
Kafka总控制器 Controller
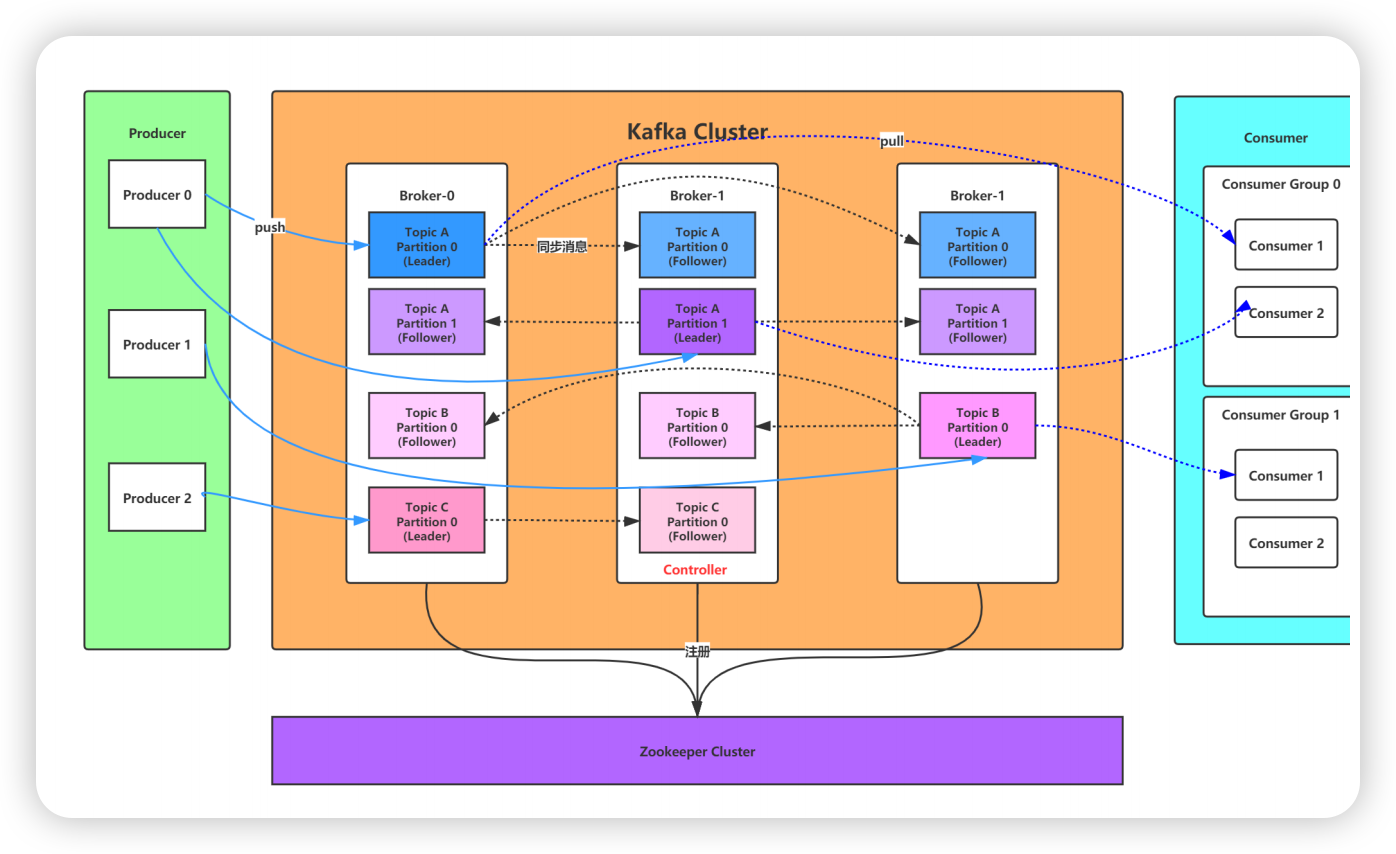
在 kafka中会有多个 Broker,其中一个 Broker 会被选举为 Controller,负责管理整个集群中分区和副本的状态。
Zookeeper
zk 使用的数据模型类似于文件系统的树形结构,根目录也是以“/”开始。该结构上的每个节点被称为 znode,用来保存一些元数据协调信息。
ZooKeeper 常被用来实现集群成员管理、分布式锁、领导者选举等功能。
znode 用来保存元数据信息。
永久性 znode
持久性 znode 不会因为 ZooKeeper 集群重启而消失。
临时性 znode
临时 znode 则与创建该 znode 的 ZooKeeper 会话绑定,一旦会话结束,该节点会被自动删除。
ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,抑或是 znode 所存的数据本身变更,ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端。
Controller选举机制
在 Kafka 启动的时候,所有 Broker 都会尝试在 zk 上面创建 /Controller 的临时节点,zk 会保证只有一个 Broker 创建成功。创建节点成功的 Broker 会成为集群的控制节点。
第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
故障转移
如果作为 Controller 的 Broker 挂掉了,这样与 zk 的会话就会结束,而之前在 zk 的/Controller下面创建的临时节点就会被删除。
而其它监听的 Broker 就会重新在 zk 建立节点,第一个成功创建的会成为新的 Controller。
控制器的功能
主题管理(创建、删除、增加分区)
