
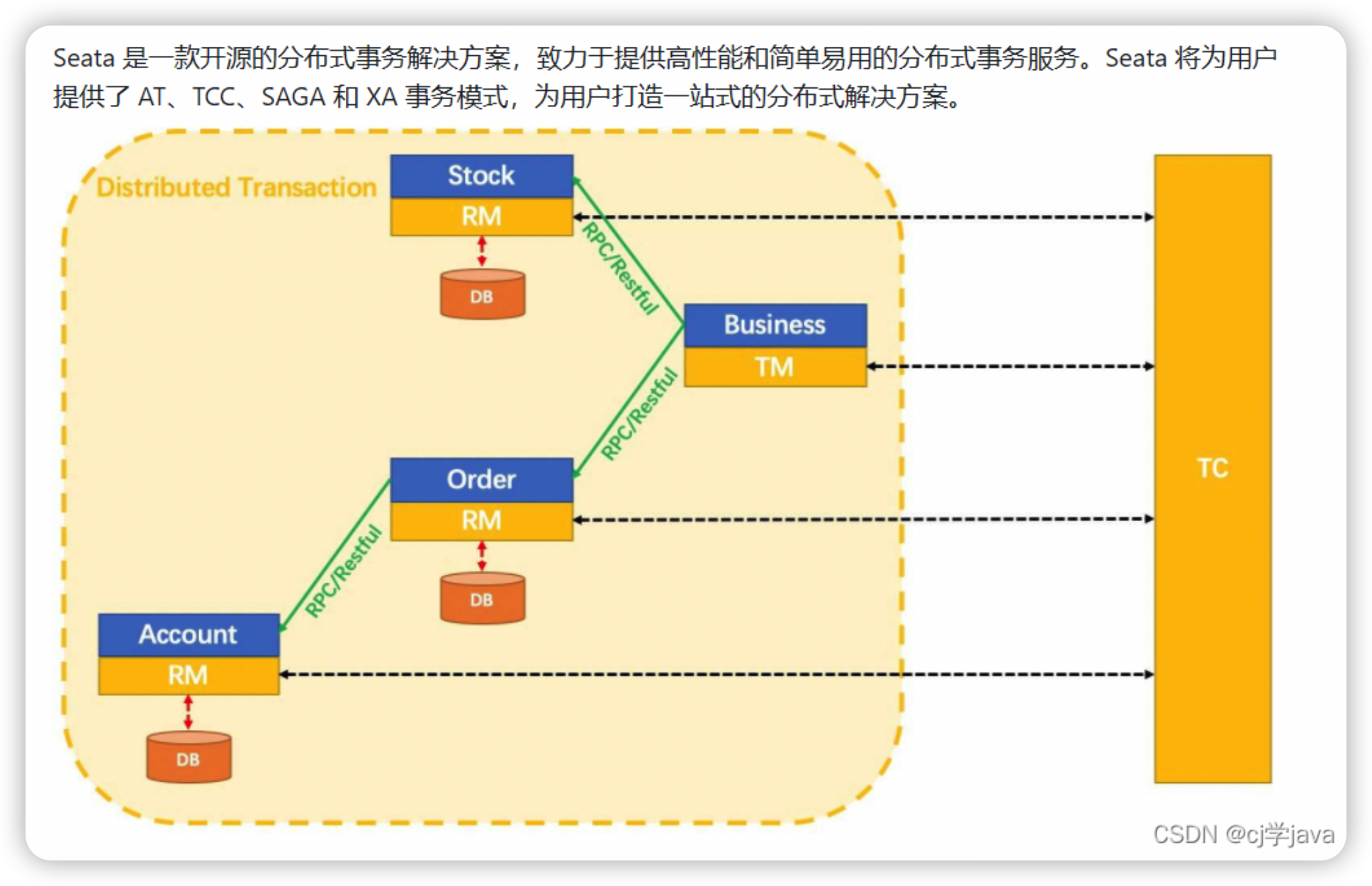
Seata分布式事务
在分布式情况下,一次业务请求需要调用多个系统操作多个数据源时,针对多个数据源操作会产生分布式事务问题。每个系统能够保证各自数据源的一致性问题,但是全部系统数据的一致性问题没法保证。
官网地址
https://seata.io/zh-cn/docs/user/quickstart.html
下载地址
https://seata.io/zh-cn/blog/download.html
基础概念
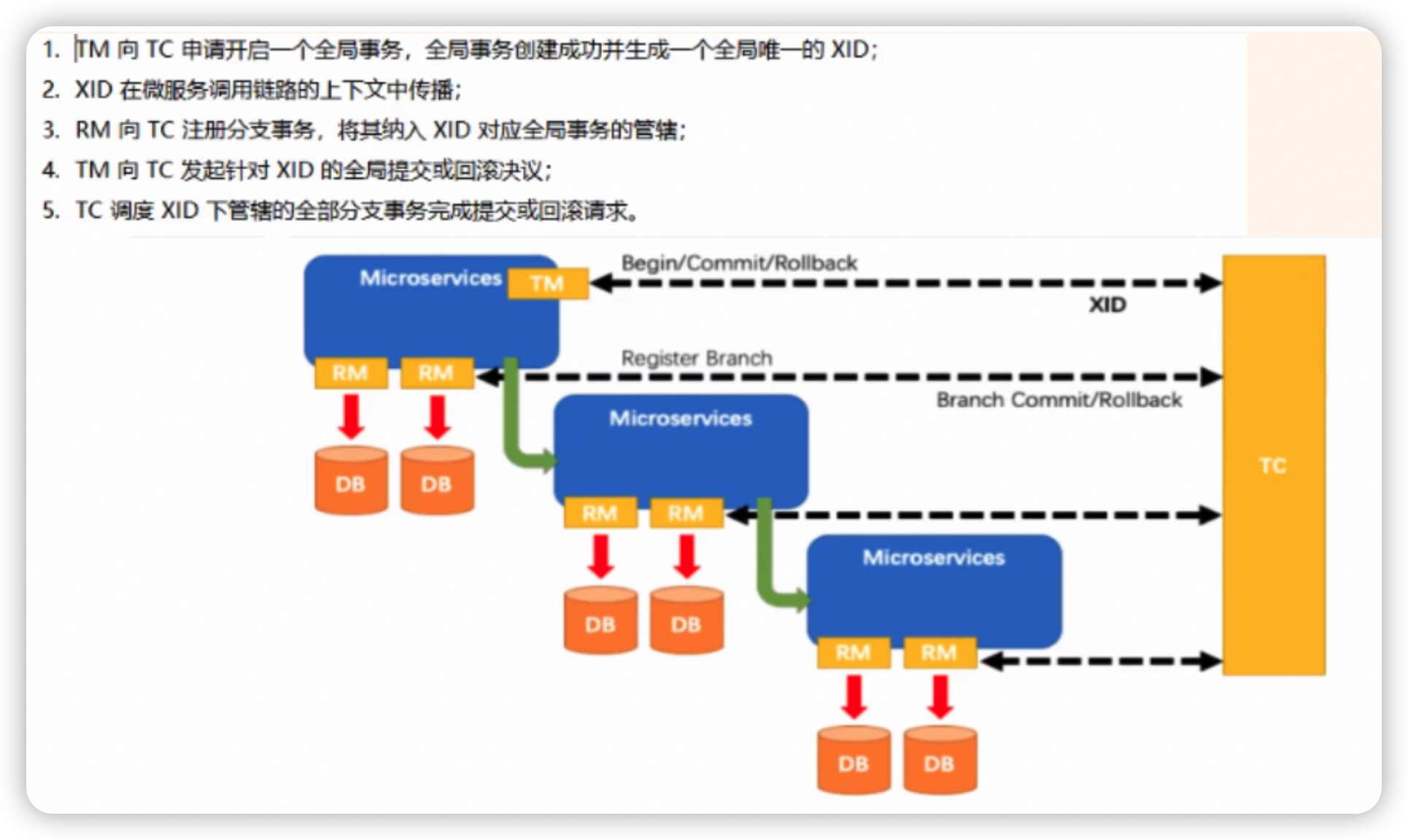
事务ID + 三组件
事务ID
- Transaction ID(XID)
三组件
TC-事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
为单独部署的服务端。
TM-事务管理器
定义全局事务的范围,开启全局事务,提交或回滚全局事务。
嵌入到应用中的 Clinet 客户端。在代码中加注解的地方对应的就是事务管理器 TM。
RM
对应的资源管理器,管理分支事务处理的资源。与 TC 交谈以注册分支事务和报告分支事务的状态,驱动分支事务的提交或者回滚。
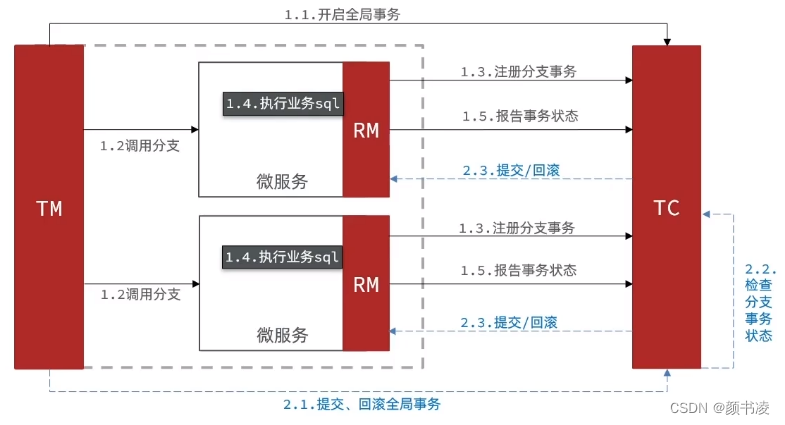
