行。
进行读写操作,读操作必须在写操作完成之后进行。
设计
Read类为读操作。javapublic class Read implements Runnable{ private CountDownLatch countDownLatch; public Read(CountDownLatch countDownLatch) { this.countDownLatch = countDownLatch; } @SneakyThrows @Override public void run() { log.info("用户准备读取文件"); this.countDownLatch.await(); log.info("用户读取文件成功!"); } }设计
Write类为写操作。javapublic class Write implements Runnable { private final CountDownLatch countDownLatch; public Write(CountDownLatch countDownLatch) { this.countDownLatch = countDownLatch; } @SneakyThrows @Override public void run() { log.info("用户开始写入"); //线程休眠,模拟写操作 TimeUnit.SECONDS.sleep(new Random().nextInt(2)); log.info("用户写入完成"); this.countDownLatch.countDown(); } }测试读写操作,读操作必须在写操作之后。
java@SneakyThrows @Test public void testRead(){ //创建线程池 ExecutorService executorService = Executors.newCachedThreadPool(); //创建计数器 CountDownLatch countDownLatch = new CountDownLatch(1); Write write = new Write(countDownLatch); Read read = new Read(countDownLatch); executorService.execute(write); executorService.execute(read); //休眠5秒 TimeUnit.SECONDS.sleep(new Random().nextInt(5)); //关闭线程池 executorService.shutdown(); }
例3:LeetCode-1114
使三个线程按照顺序调用。
题解
javapublic class PrintFooCountDownLatch { private CountDownLatch secondCountDownLatch = new CountDownLatch(1); private CountDownLatch thirdCountDownLatch = new CountDownLatch(1); public PrintFooCountDownLatch() { } public void one() { log.info("one"); System.out.println("one"); } public void two() { log.info("two"); System.out.println("two"); } public void three() { log.info("three"); System.out.println("three"); } public void first(Runnable printFirst) throws InterruptedException { // printFirst.run() outputs "first". Do not change or remove this line. printFirst.run(); secondCountDownLatch.countDown(); } public void second(Runnable printSecond) throws InterruptedException { secondCountDownLatch.await(); // printSecond.run() outputs "second". Do not change or remove this line. printSecond.run(); thirdCountDownLatch.countDown(); } public void third(Runnable printThird) throws InterruptedException { // printThird.run() outputs "third". Do not change or remove this line. thirdCountDownLatch.await(); printThird.run(); } }
信号量Semaphore
信号量是锁的增强,位于 java.util.concurrent.Semaphore。无论是内部锁 synchronized 和重入锁 ReentrantLock,一次都只是允许一个线程访问一个资源。而信号量可以指定多个线程,同时访问某一个资源。信号量既提供了同步机制,又可以控制同时最大访问的个数。
构造方法
java//指定同时最大访问个数 Semaphore semaphore = new Semaphore(5); //可以指定同时最大访问个数和是否公平 Semaphore semaphore = new Semaphore(5, true);- 公平信号量: 指的是获得锁的顺序与调用
semaphore.acquire()的顺序有关,但不代表百分百获得信号量,仅仅在概率上能得到保证。
- 公平信号量: 指的是获得锁的顺序与调用
常用方法
java//请求获取许可,如果未响应,则线程会等待。直到线程有释放许可或者中断发生。 public void acquire() //和acquire()方法类似,但是不响应中断。 public void acquireUninterruptibly() //尝试获取许可,若成功返回true,获取不成功返回false。不会等待,立即返回。 public Boolean tryAcquire() //尝试在指定时间内获取许可,若成功返回true,获取不成功返回false。超过指定时间则不继续等待,立即返回。 public Boolean tryAcquire(long timeout, TimeUnit unit) //释放一个许可,让其它等待的线程可以访问资源。(可以使信号量的许可总数加1) public void release() //返回信号量当前可用许可个数 public int availablePermits()参考练习