比如执行 kafka-topics 脚本时,大部分工作是由Controller 完成的**。**
分区重新分配
kafka-reassign-partitions 脚本。
该脚本能够将指定 topic 的分区重新分配,比如平均分配到某个 Broker 上。
Preferred 领导者选举
避免 Broker 负载过重而提供的一种换 Leader 的方案。
集群成员管理(新增 Broker、删除 Broker、Borker 关闭或宕机)
自动检测集群内的 Broker,这种实现是依赖于 Broker 的 Watch 机制和zookeeper 的临时节点机制实现的。
Controller 会监听 zk 的/brokers/ids 节点下的子节点数量变更。
新增 Broker
有新Broker 产生时,zk 里面就会在 /brokers/ids 下新增一个 znode,同时就会被 watch 通知到 Controller。这样 Controller 就能感知到新Broker 的产生。
Broker 关闭或宕机(Broker 存活性)
借助于 zk 的临时节点,当 Broker新建时,就会在 zk 里面增加一个临时节点。当 Broker 关闭或宕机之后,该 Broker 与 zk 的会话结束。该 znode 作为临时节点随着会话结束而被删除,同时该变化会通过 Watch 机制通知到 Controller 节点。
元数据服务
Controller 会更新元数据,然后同步到其它 Broker。
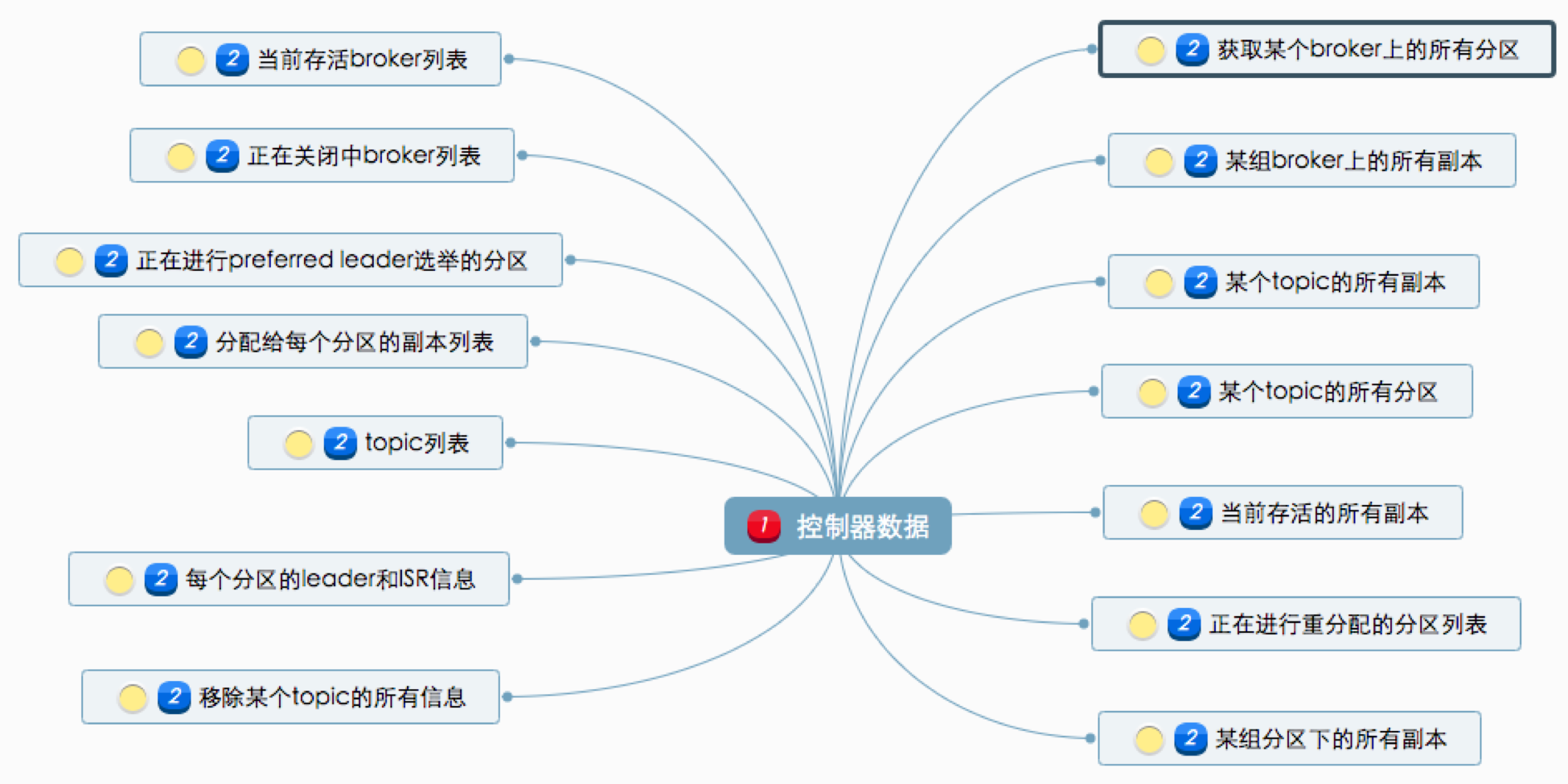
- 所有 Broker 信息。
- 所有 Topic 信息。
- 涉及运维任务的分区。
这些元数据在 zookeeper 上面也有一份,当 Controller 初始化的时候,会从 zk 请求元数据然后缓存起来。然后其它 Broker 就可以通过 Controller 访问元数据。