处理过程
TM-事务管理器
在需要开启全局事务的地方,加注解。
@GlobalTransactional(name="fsp-create-order",rollbackFor = Exception.class)分布式事务的执行流程
- TM 开启分布式事务,TM 会向 TC(seata服务器) 注册全局事务记录。
- RM 向 TC 汇报事务执行情况。
- TM 结束分布式事务,事务一阶段结束。TM 会通知 TC 提交、回滚分布式事务。
- TC 汇总各个系统的事务信息,决定分布式事务是整体提交还是整体回滚。
- TC 通知所有 RM 提交/回滚资源,事务二阶段结束。
Seata的四大模式
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式。
- SAGA模式:长事务模式,有业务侵入
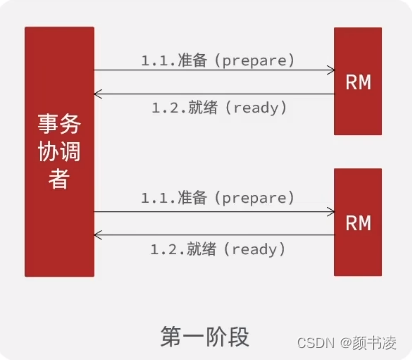
XA模式的2PC
- 一阶段执行本地事务,但是不提交,锁定资源。
- 二阶段根据一阶段本地事务执行结果,commit或者rollback。

实现
依赖于数据库的事务来实现。
缺点
因为一阶段需要锁定数据库资源,要等到二阶段结束才能释放,容易造成资源的浪费,性能较差,需要依赖关系型数据库实现事务。
AT模式的2PC
