
ClickHouse高级
MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
建表语句
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine = MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);partition - 分区
分区的目的主要是降低扫描的范围,优化查询速度。
并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
分区目录
MergeTree 是以列文件 + 索引文件 + 表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
数据写入
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。
分区合并
写入后的某个时刻(大概 10-15 分钟后)ClickHouse 会自动执行合并操作(等不及也可以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
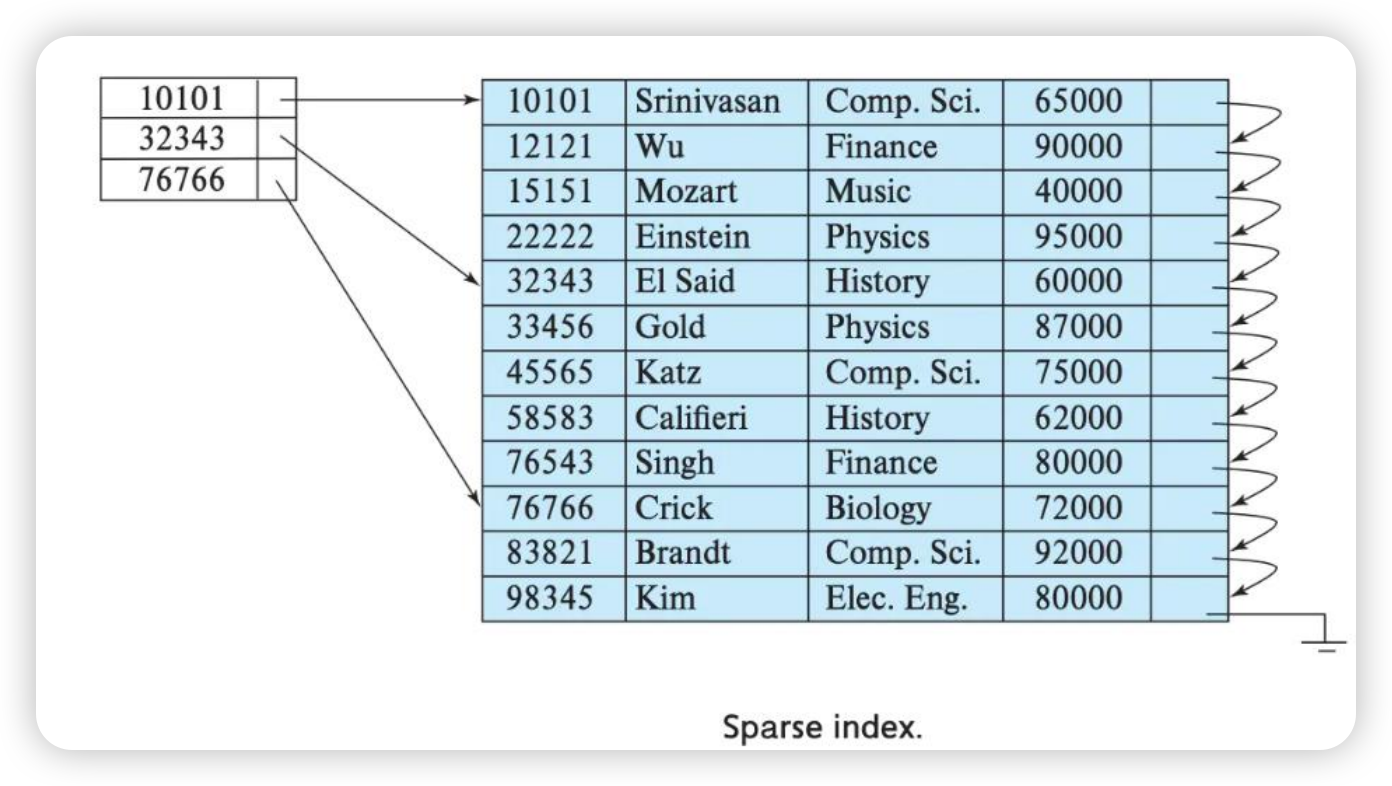
primary key - 主键
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对 主键进行某种形式的二分查找,能够定位到对应的 index granularity , 避免了全表扫描。(稀疏索引二分查找)
索引粒度 - index granularity
指在稀疏索引中两个相邻索引对应数据的间隔。
ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
order by - 必选
order by 设置了分区里面数据按照哪些字段有序保存,是 MergeTree 必填的。
如果没有设置主键,那么就会按照 order by 的前几个字段作为主键。
order by 前面的字段,必须按照主键的意义设置。
order by id,sku_id,name
//主键 必须是 id,或者 id,sku_idTTL
表级别 TTL
可以设置表数据按照某个字段过期,过期后数据会被删除。
