
ConcurrentHashMap - 1.7
一、类简介
ConcurrentHashMap 是一个线程安全的 HashMap,在 JDK 1.7 HashMap的基础上实现了 分段锁 来保证线程安全。在 HashMap 的基础上,默认分为 16 个段,每个段都拥有独立的锁,来保证各个段的线程安全。
扩展 - 线程安全的 HashMap
Unsafe方法总结
二、主要参数
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
//默认初始化容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//默认并发级别
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//Segment最小容量
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
static final int RETRIES_BEFORE_LOCK = 2;
final int segmentMask;
final int segmentShift;
//ConcurrentHashMap底层数组
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values;1. Segment 是什么?
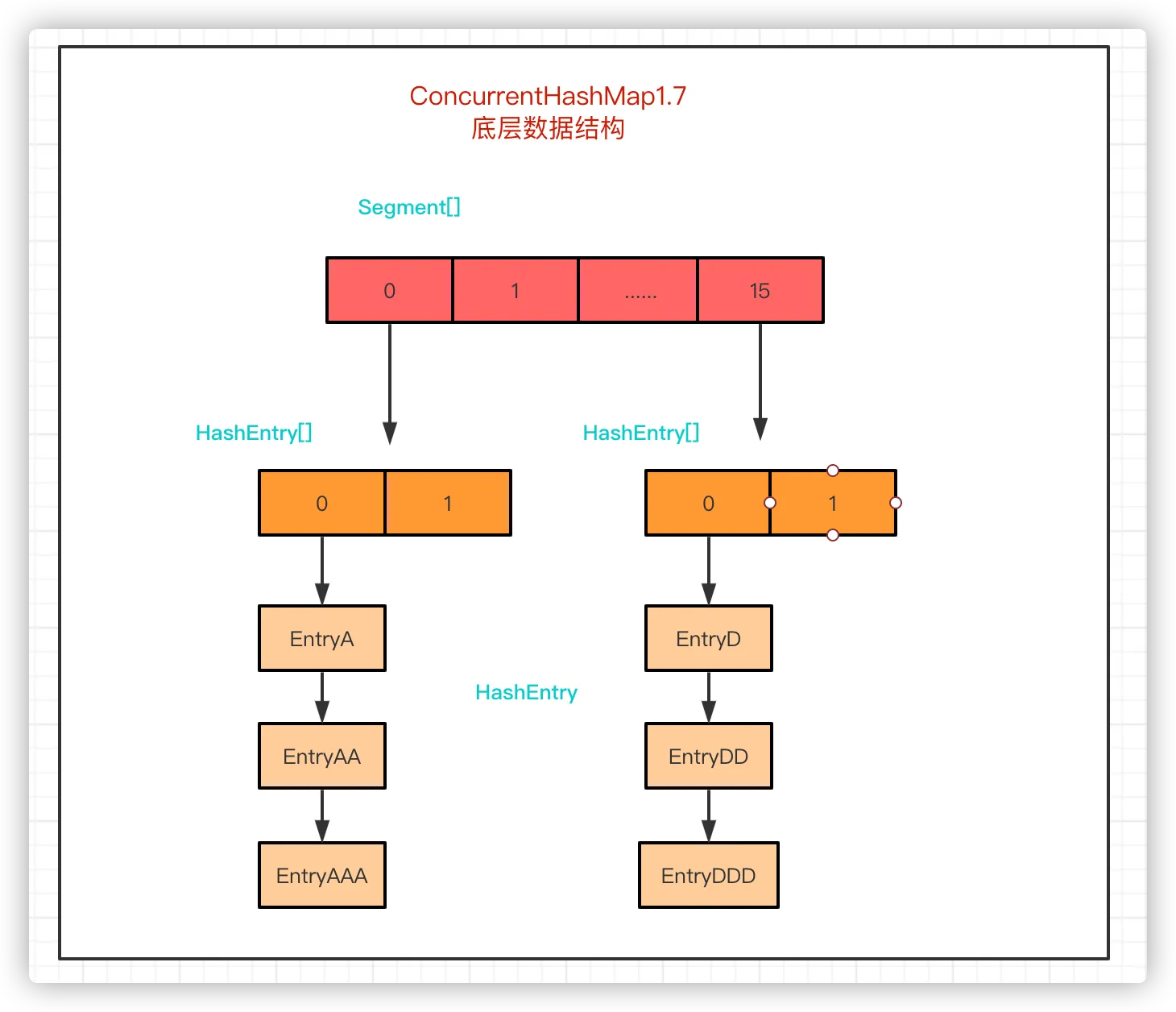
Segment 是 ConcurretnHashMap的一个内部类,继承于 ReentrantLock,可实现同步操作保证线程安全。作为 ConcurrentHashMap 的底层数组结构,各个 Segment 之间的锁互不影响,称这种锁机制为分段锁。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//真正存放数据的数组
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
......