和XA类似都是二阶段提交,但是AT模式一阶段直接提交本地事务。不锁定资源,解决了XA模式锁定资源的问题。
二阶段采用反向补偿机制回滚事务。
Seata默认的分布式事务模式时AT。
一阶段
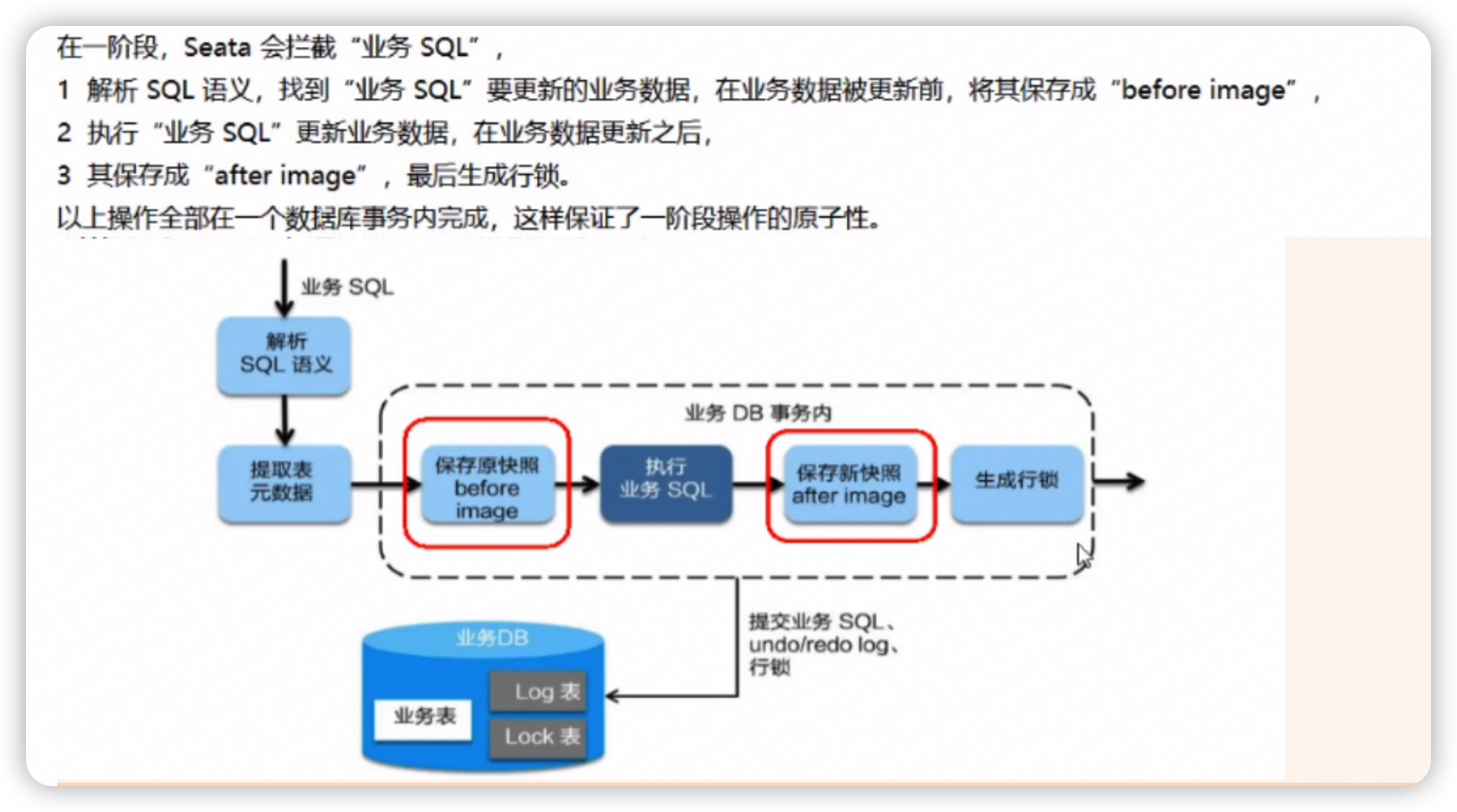
TC
seata 作为 TC (事务协调者),记录了 TM 开启分布式事务时,生成的全局事务ID - XID。
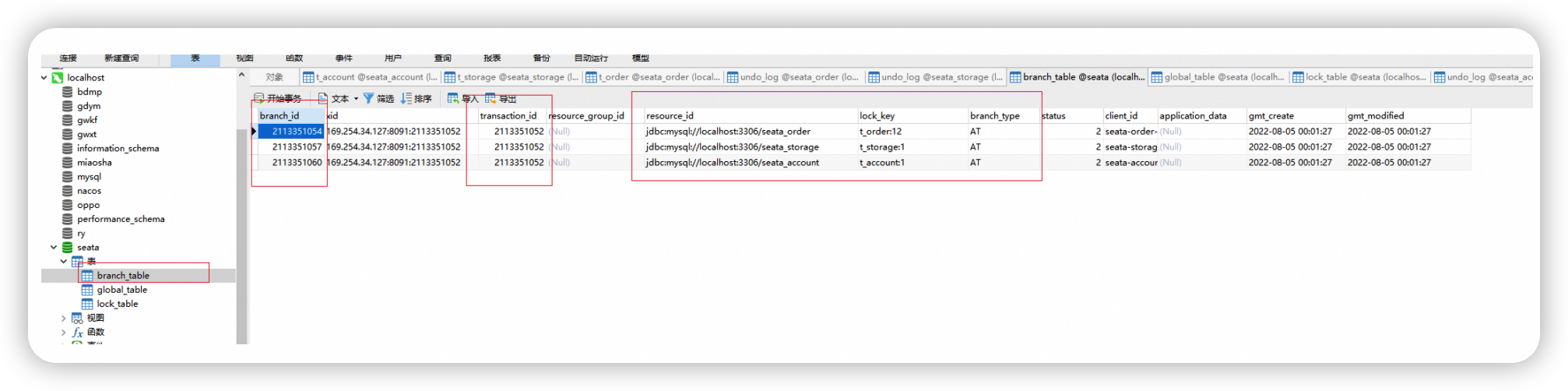
RM
每个分支的资源管理器对应数据库, 在 undo_log 中记录了对应分支的本地事务的信息。
包含全局事务ID - XID、分支ID、rollback_info。
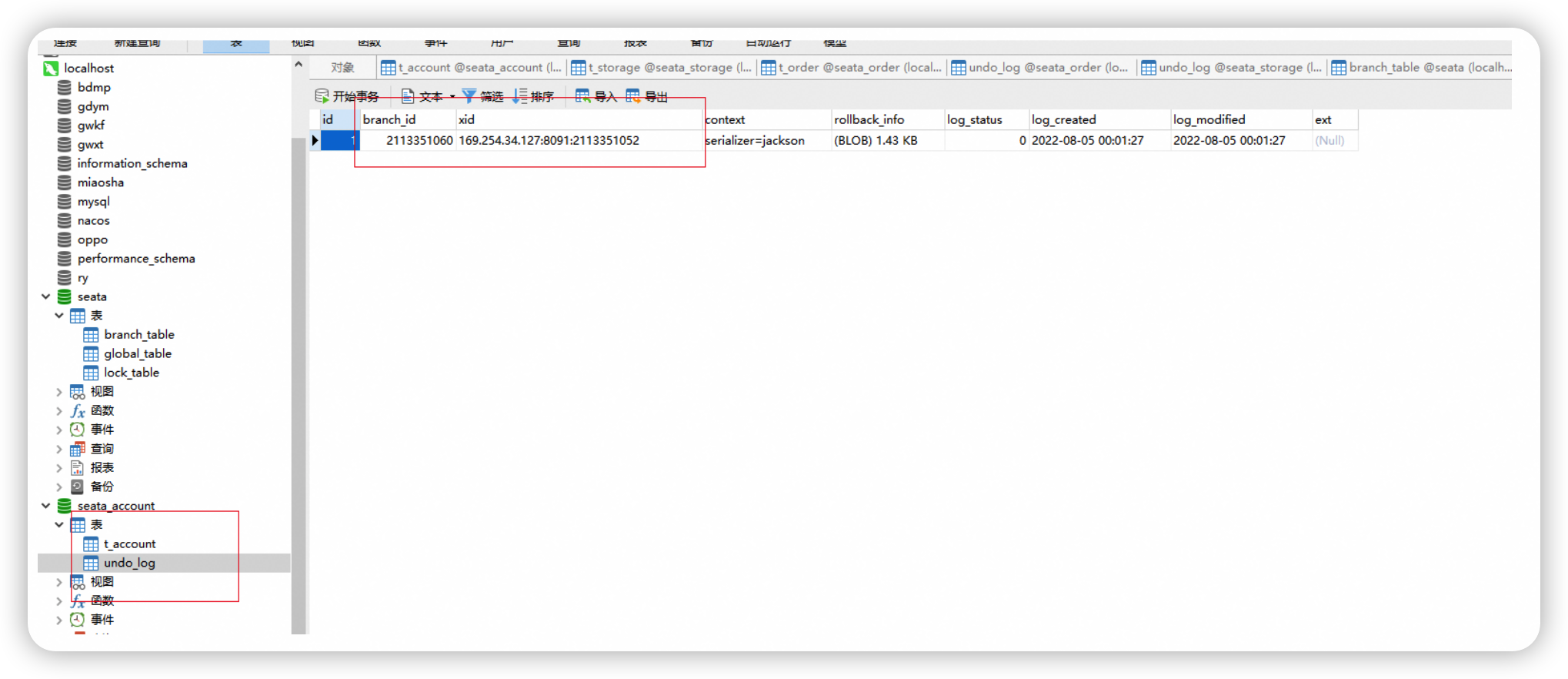
其中 rollback_info 中包含了一阶段事务中, 对应更新数据的 before_image 和 after_image 信息。
数据的 before_image 和 after_image 作用于二阶段的事务回滚。
二阶段
在一阶段中,每个分支的事务执行完毕,并向 TC 上报事务的执行结果。由 TC 根据结果决定全体提交还是全体回滚。
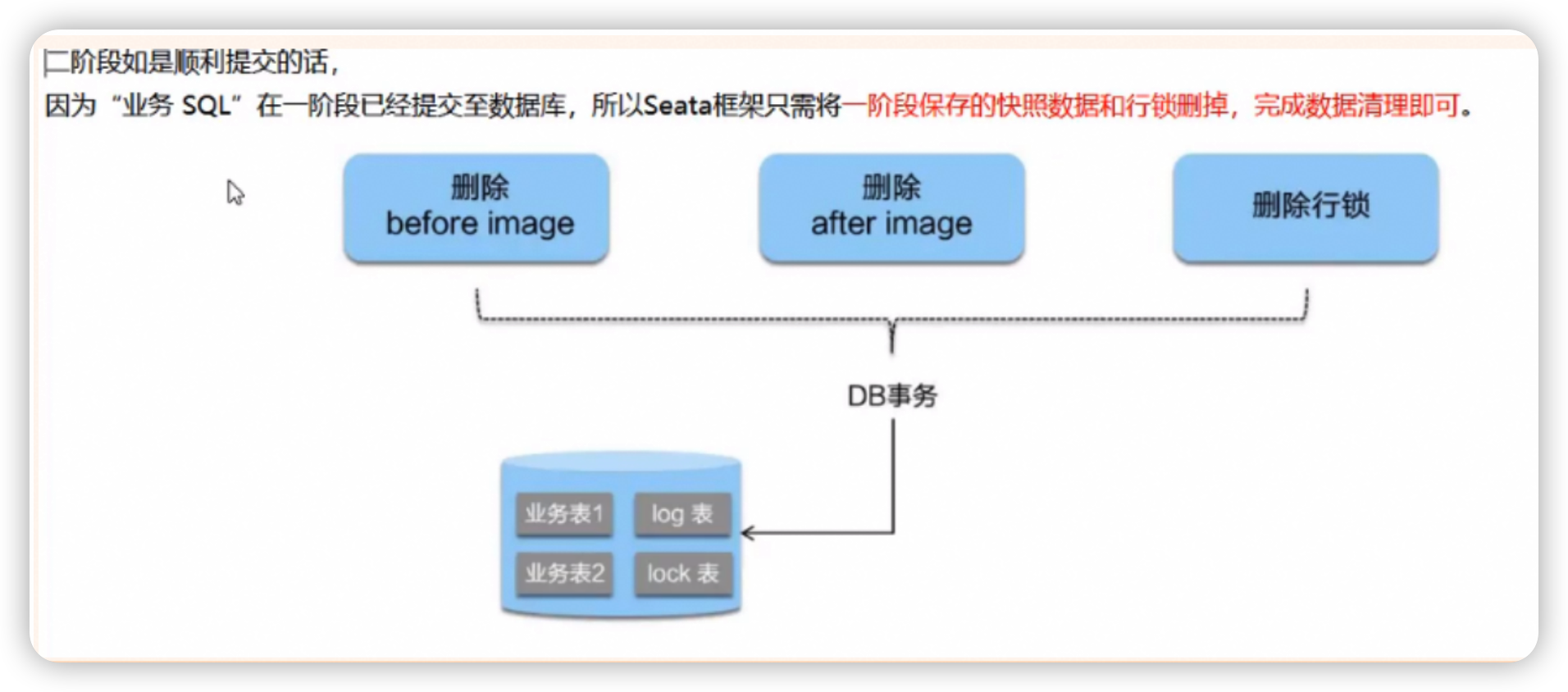
全体提交