例 1:停车场问题。
停车场只有10个车位,现在有30辆车去停车。当车位满时出来一辆车才能有一辆车进入停车。
例 2:使用信号量
Semaphore实现多线程按照顺序执行。产品、开发、测试同时来上班,产品给需求之后,开发才可以开始开发,开发完成之后,测试才可以开始测试。按照产品->开发->测试的顺序执行。
LeetCode题目
javapublic class PrintFooSemaphore { private Semaphore one = new Semaphore(0); private Semaphore two = new Semaphore(0); public PrintFooSemaphore() { } public void one() { log.info("one"); System.out.println("one"); } public void two() { log.info("two"); System.out.println("two"); } public void three() { log.info("three"); System.out.println("three"); } public void first(Runnable printFirst) throws InterruptedException { // printFirst.run() outputs "first". Do not change or remove this line. printFirst.run(); one.release(); } public void second(Runnable printSecond) throws InterruptedException { one.acquire(); // printSecond.run() outputs "second". Do not change or remove this line. printSecond.run(); two.release(); one.release(); } public void third(Runnable printThird) throws InterruptedException { // printThird.run() outputs "third". Do not change or remove this line. two.acquire(); printThird.run(); two.release(); }
循环栅栏 CyclicBarrier
CyclicBarrier 是一种多线程并发控制工具,可循环利用,作用是让所有线程都等待完成后才会进行下一步行动。
构造方法
javapublic CyclicBarrier(int parties) public CyclicBarrier(int parties, Runnable barrierAction)第一个构造方法可指定参与线程的个数。
第二种构造方法可以指定当
CyclicBarrier完成一次计数之后,需要执行的任务。
重要方法
java//到达栅栏,等待 public int await() throws InterruptedException, BrokenBarrierException //设置等待的超时事件 public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutExceptionawait()方法,表示线程已经到达栅栏,准备执行。等到约定的线程数都到达之后,即计数完成,开始往下执行。 若有指定需要在计数完成后指定的任务,则先执行指定的任务。
参考练习
CyclicBarrier 和 CountDownLatch 的区别
CountDownLatch是一次性的,而CyclicBarrier是可循环利用的。CountDownLatch参与线程的职责是不一样的,await()是在等待倒计时结束,countDown()是进行一次倒计时。CyclicBarrier参与的线程的职责都是在等待计数结束。
LockSupport阻塞工具
LockSupport 是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置让线程阻塞。不需要获取任何锁,也不会抛出中断异常。
常用方法
阻塞方法
park():直接阻塞parkNaors():限时阻塞LockSupport.park()方法可实现限时等待,还能支持中断响应,但是并不会抛出InterruptedException异常,它只会默默返回。
取消阻塞
unpark():取消线程阻塞状态
总结
与
Thread.suspend()方法相比,推荐使用该方法进行线程阻塞。因为Thread.suspend()阻塞当前线程时,可能会产生死锁。而
LockSupport内部使用的是类似信号量的机制,每个线程都有一个许可,若许可可用,则park()方法会立即返回消费该许可,将许可变为不可用,对应线程会阻塞。而unpark()方法会使一个许可变为可用,所以即使先调用unpark()方法,park()方法也会顺利执行并结束,而不会造成死锁。参考练习
源码中的应用
FutureTask的get()方法FutureTask的get()方法在获取结果时,若结果未完成计算,就会阻塞等待,实现阻塞使用的就是LockSupport。javapublic class FutureTask<V> implements RunnableFuture<V> { //构造方法Callable public FutureTask(Callable<V> callable) { if (callable == null) throw new NullPointerException(); this.callable = callable; this.state = NEW; // ensure visibility of callable } //构造方法Runnable public FutureTask(Runnable runnable, V result) { this.callable = Executors.callable(runnable, result); this.state = NEW; // ensure visibility of callable } //get()方法阻塞 public V get() throws InterruptedException, ExecutionException { int s = state; if (s <= COMPLETING) //阻塞等待 s = awaitDone(false, 0L); return report(s); } //阻塞的方法 private int awaitDone(boolean timed, long nanos) throws InterruptedException { final long deadline = timed ? System.nanoTime() + nanos : 0L; WaitNode q = null; boolean queued = false; //自旋 for (;;) { if (Thread.interrupted()) { removeWaiter(q); throw new InterruptedException(); } int s = state; if (s > COMPLETING) { if (q != null) q.thread = null; return s; } else if (s == COMPLETING) // cannot time out yet //让出线程资源 Thread.yield(); else if (q == null) q = new WaitNode(); else if (!queued) //CAS queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q); else if (timed) { nanos = deadline - System.nanoTime(); if (nanos <= 0L) { removeWaiter(q); return state; } //阻塞工具LockSupport,实现限时阻塞 LockSupport.parkNanos(this, nanos); } else //直接阻塞 LockSupport.park(this); } } }
ReadLimiter限流
ReadLimiter 是 Guava 提供的一中限流工具,限流算法有两种:漏桶算法和令牌桶算法。ReadLimiter 使用的是令牌桶算法。
限流算法
漏桶算法
利用一个缓冲区,当有请求进入系统时,都先在缓存区保存,然后以固定速度流出缓冲区进行处理。
令牌桶算法
令牌桶算法是一种反向的漏桶算法,在令牌桶算法中,桶中存放的不是请求,而是令牌。处理程序只有在拿到令牌之后,才会对请求进行处理。如果没有令牌,那么处理程序要不等待令牌,要不丢弃请求。为了限流,该算法在每个单位会生成一定量的令牌存入桶中。通常桶的容量是有限的,为了限制流速,该算法在每个单位时间产生一定量的令牌存入桶中,但是令牌总数不会超过桶的容量。比如,若要求程序一秒处理一个请求,那么令牌桶一秒会生成一个令牌。
参考练习
六、线程池
为了避免系统频繁的创建和销毁线程,可以让创建出来的线程进行复用,需要对线程进行管理。
使用线程池的目的:
- 降低资源消耗:通过重用已经创建的线程来降低线程创建和销毁的消耗
- 提高响应速度:任务到达时不需要等待线程创建就可以立即执行
- 提高线程的可管理性:线程池可以统一管理、分配、调优和监控
线程池的状态
线程池总共有 5 种状态。
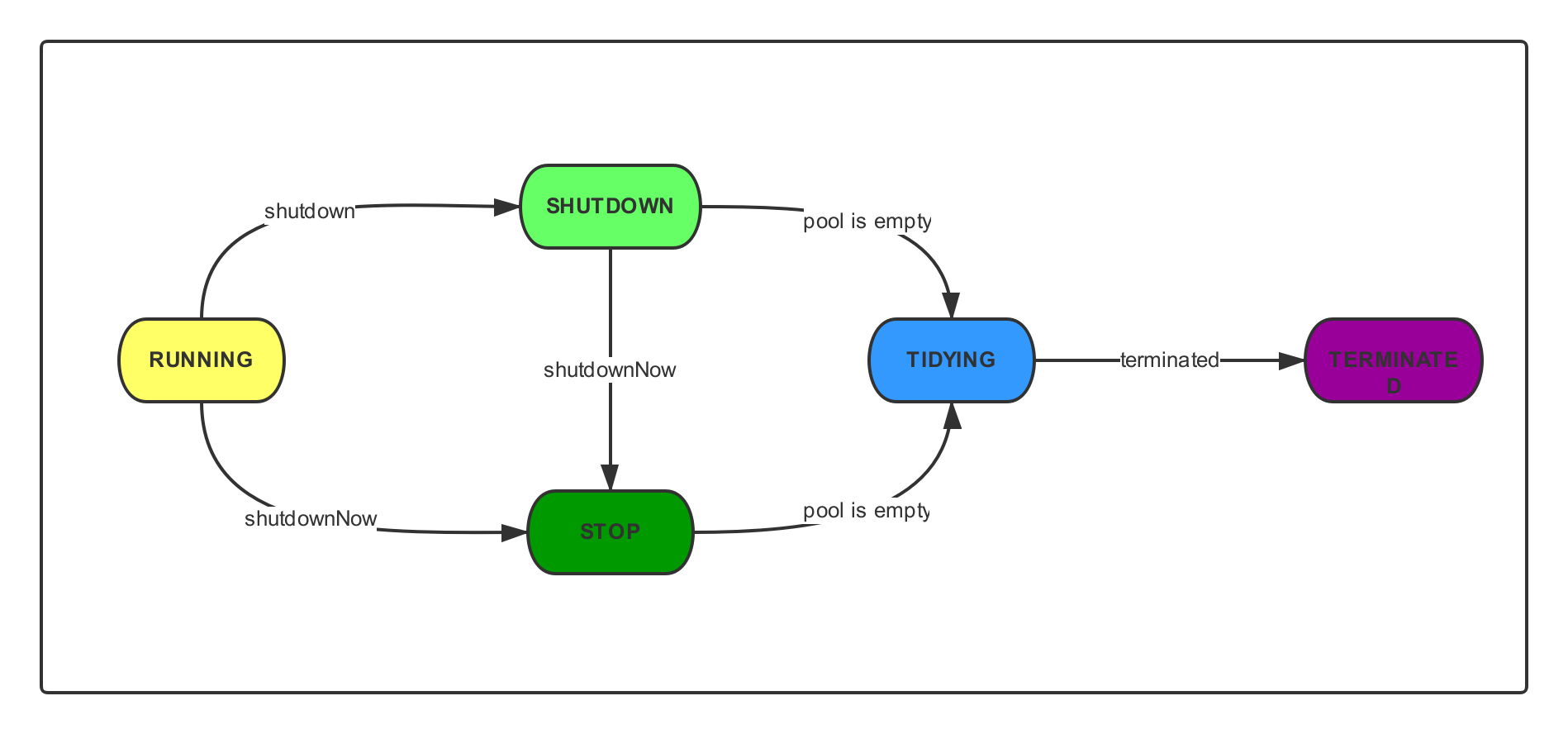
RUNNING
线程池创建之后的初始状态,该状态下可正常执行任务。
SHUTDOWN
该状态下线程池不再接受新任务,但是会等待任务队列中的任务执行结束。
STOP
该状态下线程池不再接受新任务,也不会处理任务队列中的任务,并会将所有存货的线程中断。
TIDYING
该状态下所有任务都以终止,并将执行
terminated的钩子方法。TERMINATED
执行完
terminated的钩子方法之后。
源码中的体现
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;线程池的7个参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
......
}对应各个参数的含义:
1.corePoolSize
核心线程数。即使在空闲时也要保留在线程池中的线程数,除非设置了 allowCoreThreadTimeOut 。
2.maximumPoolSize
最大线程数。当线程数大于核心线程数时,一个任务被提交到线程池后,首先会缓存到工作队列中,如果工作队列满了,则会在线程池中创建一个新线程,而线程数量会有一个最大数量的限制,即为 maximumPoolSize 。
3.keepAliveTime
线程空闲时间。一个线程处于空闲,并且线程数量大于核心线程数,那么该线程会在指定时间后被回收,指定时间由 keepAliveTime 指定。
4.TimeUnit
线程空闲时间单位。
5.workQueue
存放线程任务类的任务队列。当线程池没有空闲线程时,在执行任务之前将任务保存在队列中,该队列仅保存由 execute 方法提交的任务。
6.ThreadFactory
线程工厂,可设置线程为守护线程,自定义线程名称等。
*7.RejectedExecutionHandler
任务拒绝策略。当任务队列里的任务长度达到最大,线程池中的线程数量达到最大,就会执行任务拒绝策略。
线程池中的任务队列
1. ArrayBlockingQueue (有界队列)
是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出 原则对元素进行排序。
2. LinkedBlockingQueue (无界队列)
一个基于链表结构的阻塞队列,此队列按 FIFO (先进先出) 排序元素,吞吐量通常要高于 ArrayBlockingQueue 。静态工厂方法 Executors.newFixedThreadPool() 使用了这个队列。
3.SynchronousQueue(同步队列)
一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQueue ,静态工厂方法 Executors.newCachedThreadPool 使用了这个队列。
4.DelayQueue(延迟队列)
一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。
5.PriorityBlockingQueue(优先级队列)
一个具有优先级的无限阻塞队列。
线程池的四种拒绝策略
直接抛出异常 - AbortPolicy
默认的任务拒绝策略,对于新增任务,拒绝处理,直接抛出 RejectedExecutionException 异常。
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
//直接抛出异常
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}调用当前线程 - CallerRunsPolicy
调用自己的线程来执行任务,不创建新的线程,而是用自己当前线程进行执行,会降低对于新任务的提交速度,影响整体性能。如果程序能够容许延时,并且不能丢弃每一个任务,即可采取这个策略。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//调用自己的线程执行
r.run();
}
}
}不作处理 - DiscardPolicy
不做任何处理,直接丢掉该任务.