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;ReplicatedMergeTree(
'/clickhouse/tables/eeeaebb1-3f5b-4d86-bcc5-e6feeb50babe/{shard}',
'{replica}'
)
PARTITION BY (toDate(ts), `0_masterip`)
PRIMARY KEY (toStartOfHour(ts), `0_masterip`, `0_ns`, `0_wkd_type`, `0_wkd`, `1_masterip`, `1_ns`, `1_wkd_type`, `1_wkd`)
ORDER BY (toStartOfHour(ts), `0_masterip`, `0_ns`, `0_wkd_type`, `0_wkd`, `1_masterip`, `1_ns`, `1_wkd_type`, `1_wkd`, ts)
TTL toDateTime(ts) + toIntervalDay(7)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1设置 TTL 根据 ts 的时间 7 天后过期(分区字段 ts)。
涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
ReplacingMergeTree
继承于 MergeTree,多了去重的功能。
Merge 虽然可以设置主键,但是主键不具备唯一约束的功能。可以通过 ReplacingMergeTree 实现去重。
去重机制
去重时机
在分区 Merge 的时候去重。
去重范围
如果表经过了分区,去重只能在单个分区里面进行。并不能跨分区去重。
所以 ReplacingMergeTree 并不能保证数据完全不重复,只是单个分区里面去重。
去重作用
ReplcaingMergeTree 并不能保证数据完全去重,只能减少分区的磁盘占用空间。
- 使用 order by 作为唯一键
- 去重不能跨分区
- 只有同一批插入的数据和合并的时候才会触发去重。
SQL 操作
删除操作
ClickHouse 的删除和更新操作比较重。
“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。
所以尽量做批量的变更,不要进行频繁小数据的操作。
Mutation 语句分两步执行,同步执行的。
- 进行新增数据新增分区