在全体提交时,由于一阶段各个分支已经完成事务的提交,所以全体提交时只需要将一阶段保存的快照数据和行锁删除,完成数据清理就算全体事务提交成功。
全体回滚
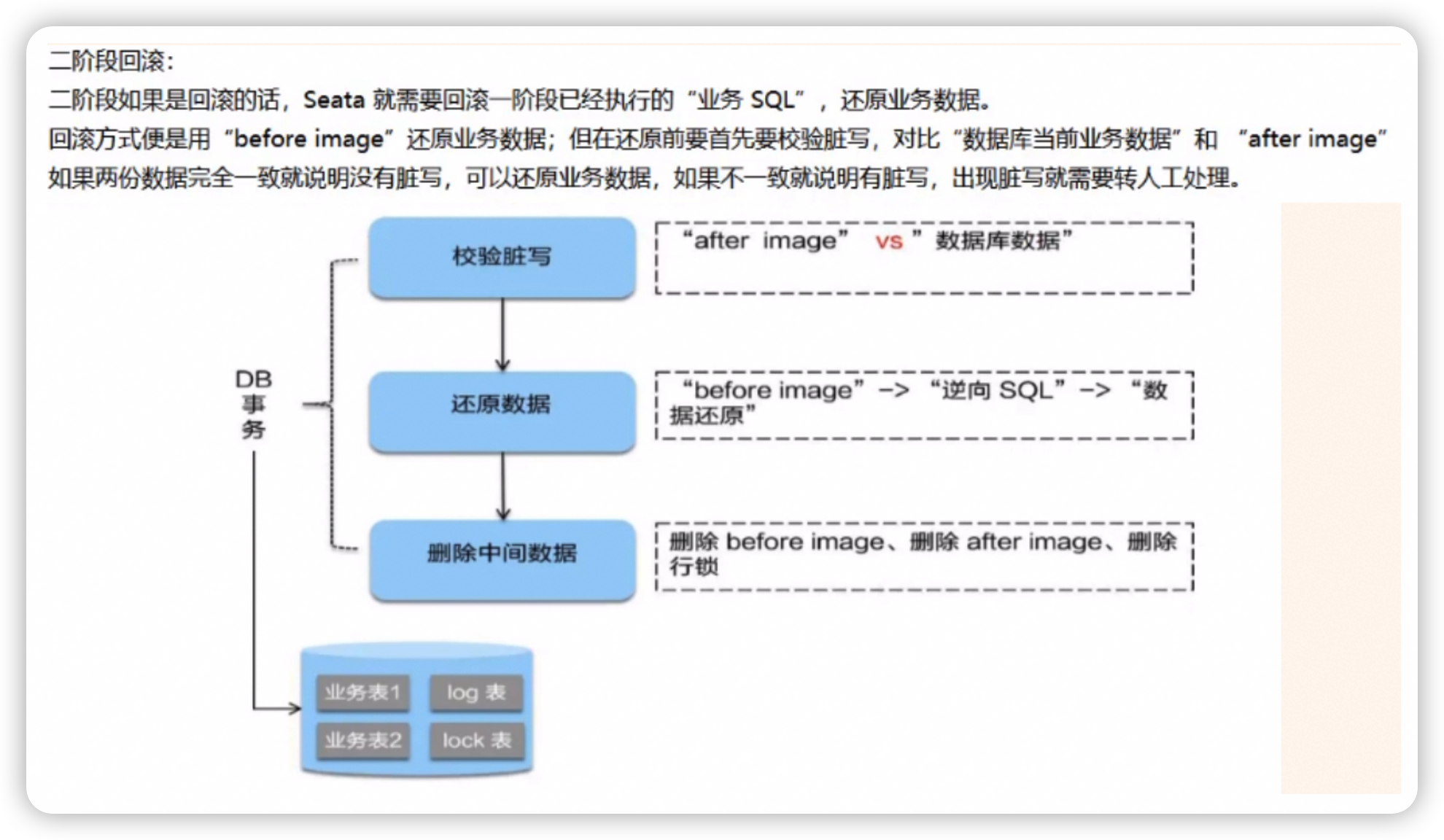
由于一阶段事务未全体执行成功,导致二阶段进行回滚。
各个分支回滚的方式是通过一阶段记录的
undo_log中记录的rollback_info数据进行回滚。其中包含了 before_image (更新前数据)和 after_image(更新后数据),其中用更新后数据来和数据库数据作校验,若一致说明数据正常,可以还原到更新前数据。
(类似于乐观锁)若数据库数据和 after_image(更新后数据),说明出现了脏数据(人工干预处理)。
疑问:在操作数据的时候,是加了行锁的,所以不应该出现脏数据的问题。
sqlupdate table set data = before_image where data = after_image注意更新的方式使用的是 反向补偿。不同于传统的 redo_log (重做日志刷新到磁盘)方式,反向补偿是通过一条 update 语句来实现数据的回滚的(确定回滚语句的主键,根据一阶段记录的 before_image 数据进行更新实现回滚)。
最终删除掉一阶段保存的快照信息和行锁即可。
使用流程
* Seata控制分布式事务
* 1)、每一个微服务先必须创建undo_log;