}2. HashEntry 是什么?
HashEntry 是 ConcurrentHashMap 中实际存放数据的对象。其实体类于 HashMap 中的 Entry 实体类一样,是一个链表结构。不同的是 ConcurrentHashMap 的 value 和 next 字段都增加了 volatile 字段来保证字段的可见性,防止多线程情况出现并发问题。
static final class HashEntry<K,V> {
//hash值
final int hash;
//key值
final K key;
volatile V value;
//下一节点
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
final void setNext(HashEntry<K,V> n) {
//原子操作
UNSAFE.putOrderedObject(this, nextOffset, n);
}
static final sun.misc.Unsafe UNSAFE;
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}3. concurrencyLevel 是什么?
意为并发级别。实际作用是用来限制底层数组 Segment[] 的大小,来保证 ConcurrentHashMap 同时支持的并发数。
在构造方法中,存在一个局部变量 ssize,初始化 segments 时传入的容量为 ssize。
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
而 ssize 的结果为第一个大于等于 concurrencyLevel 的2次方幂值。
//循环结束,得到 ssize 的结果为第一个大于等于concurrencyLevel的2次方幂值
while (ssize < concurrencyLevel) {
++sshift;
//向左移一位,增大两倍
ssize <<= 1;
}三、构造方法
ConcurrentHashMap 默认底层数组是长度为 16 的 Segment[],每个 Segment 对象包含了默认长度为 2 的 HashEntry[],HashEntry 是实际保存数据的对象,所以 ConcurrentHashMap 默认初始可保存元素长度为32个,而不是 16个。
默认构造方法
/**
* The default initial capacity for this table,
* used when not otherwise specified in a constructor.
*/
//默认长度
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The default load factor for this table, used when not
* otherwise specified in a constructor.
*/
//默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The default concurrency level for this table, used when not
* otherwise specified in a constructor.
*/
//默认并发级别
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
public ConcurrentHashMap() {
//传入默认参数值,调用有参构造
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}有参构造 - 主要构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
//Segment[]长度。
int ssize = 1;
//找到第一个大于等于 concurrencyLevel 的 2次幂(Segment[]长度)
while (ssize < concurrencyLevel) {
++sshift;
//向左移一位,增大两倍
ssize <<= 1;
}
//segmentShift和segmentMask用来计算segment的下标位置
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//初始容量 / Segment[]长度 = 每个Segment的容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
//Segment最小容量为2
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//控制Segment容量大小为2次幂
while (cap < c)
cap <<= 1;
// create segments and segments[0]
//初始化一个Segment模版
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//根据Segment[]容量初始化
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//使用UNSAFE类,根据模版初始化Segment[]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}扩展问题
底层数组 segments 长度必须是2次方幂值的原因?
创建时指定长度为 ssize。
因为在 put 方法时,计算索引的下标时需要用到与运算。
javapublic V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); //基于key,计算hash值 int hash = hash(key); //因为一个键要计算两个数组的索引,为了避免冲突,这里取高位计算Segment[]的索引 int j = (hash >>> segmentShift) & segmentMask; //判断该索引位的Segment对象是否创建,没有就创建 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); //调用Segmetn的put方法实现元素添加 return s.put(key, hash, value, false); }在构造方法中,指定了 segmentShift 和 segmentMask 的值。
java...... int sshift = 0; //Segment[]长度。 int ssize = 1; //找到第一个大于等于 concurrencyLevel 的 2次幂(Segment[]长度) while (ssize < concurrencyLevel) { ++sshift; //向左移一位,增大两倍 ssize <<= 1; } //segmentShift和segmentMask用来计算segment的下标位置 this.segmentShift = 32 - sshift; this.segmentMask = ssize - 1; ......计算索引元素的公式 :
index = (hash >>> segmentShift) & segmentMask)等价于index = hash(key) & (ssize- 1)。由于是与运算,所以需要保证 ssize 的值为 2次方幂值(参考 JDK1.7HashMap)。
segment 的 HashEntry 数组的最小长度是 2?