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}删除队列任务 - DiscardOldestPolicy
删除任务队列中最早的任务,将新增任务添加到任务队列中。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//删除线程池的任务队列的第一个元素
e.getQueue().poll();
e.execute(r);
}
}
}线程池的执行流程
线程池的关闭
JDK提供的线程池
Java 从 JDK1.5 开始提供了线程池的四种类型:分别为CachedThreadPool、FixedThreadPool、ScheduledThreadPool、SingleThreadExecutor; 从 JDK1.8 开始提供了WorkStealingPool。这 5 种线程池都位于Executors线程池工厂中。ThreadPoolExecutor表示一个线程池,里面包含了创建线程池的实现。
注意:由于 Executors 线程池工厂创建出的线程存在一定弊端(具体见各个线程池的分析),推荐使用手动创建的方式来创建线程池。(出自阿里规约)
缓存型线程池 - CachedThreadPool
可灵活创建线程,如果线程池长度超过任务长度,可灵活回收线程。
//源码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}创建原理
- 指定核心线程数为 0,即线程池最小的线程数为 0;
- 指定线程池最大允许存在的线程数为
Integer.MAX_VALUE; - 指定空闲线程的销毁时间是
60s; - 指定任务队列为同步队列
SynchronousQueue只能包含一个任务的队列; - 线程工厂可使用默认的或自定义的线程工程;
- 任务拒绝策略使用默认的
ThreadPoolExecutor.AbortPolicy(对于新增任务,拒绝处理,直接抛出RejectedExecutionException异常)。
缓存型线程池使用
任务队列只允许存放一个任务,线程池中若有任务进来,则立刻新建线程去执行任务。若有大量任务同时进来,则在线程池中新建对应的线程,若线程空闲 60s,则会自动回收。
CachedThreadPool()的好处:由于CachedThreadPool()线程池允许线程数量很大,并且会自动回收,非常适合执行数量很大的短期任务。CachedThreadPool()的弊端:允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM(内存溢出)。(出自阿里规约)
定长型线程池 - FixedThreadPool
固定线程池的线程数量,控制线程数,多余的任务在任务队列中等待。
//源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}创建原理
- 指定核心线程数和最大线程数都为
n,即线程池一直保持拥有着n个线程; - 指定空闲线程的销毁时间是 0;
- 指定任务队列为无界队列
LinkedBlockingQueue,队列长度为Integer.MAX_VALUE的队列; - 线程工厂可使用默认的或自定义的线程工程;
- 任务拒绝策略使用默认的
ThreadPoolExecutor.AbortPolicy对于新增任务,拒绝处理,直接抛出RejectedExecutionException异常。
定长型线程池使用
线程池从初始化开始便恒定拥有 n 个线程,不存在线程个数的增减,任务队列允许放接近无穷的任务,即线程池没有线程可以处理新任务时,会将新任务加入任务队列中,该线程池任务的拒绝策略不会执行,因为任务队列被允许一直放入任务。
FixedThreadPool()线程池的好处:由于FixedThreadPool()线程池线程数量恒定,非常适合执行时间长且任务量固定的任务。FixedThreadPool()线程池的弊端:允许的任务队列长度为Integer.MAX_VALUE,可能会堆积大量的任务请求,从而导致OOM(内存溢出)。(出自阿里规约)
单线程线程 - SingleThreadExecutor
线程池只有一个线程,若因为任务失败而终止当前线程,则新的线程会替代它继续执行后续任务。
//源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}创建原理
- 指定核心线程数和最大线程数都为
1,即线程池一直保持拥有着1个线程; - 指定空闲线程的销毁时间是 0;
- 指定任务队列为队列长度为
Integer.MAX_VALUE的队列; - 线程工厂可使用默认的或自定义的线程工程;
- 任务拒绝策略使用默认的
ThreadPoolExecutor.AbortPolicy对于新增任务,拒绝处理,直接抛出RejectedExecutionException异常。
单线程线程池的使用
线程池只初始化并维护一个线程,并设置 LinkedBlockingQueue 为任务队列。
SingleThreadExecutor()线程池的好处:使用SingleThreadExecutor来自动维护一个单线程。SingleThreadExecutor()线程池的弊端:允许的任务队列长度为Integer.MAX_VALUE,可能会堆积大量的任务请求,从而导致OOM(内存溢出)。(出自阿里规约)
定时线程池 - ScheduledThreadPool
可以定时执行任务。
//源码
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}创建原理
- 可指定核心线程数。
- 最大线程数为
Integer.MAX_VALUE。 - 指定空闲线程的销毁时间是 0;
- 指定任务队列为专门延时队列
DelayedWorkQueue,来实现定时任务的执行。 - 线程工厂可使用默认的或自定义的线程工程。
- 任务拒绝策略使用默认的
ThreadPoolExecutor.AbortPolicy对于新增任务,拒绝处理,直接抛出RejectedExecutionException异常。
定时线程池的使用
可实现定时执行任务,或延时执行任务。
ScheduledThreadPool()线程池的好处:可以定时周期的执行任务。ScheduledThreadPool()线程池的弊端:允许的线程最大长度为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM(内存溢出)。(出自阿里规约)
抢占式线程池 - WorkStealingPool
抢占式的线程池,能合理的使用 CPU 进行任务处理,适合很耗时的任务。
//源码
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}创建原理
- 实际上是创建了一个
ForkJoinPool()对象。 - 传入参数则使用传入的线程数量,若不传入,则默认使用当前计算机可用的 CPU 数量。
Fork/Join(分而治之)线程池框架
Fork/Join 线程池框架包含 ForkJoinPool 线程池。
ForkJoinTask任务类。作用是为了实现将大型复杂任务进行递归的分解,直到任务足够小才直接执行,从而递归的返回各个足够小的任务结果汇总成一个大任务的结果,以此类推得到最初提交的那个大型复杂任务的结果。
ForkJoinTask有两个子类:
RecursiveTask是有返回值的。RecursiveAction是没有返回值的。
如何设计核心线程数
CPU 密集型任务(N+1)
这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务(2N)
这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
程序出Bug了?