* 2)、安装事务协调器;seata-server: https://github.com/seata/seata/releases
* 3)、整合
* 1、导入依赖 spring-cloud-starter-alibaba-seata seata-all-1.0.0.jar
* 2、解压并启动seata-server
* registry.conf注册中心相关的配置,修改registry type=nacos
* file.conf
* 3、所有想要用到分布式事务的微服务使用seata DatasourceProxy代理自己的数据源
* 4、每个微服务,都必须导入registry.cof
* file.conf vgroup_mapping.{application.name}-fescar-service-group = "default"* 5、启动测试
* 6、给分布式大事务的路口标注@GlobalTransactional
* 7、每一个远程的小事务用 @TransactionalAT和XA的区别
- 一阶段事务提交
- AT模式一阶段直接提交事务,二阶段回滚依赖于反向补偿。
- XA模式一阶段不提交事务,锁定资源。二阶段按事务提交状况 commit 或 rollback。
AT和TCC的区别
AT 模式基于 支持本地 ACID 事务 的 关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
依赖数据库实现提交和回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
业务层面实现提交和回滚逻辑。
TCC模式
Tcc 是分布式事务中二阶段提交协议的实现,它的全称为 Tny-Confirm-Cancel , 即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel)。具体含义如下:
- Try(prepare)阶段:对业务资源的检查并预留。
- Confirm(commit)阶段:对业务处理进行提交,该步骤会对 Try 预留的资源进行释放,只要 Try 成功,Confirm 一定要能成功.
- Cancel(rollback)阶段:对业务处理进行取消,即回滚操作。
TCC如何控制异常
空回滚
在没有调用参与方的 try 方法情况下,二阶段调用参与方的 Cancel 方法。
在开启全局事务后,执行参与方的的 try 方法发生异常,导致一阶段未完成。在二阶段的时候全局事务失败调用 Cancel 方法,导致空回滚发生。
解决办法
Seata 增加了一个 TCC 事务记录表。