- 旧分区打上逻辑上的失效标记。
直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
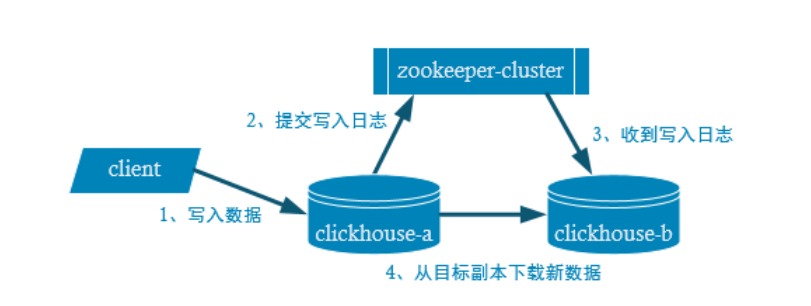
副本
副本的目的主要是保证数据的高可用性,即使一台节点宕机,通过其它节点副本也可以恢复数据。
副本写入流程
分片
引入分片将数据水平切分分布到多个节点上,再通过 Distributed 进行逻辑聚合。查询的时候就可以查到全量的数据了。
类似 es 的分片机制。
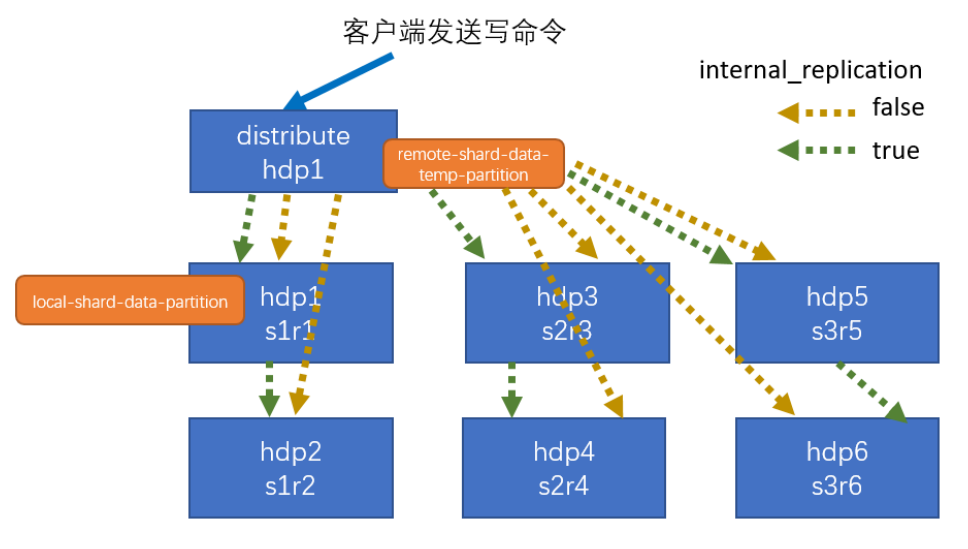
逻辑表引擎-Distributed
Distributed 表引擎本身不存储数据。
通过分布式逻辑表来写入、分发、路由来操作多个节点不同分片的分布式数据。
- 写入流程
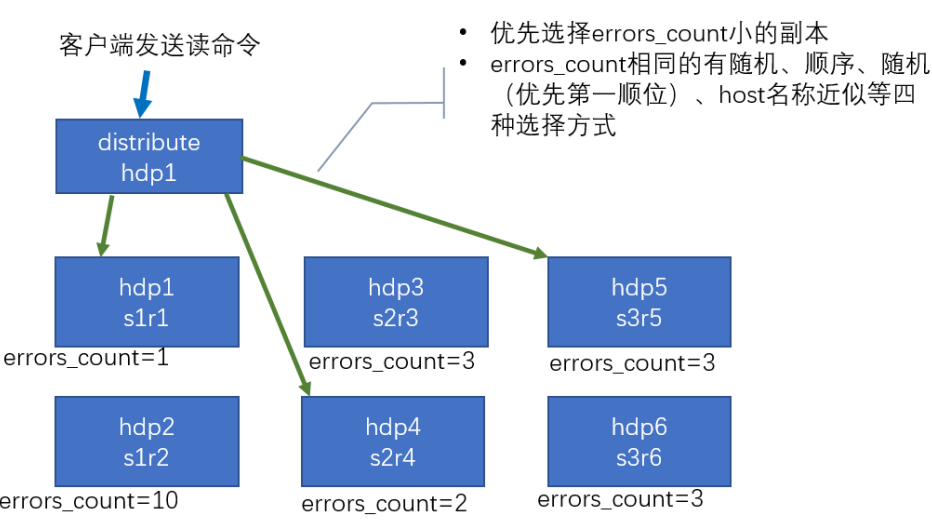
读取流程
由 distribute 发送读命令,发送读取命令到各个分片,选择 errors_count 小的副本。
表设计
entity 的 distributed 引擎设计
javaDistributed('{cluster}', 'ebpf', 'entity_detail_local', rand())ReplicatedMergeTree 表设计
sqlReplicatedMergeTree( '/clickhouse/tables/f1e4f1d1-cfb0-4a70-83b4-642702ec302e/{shard}', '{replica}' ) PARTITION BY (toDate(ts), masterip) PRIMARY KEY (toStartOfHour(ts), masterip, ns, wkd_type, wkd, pod) ORDER BY (toStartOfHour(ts), masterip, ns, wkd_type, wkd, pod, ts) TTL toDateTime(ts) + toIntervalDay(7) SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
联表查询-GLOBAL
两张分布式表的 IN 或者 JOIN 必须加上 GLOBAL 关键字。
- 如果加上,只会在分配到的节点上联表查询一次,并把查询结果发给其它节点。
- 如果不加上,每个节点都要联表查询一次。