∩∩
(´・ω・)
_| ⊃/(___
/ └-(___/
 ̄ ̄ ̄ ̄ ̄ ̄ ̄
算了反正不是我写的
⊂⌒/ヽ-、_
/⊂_/____ /
 ̄ ̄ ̄ ̄ ̄ ̄ ̄
万一是我写的呢
∩∩
(´・ω・)
_| ⊃/(___
/ └-(___/
 ̄ ̄ ̄ ̄ ̄ ̄ ̄
算了反正改了一个又出三个
⊂⌒/ヽ-、_
/⊂_/____ /
 ̄ ̄ ̄ ̄ ̄ ̄ ̄七、并发容器
线程安全的HashMap
HashTable
采用synchronized在方法级别加锁,效率低。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}Collections包装HashMap
Collections类维护了一个SynchronizedMap类,该类把有关Map的所有操作都被加上了锁,在执行任何方法之前都要获取锁对象mutex,实现了线程安全。
Map<String, String> oldMap = Maps.newHashMap();
//使用Collections对map进行线程同步封装
Map<String,String> safeMap = Collections.synchronizedMap(oldMap);虽然这个包装的Map实现了线程安全,但是在多线程的环境并不算太好。无论是读取还是写入操作,都需要先获取锁对象,这样会导致其它操作进入等待状态,效率较低。若并发量不高,可以使用,在并发量高的时候,性能不太好,不推荐使用。
//------------源码
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
//------------Collects内部的SynchronizedMap类
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
//锁对象mutex
final Object mutex; // Object on which to synchronize
......
public int size() {
//在执行任何方法之前,都要获取mutex锁对象
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
......
}ConcurrentHashMap
ConcurrentHashMap 位于 java.util.concurrent 包内,专门对并发进行了优化,更适合多线程的场合。
//线程安全的Map
ConcurrentMap<Object, Object> map = Maps.newConcurrentMap();要特别注意,ConcurrentHashMap 中的 key 或者 value 为 null 时会直接抛出空指针异常,在源码中有所体现。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
......
}
......
}这里记录一下 JDK1.8 之后 ConcurrentHashMap 新增的一些方法。JDK 1.8 之后新增了一些支持 lambda表达式的方法。
foreach()java@Test public void testForeach() { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); for (int i = 0; i < 5; i++) { concurrentHashMap.put(Integer.toString(i), i); } concurrentHashMap.forEach((k, v) -> { System.out.println("K:" + k + ";V:" + v); }); }reducereduce()方法可以对ConcurrentHashMap内部元素进行计算。- parallelismThreshold:并行数
- transformer:该函数是计算元素(K,V)的结果。
- reducer:该函数是各个元素计算结果之间的元素规则(加减乘除)。
javapublic <U> U reduce(long parallelismThreshold, BiFunction<? super K, ? super V, ? extends U> transformer, BiFunction<? super U, ? super U, ? extends U> reducer) { if (transformer == null || reducer == null) throw new NullPointerException(); return new MapReduceMappingsTask<K,V,U> (null, batchFor(parallelismThreshold), 0, 0, table, null, transformer, reducer).invoke(); }练习代码:
java@Test public void testReduce() { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); for (int i = 1; i <= 5; i++) { concurrentHashMap.put(Integer.toString(i), i); } //并行计算map的总和 //这里的2是并行数量 // transformer函数是计算元素结果(K,V),reducer是元素之间的运算规则 Integer count = concurrentHashMap.reduce(2, (k, v) -> Integer.valueOf(k) + v - 1, (value1, value2) -> value1 * value2); System.out.println(count); }reduceValues只对元素的 value 进行计算。
java@Test public void testReduceValues() { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); for (int i = 0; i < 5; i++) { concurrentHashMap.put(Integer.toString(i), i); } //并行计算map的总和 //这里的2是并行数量 //reduceValues只对value进行运算 Integer count = concurrentHashMap.reduceValues(2, Integer::sum); System.out.println(count); }search集合的搜索方法
java/** * 测试search方法 */ @Test public void testSearch() { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); for (int i = 0; i < 5; i++) { concurrentHashMap.put(Integer.toString(i), i); } //这里的2是并行数 String value = concurrentHashMap.search(2, (k, v) -> { //搜索逻辑 if (v % 4 == 0) { return k + "---"; } return null; }); System.out.println(value); }computeIfAbsent- 若map存在指定key,直接返回结果。
- 若map中不存在指定key,则先插入后返回结果。
java/** * 测试map的computeIfAbsent方法 * 1.若map存在指定key,直接返回; * 2.若map中不存在指定key,则先插入后返回; */ @Test public void testComputeIfAbsent() { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); for (int i = 0; i < 5; i++) { concurrentHashMap.put(Integer.toString(i), i); } Integer value = 100; //map中若存在该key,直接返回数据。若不存在该key,先put再返回。 Integer count = concurrentHashMap.computeIfAbsent("100", v -> value); System.out.println(count); }
线程安全的list
Vector
采用synchronized在方法级别加锁,效率低。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}Collections包装List
Collections类维护了一个synchronizedList类,该类把有关list的所有操作都被加上了锁,在执行任何方法之前都要获取锁对象mutex,实现了线程安全。
ArrayList<Object> oldList = Lists.newArrayList();
//使用Collections对list进行线程同步封装
List<Object> safeList = Collections.synchronizedList(oldList);虽然这个包装的list实现了线程安全,但是在多线程的环境并不算太好。无论是读取还是写入操作,都需要先获取锁对象,这样会导致其它操作进入等待状态,效率较低。若并发量不高,可以使用,在并发量高的时候,性能不太好,不推荐使用。
//------------源码
public static <T> List<T> synchronizedList(List<T> list) {
//判断是否随机访问,区分list的类型
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
//------------Collects内部的SynchronizedList类
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -7754090372962971524L;
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
//执行方法之前都要先获取到锁对象mutex
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
......