在 try 执行时插入一条记录,代表一阶段执行了。在二阶段的时候查询记录即可判断 try 方法是否执行过。
幂等性
二阶段的 commit 和 Cancel 需要保证幂等性。
比如在二阶段时,参与者 A 执行完,将结果发给 TC的时候,如果出现网络抖动等异常导致 TC 未接收到 A 的二阶段返回结果。TC 会发起重复调用,直到执行成功。
解决办法
在 TCC 事务记录表增加一个字段 status,这样在二阶段执行之后修改状态,后续根据状态判断即可解决幂等性问题。
- tried:1
- committed:2
- rollbacked:3
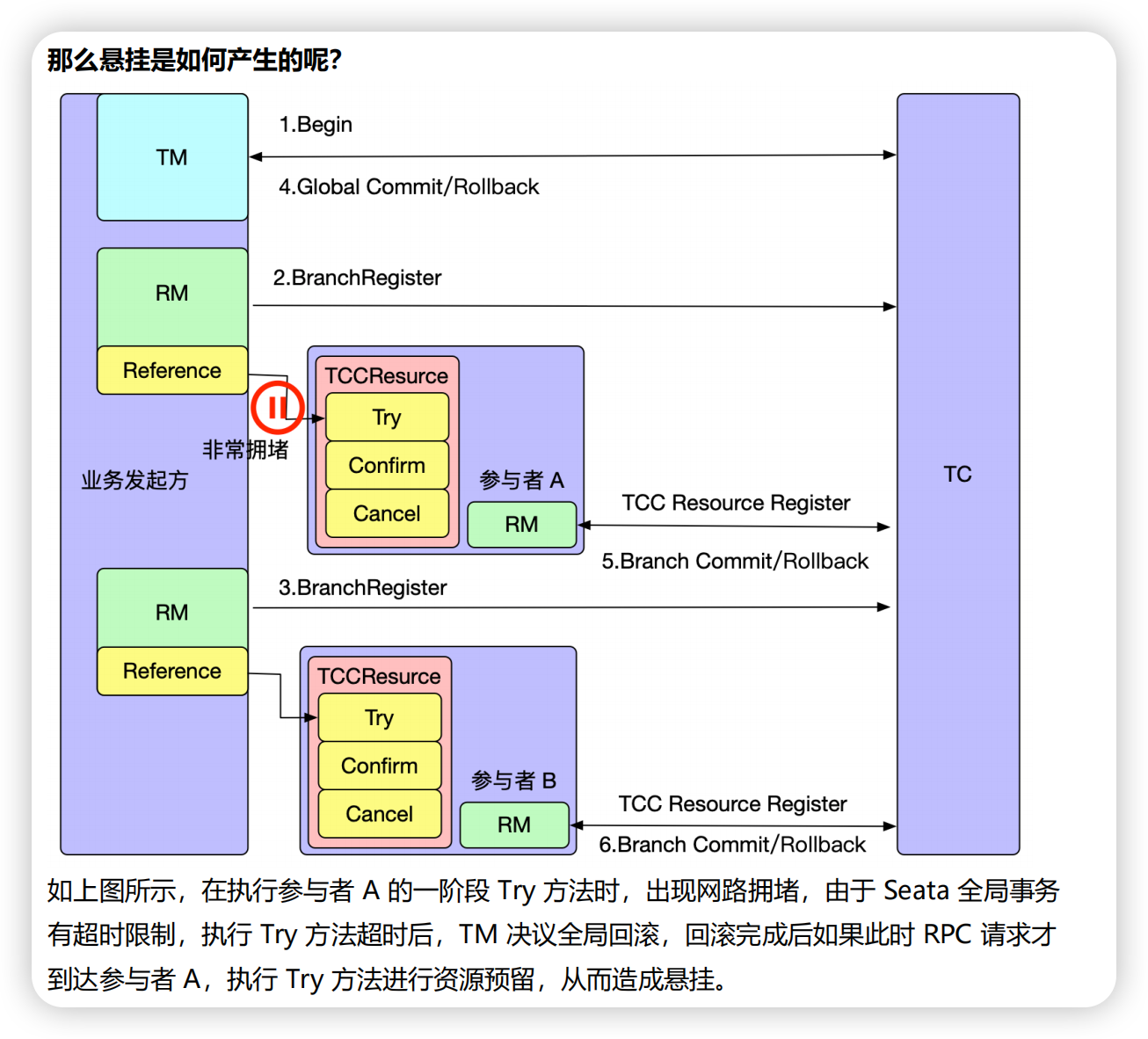
悬挂
悬挂指的是二阶段 Cannel 执行要比 一阶段 try 执行结束的早,全局事务结束。导致 try 方法预留的资源无法释放或提交。

Seata 怎么解决TCC模式的问题
TCC 幂等、悬挂和空回滚问题如何解决?
TCC 模式中存在的三大问题是幂等、悬挂、空回滚。
在 Seata1.5.1 版本中,增加了一张事务控制表,表名是 tcc_fence_log 来解决这个问题。
而在 @TwoPhaseBusinessAction 注解中提到的属性 useTCCFence 就是来指定是否开启这个机制,这个属性值默认是 false。