因为 ConcurrentHashMap 的扩容是更新单个 Segment。而不是整个数组。这就要求 Segment 长度是 2次方幂值,而 2 是最小的 2 次方幂值。由于 ConcurrentHashMap 默认拥有 16 个段,所以单个段发生扩容的几率较低,若 segment 过大,资源浪费较大。
四、存储元素的原理
采用 数组 + 链表 的形式存储。
结合 1.7 的 HashMap 来看,ConcurrentHashMap 的底层数据结构是 Segment[],而每一个 Segment 包含了一个 HashEntry[],而 HashEntry[] 里的每个 HashEntry 才是存储数据的位置。
通过特定 Hash 算法计算 Key 的 Hash 值。
根据 Key 的 Hash 值和 Segment[] 长度 - 1 的与运算结果,得到新增元素对应的 Segment。
调用对应 Segment 的 put 方法。
根据 Key 的 Hash 值和 HashEntry[] 长度 - 1 的与运算结果,得到新增元素对应的 HashEntry。
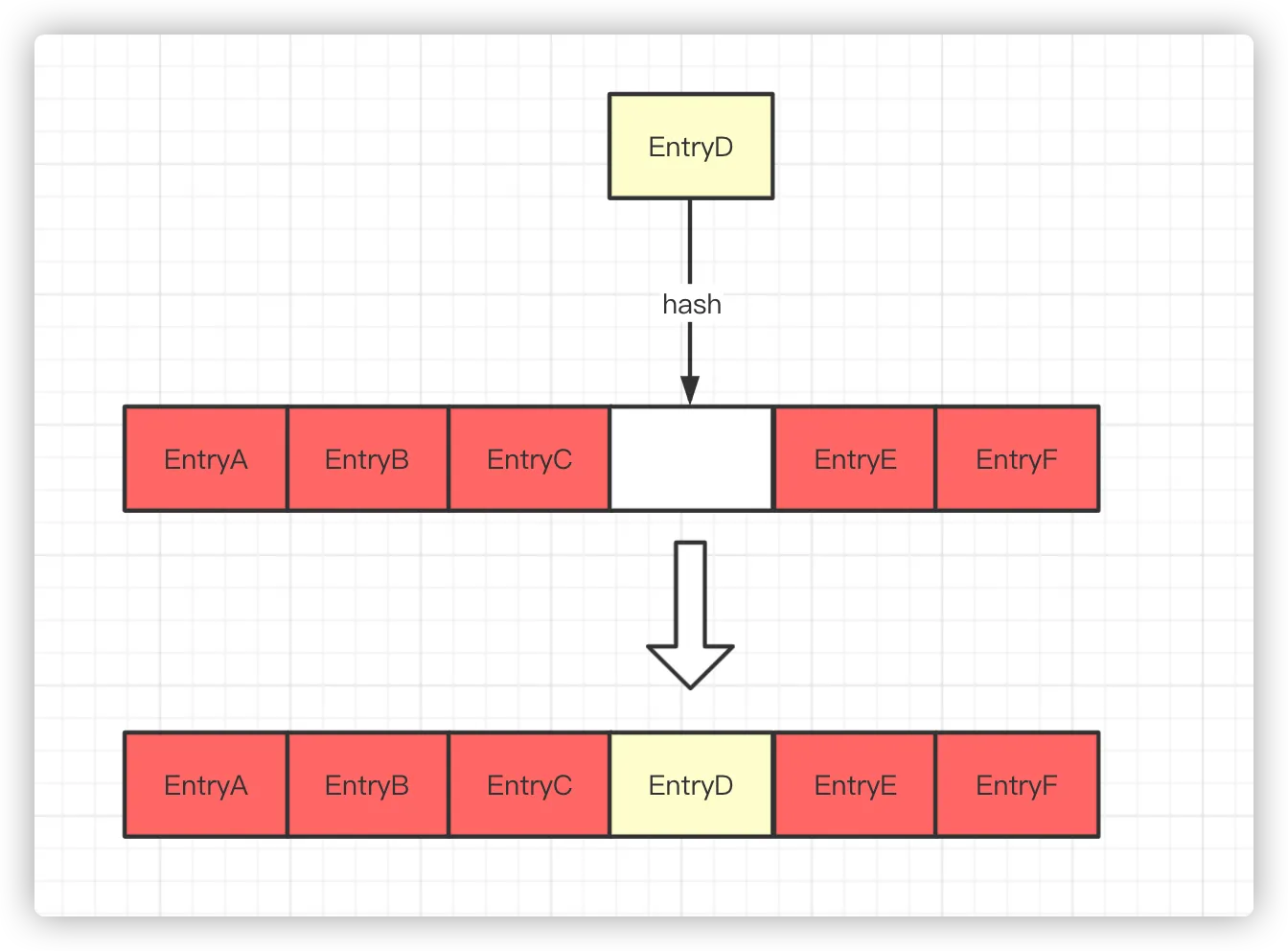
若数组对应的 index 位置为 NULL,将 Entry 存放到数组的 index 位置上。
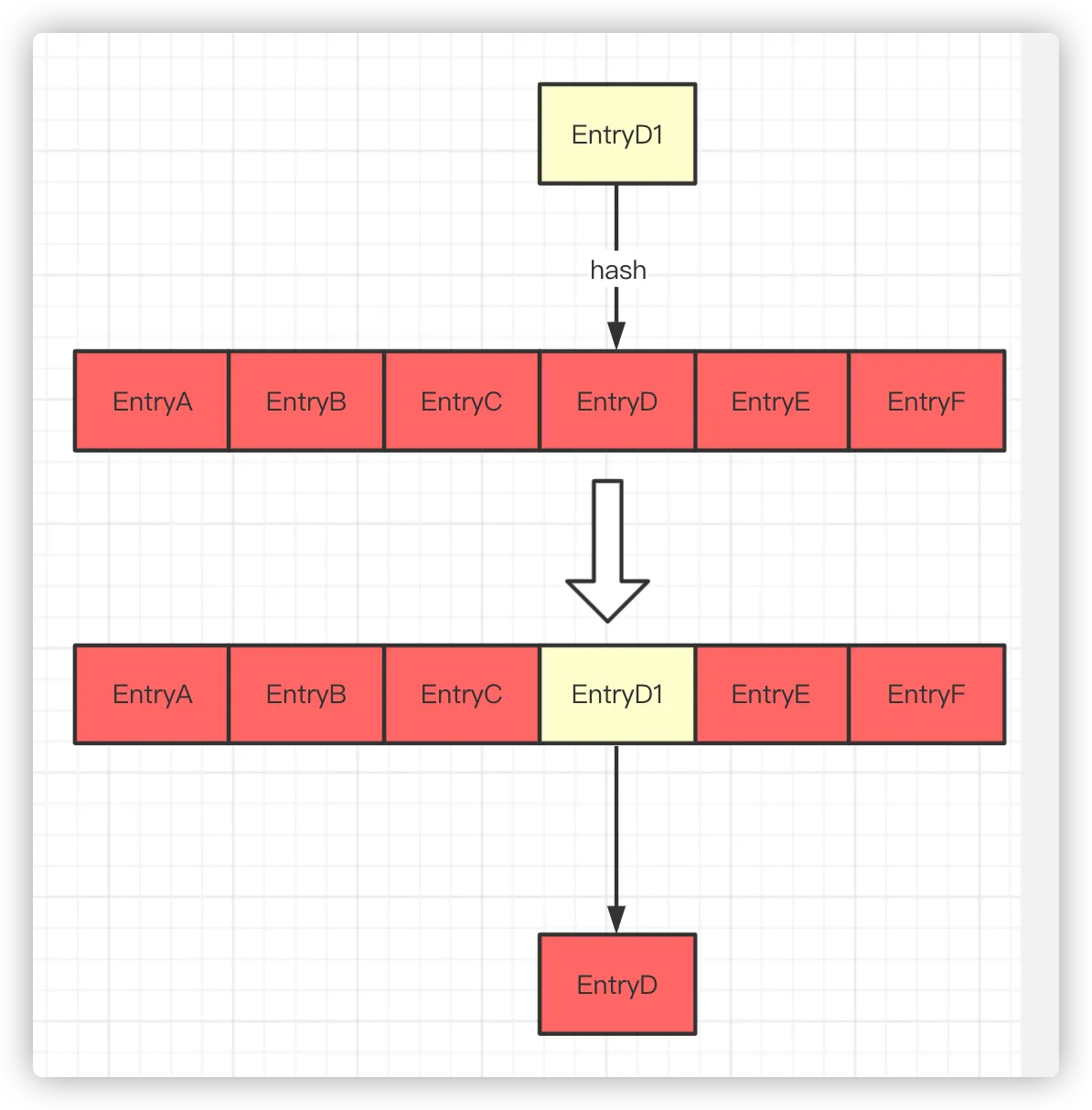
若数组对应的 index 位置不为 NULL,即发生了索引冲突,此时采用链表的方式来保存元素,新增的元素会保存在链表的头部,并存放到数组对应的 index 位置上(头插法)。
五、底层扩容原理
Segment的个数初始化之后不能改变。
所以扩容是更新每个Segment对应的数组,而不是直接更新整个数组。
这样能提高扩容的并发度。
六、常见问题
1. 怎么实现的线程安全?
- 通过锁分段技术保证并发环境下的写操作;
- 通过 HashEntry的不变性、Volatile变量的内存可见性和加锁重读机制保证高效、安全的读操作;
- 通过不加锁和加锁两种方案控制跨段操作的的安全性。