}CopyOnWriteArrayList
由于排它锁在一定读写分离特别是读操作特别多的情况下影响效率,所以在读操作多的时候不推荐使用排它锁。
CopyOnWriteArrayList位于Java.util.concurrent包内,专门对并发进行了优化,实现了读写分离,而且写操作不会阻塞读操作,只有在写-写操作时才会阻塞。根据名字可以看到,CopyOnWrite大概意思就是在写操作的时候会进行自我复制,将原来的数据复制一份当作副本,然后将要写入的内容写入副本中,最后将副本替换原来的数据,即完成了写操作,同时不会影响读操作。
//线程安全的list
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList<Integer> newList = new CopyOnWriteArrayList<Integer>(oldList);实现原理
- 创建过程
不传参数。
初始化一个长度为
0的空数组,并赋值给内部数组array。传入Collection。
按照传入集合的元素顺序迭代,复制到新数组中,并把新数组赋值给内部数组
array。
private transient volatile Object[] array;
final void setArray(Object[] a) {
array = a;
}
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}读方法
首先
array是存放原本数据的数组,其由volatile关键字修饰,代表若其它线程修改了array里的值,会被动态发现。根据源码可以看到在读操作的时候是没有实现线程同步的,也不会被写操作阻塞,原因就是array数组具有可见性。java/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; /** * Gets the array. Non-private so as to also be accessible * from CopyOnWriteArraySet class. */ final Object[] getArray() { return array; } private E get(Object[] a, int index) { return (E) a[index]; } public E get(int index) { return get(getArray(), index); }写方法
在进行写操作的时候,首先会加一把重入锁,但是由于这把锁在写操作内部,所以仅限于
写-写操作时会阻塞。根据源码可以看出,在写操作之前,会完成一次原数据的复制,并新建副本,指定长度
+1,然后将要添加的元素放在副本的最后一个元素,最后将副本赋值给原数据array,即完成了写操作。由于array本身是由volatile修饰的,具有可见性,所以写入数据会立即被其它线程发现,读操作就不会受到影响,也完成了读-写不互斥。java/** The array, accessed only via getArray/setArray. */ private transient volatile Object[] array; /** * Gets the array. Non-private so as to also be accessible * from CopyOnWriteArraySet class. */ final Object[] getArray() { return array; } public boolean add(E e) { final ReentrantLock lock = this.lock; //加锁 lock.lock(); try { //获取原数据 Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { //释放锁 lock.unlock(); } }
BlockQueue阻塞队列
八、并发设计模式
单例模式
单例模式和并发并没有太大关系,但是线程安全的单例模式在并发情况下应用很广泛。可以使用推荐的单例模式实现方式,来实现并发情况下的共享对象。
不变模式
不变模式的核心就是:一个对象创建后,内部状态将永远不会发生改变。这样即使在多线程情况下,每个线程获取到的对象都是一致的,所以针对不变模式的对象,不需要考虑线程安全问题。
使用场景
- 对象创建后,对象内部状态和数据都不会再改变。
- 对象需要共享,支持并发访问。
实现方式
- 对象去除 setter 方法。
- 不提供修改自身属性的方法。
- 将所有属性设置为 private,并添加 final 关键字,确保属性不会被修改。
- 提供一个可以创建完整对象的构造函数。
- 确保不存在子类可以重载修改它的行为(最好不存在子类)。
//final修饰的类不能被继承
public final class Product {
//属性私有且final修饰
private final String no;
private final String name;
private final double price;
//创建完整对象的构造方法
public Product(String no, String name, double price){
super();
this.no=no;
this.name=name;
this.price=price;
}
public String getNo() {
return no;
}
public String getName() {
return name;
}
public double getPrice() {
return price;
}
}生产者-消费者模式
生产者-消费者模式通过对生产者线程和消费者线程进行解耦合,通过共享缓冲区进行通信,满足并发情况下的访问问题。
共享缓冲区的主要功能就是实现多线程情况下的数据共享,还可以缓解生产者和消费者之间的性能差距。
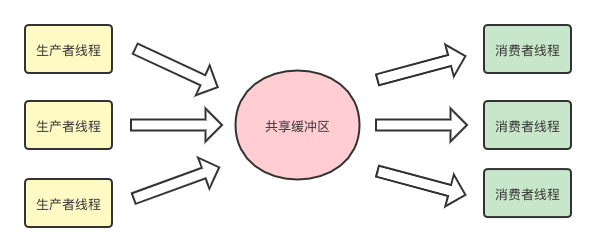
Java 中能充当内存缓冲区的数据结构有很多,支持并发的容器,比如 BlockingQueue就可以作为共享缓冲区来使用。
本地存储模式-ThreadLocal
在并发情况下,对象的共享问题可以通过本地存储模式解决,即每个线程都有一个属于线程本身的对象副本。而 Java 提供了对应的类 - ThreadLocal。
Future模式
在多线程中,当线程 A 需要线程 B 的计算结果时,假设计算耗时较长,线程 A 往往需要等待。若线程 A 不希望等待线程 B ,则可以先拿到一个线程 B 的 Future,等 B 计算完成之后从 Future 中即可获取到计算结果。
Future 的核心思想是 异步调用。
JDK中的Future模式
JDK 中提供了 Future 模式,与线程创建类 Callable 搭配使用。
Callable 接口只有一个方法 call() ,它能够返回结果,并且开启一个线程。
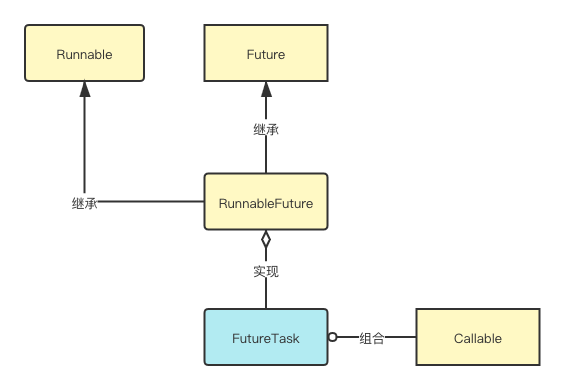
FutureJDK 中的 Future 接口提供了一些方法,其中
get()方法就是获取异步计算的结果方法,若不指定超时时间,则存在阻塞的问题。javapublic interface Future<V> { //取消任务 boolean cancel(boolean mayInterruptIfRunning); //是否已经取消 boolean isCancelled(); //是否已经完成 boolean isDone(); //获取数据,会阻塞 V get() throws InterruptedException, ExecutionException; //获取数据,指定超时时间 V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }RunnableFutureRunnableFuture继承了Runnable和Future, 但是它还是个接口。它提供了两个功能,一是可以被当作线程执行,二是可以作为 Future 获取 Callable 的返回值。javapublic interface RunnableFuture<V> extends Runnable, Future<V> { void run(); }FutureTaskFutureTask实现了RunnableFuture,这也意味着FutureTask才是真正用来使用的对象。FutureTask具备了RunnableFuture的功能,即可以当作线程执行,也可以作为 Future 获取 Callable 的返回值,同时 FutureTask 还实现了 Future 接口的方法。FutureTask 的 get() 方法是获取计算结果,若结果未完成计算,就会发生阻塞(通过阻塞工具 LockSupport 实现)。