/zz引入 status = suspended,意为二阶段 cancel已经执行过,阻止一阶段的 try 方法执行。
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT 'status(tried:1;committed:2;rollbacke
d:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;缺点
- 如果参与者包含第三方公司接口,则无法控制事务补偿、重试、幂等等机制。
- 存在幂等、空回滚、悬挂等问题。
Saga模式
Saga 模式是 SEATA 提供的长事务解决方案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
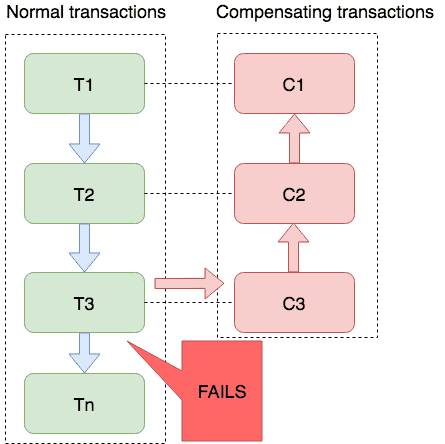
- 一阶段提交本地事务。
- 二阶段commit或者rollback。
全部执行成功,则commit。
如果当前事务执行失败,回滚当前事务包括之前已经成功的参与者。
通过反向补偿的逻辑(业务实现)来回滚事务。
适用场景
- 业务流程长、业务流程多
- 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口。
- 默认情况下很少使用,如果有跨公司的情况,为了保证强一致性可以使用Saga模式。