
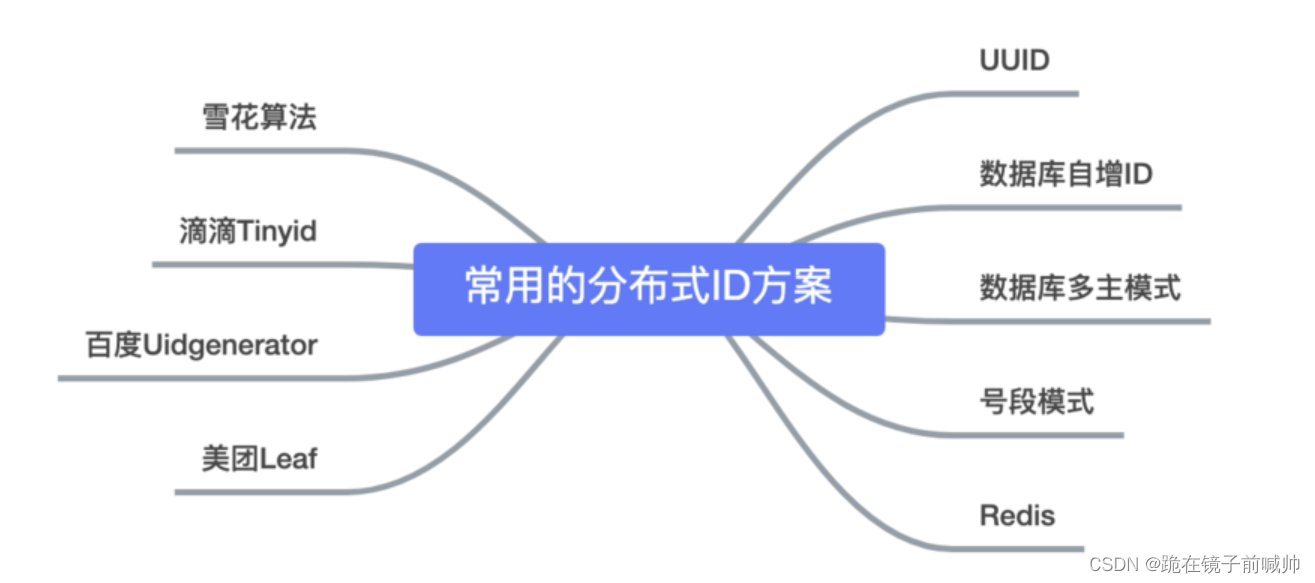
分布式ID
要求
- 分布式全局唯一
- 有序递增
方案
数据库主键自增
- 创建一个全局主键自增的表。
- 从该表查询id使用。
- 效率低下,每次插入之前都要查一次自己的id
数据库号段模式
批量从全局自增主键表获取一批主键,放到内存里。(减少数据库访问次数)
bash
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;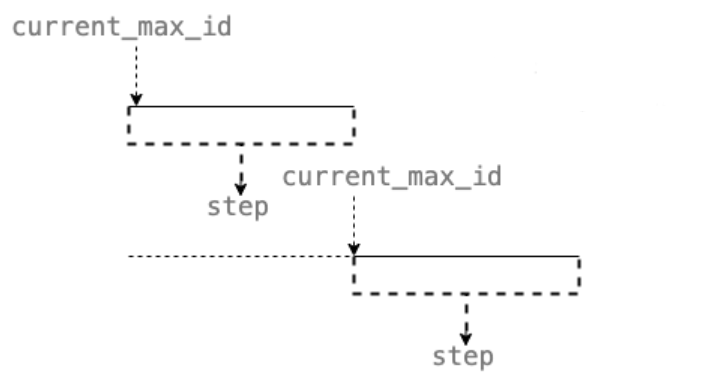
相比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小。另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
- 优点 :ID 有序递增、存储消耗空间小。
- 缺点 :存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )。
Redis ID
Redis分布式ID实现主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis单线程的特点,可以保证ID的唯一性和有序性。
这种实现方式,如果并发请求量上来后,就需要集群,不过集群后,又要和传统数据库一样,设置分段和步长。
- 优点:性能不错、每秒10万并发量。生成的 ID 是有序递增的。
- 缺点:redis 宕机后不可用,RDB重启数据丢失会重复ID。自增,数据量易暴露。
Snowflake(雪花算法)
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。
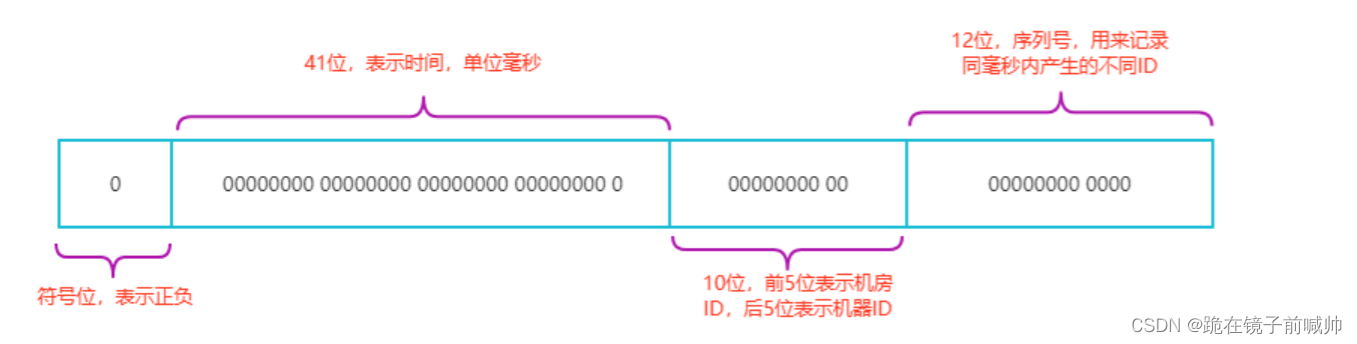
- 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
- 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截) 得到的值,这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69。
- 10位的数据机器位,可以部署在1024个节点,包括5位 datacenterId 和5位 workerId 。
- 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号。加起来刚好64位,为一个Long型。
- 优点: 雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,生成ID的效率非常高,稳定性好,可以根据自身业务特性分配bit位,比较灵活。
- 缺点: 每台机器的时钟不同,当时钟回拨可能会发生重复ID。当数据量大时,需要对ID取模分库分表,在跨毫秒时,序列号总是归0,会发生取模后分布不均衡。
雪花算法依赖于时间,如果时钟回拨就可能出现重复 id 问题。
java
public class SimpleIdGenerator {
private static final long EPOCH = 1609459200000L; // 2021-01-01 00:00:00
private static final long SEQUENCE_BITS = 12;
private long lastTimestamp = -1L;
private long sequence = 0L;
public synchronized long nextId() {
long currentTimestamp = timeGen();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨异常");
}
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & ((1 << SEQUENCE_BITS) - 1);
if (sequence == 0) {
currentTimestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - EPOCH) << SEQUENCE_BITS) | sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
}