javapublic class FutureTask<V> implements RunnableFuture<V> { //构造方法Callable public FutureTask(Callable<V> callable) { if (callable == null) throw new NullPointerException(); this.callable = callable; this.state = NEW; // ensure visibility of callable } //构造方法Runnable public FutureTask(Runnable runnable, V result) { this.callable = Executors.callable(runnable, result); this.state = NEW; // ensure visibility of callable } //get()方法阻塞 public V get() throws InterruptedException, ExecutionException { int s = state; if (s <= COMPLETING) //阻塞等待 s = awaitDone(false, 0L); return report(s); } //阻塞的方法 private int awaitDone(boolean timed, long nanos) throws InterruptedException { final long deadline = timed ? System.nanoTime() + nanos : 0L; WaitNode q = null; boolean queued = false; //自旋 for (;;) { if (Thread.interrupted()) { removeWaiter(q); throw new InterruptedException(); } int s = state; if (s > COMPLETING) { if (q != null) q.thread = null; return s; } else if (s == COMPLETING) // cannot time out yet //让出线程资源 Thread.yield(); else if (q == null) q = new WaitNode(); else if (!queued) //CAS queued = UNSAFE.compareAndSwapObject(this, waitersOffset, q.next = waiters, q); else if (timed) { nanos = deadline - System.nanoTime(); if (nanos <= 0L) { removeWaiter(q); return state; } //阻塞工具LockSupport,实现限时阻塞 LockSupport.parkNanos(this, nanos); } else //直接阻塞 LockSupport.park(this); } } }
代码练习
@SneakyThrows
public static void main(String[] args) {
RealData realData = new RealData("hello");
FutureTask<String> futureTask = new FutureTask<>(realData);
//搭配线程池
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.submit(futureTask);
System.out.println("提交任务结束");
try {
System.out.println("异步开始进行");
Thread.sleep(5000);
System.out.println("异步结束进行");
} catch (InterruptedException e) {
e.printStackTrace();
}
//get()方法是阻塞的,在这里阻塞相当于还是同步
String content= futureTask.get();
System.out.println("异步获取计算结果:"+content);
executorService.shutdown();
}Future模式的不足
Future 模式本质上是异步调用,但是获取计算结果的线程和任务执行不是同一个线程,计算结果需要通过 get() 方法获取。若在结果未计算完成时调用 get() 方法,则会发生阻塞,又变为了同步状态。所以 Future 模式在效率上的提高是有限的。
除了直接阻塞还可以通过轮询的方式来判断数据是否计算完成,同样存在效率问题。
CompletableFuture
Future 在获取结果的时候只能采用轮询或者阻塞等待的方式,不是真正意义上的异步,而 JDK1.8 更新的 CompletableFuture 可以实现真正意义上的异步。
完成通知 -
complete在计算完成之后可以进行主动通知。
javapublic class AskThread implements Runnable { private CompletableFuture<Integer> completableFuture = null; public AskThread(CompletableFuture<Integer> completableFuture) { this.completableFuture = completableFuture; } @Override public void run() { try { int content = completableFuture.get() * completableFuture.get(); System.out.println(content); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } } @SneakyThrows public static void main(String[] args) { CompletableFuture<Integer> future = new CompletableFuture<>(); new Thread(new AskThread(future)){}.start(); //模拟结果的计算过程 Thread.sleep(3000); //完成之后进行通知 future.complete(50); } }异步调用 -
supplyAsync使用该方法能够实现异步调用,该方法内部封装了线程池,类似 Future 的异步调用。
java@SneakyThrows public static Integer calc(int num) { Thread.sleep(3000); return num * num; // return num / 0; } @SneakyThrows public static void main(String[] args) { //supplyAsync 异步计算 CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(() -> calc(100)); //get()方法会阻塞 System.out.println(completableFuture.get()); }注意:
get()方法同样会阻塞。流式调用返回结果 -
thenAcceptCompletableFuture增加了流式调用的功能,thenAccept传入的函数式接口式Function<T, R>,有返回值。在异步方法调用完成后按照顺序调用该方法。java@SneakyThrows @Test public void testThenApply() { //流式调用 CompletableFuture<String> voidCompletableFuture = CompletableFuture.supplyAsync(() -> calc(100)) //任务完成后的回调方法 .thenApply((value) -> { System.out.println("异步任务计算完成!!!"); return String.valueOf(value + 1); }); //阻塞等待 System.out.println("阻塞主线程:"+voidCompletableFuture.get()); } //output 异步任务计算完成!!! 阻塞主线程:10001不返回结果 -
thenAcceptthenAccept传入的函数式接口式Consumer<T>,无返回值。在异步方法调用完成后按照顺序调用该方法。java@SneakyThrows @Test public void testThenAccept() { //流式调用 CompletableFuture<Void> voidCompletableFuture = CompletableFuture.supplyAsync(() -> calc(100)) //任务完成后的回调方法 .thenApply((value) -> { System.out.println("异步任务计算完成!!!"); return String.valueOf(value + 1); }).thenAccept(System.out::println); //阻塞等待 System.out.println("阻塞主线程:"+voidCompletableFuture.get()); }异常处理 -
exceptionally可以通过该方法增加流式处理过程中的异常处理。
java@Test public void testExce() throws InterruptedException { //流式调用增加异常处理 CompletableFuture.supplyAsync(() -> calc(30)) .exceptionally(ex -> { System.out.println(ex.getMessage()); return 0; }).thenAccept(System.out::println); Thread.sleep(5000); }
Guava提供的Future
Guava 对 Future 进行了增强,增加了通知回调的功能,实现了异步的效果。
@SneakyThrows
@Test
public void guavaFuture() {
//1.使用Guava的增强线程池
ListeningExecutorService listeningExecutorService =
MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
RealData task = new RealData("hello");
//2.提交任务
ListenableFuture<String> future = listeningExecutorService.submit(task);
//3.为异步任务增加监听,任务完成自动调用回调方法
future.addListener(() -> {
try {
//回调方法逻辑
System.out.println("异步任务执行结束");
String content = future.get();
System.out.println("调用回调方法结果为:" + content);
//关闭线程池
listeningExecutorService.shutdown();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}, listeningExecutorService);
//非阻塞进行其他任务
Thread.sleep(20000);
System.out.println("进行其他业务处理");
}还可以为 Future 增加成功和异常时的回调方法。
/**
* 增加对异常的处理
*/
@SneakyThrows
@Test
public void guavaFutureErr() {
//使用Guava的增强线程池
ListeningExecutorService listeningExecutorService =
MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
RealData task = new RealData("hello");
//提交任务
ListenableFuture<String> future = listeningExecutorService.submit(task);
//增加任务的监听,同时增加成功和失败时的回调方法
Futures.addCallback(future, new FutureCallback<String>() {
@Override
public void onSuccess(@Nullable String s) {
try {
System.out.println("异步任务执行结束");
String content = future.get();
System.out.println("调用回调方法结果为:" + content);
//关闭线程池
listeningExecutorService.shutdown();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
@Override
public void onFailure(Throwable throwable) {
System.out.println("回调失败!!!!!!");
}
});
//非阻塞进行其他任务
Thread.sleep(5000);
System.out.println("进行其他业务处理");
}九、JDK新特性
虚拟线程
十、参考书籍
,--"""",--.__,---[],-------._
," __,' \ \--""""""==;-
," _,-" "/---.___ \ ___\ ,-'',"
/,-' / ;. ,.--'-.__\ _,-"" ,| `,' /
/``""""-._/,-|:\ []\,' ```-/:;-. `. /
` ;::: || /:,; `-.\
=.,'__,---||-.____',.=
=(:\_ ||__ ):)=
,"::::`----||::`--':::"._
,':::::::::::||::::::::::::'.
.__ ;:::.-.:::::__||___:::::.-.:::\ __,
"""-;:::( O )::::>_|| _<::::( O )::::-"""
=======;:::::`-`:::::::||':::::::`-`:::::\=======
,--"";:::_____________||______________::::""----. , ,
; ::`._( | ||| | )_,'::::\_,,,,,,,,,,____/,'_,
,; :::`--._|____[]|_____|_.-'::::::::::::::::::::::::);_
;/ / :::::::::,||,:::::::::::::::::::::::::::::::::::/
/; ``''''----------/,'/,__,,,,,____:::::::::::::::::::::,"
;/ :);/|_;| ,--.. . ```-.:::::::::::::_,"
/; :::):__,'//""\\. ,--.. \:::,:::::_,"
;/ :::::/ . . . . . . //""\\. \::":__,"
;/ :::::::,' . . . . . . . . . . .:`::\
'; :::::::__,'. ,--.. . .,--. . . . . .:`::`
'; __,..--'''-. . //""\\. .//""\\ . ,--.. :`:::`
; / \\ .//""\\ . . . . . . . . . //""\\. :`::`
; / . . . . . . . . . . . . . . . . .:`::`
; ( . . . . . . . . . . . . . . . ;:::`
,: ;, . . . . . . . . . . . . . ;':::`
,: ;, . . . . . . . . . . . . .;`:::
,: ;, . . . . . . . . . . . . ;`::;`
,: ; . . . . . . . . . . . . ;':::;`
: ; . . . . . . . . . . . ,':::;
: '. . . . . . . . .. . . .,':::;`
: `. . . . . . . . . . . . ;::::;`
'. `-. . . . . . . . . . . ,-'::::;
`:_ ``--..___________..--'':::::;'`
`._::,.:,.:,:_ctr_:,:,.::,.:_;'`
________________`"\/"\/\/'""""`\/"\/""\/"___________